主题和分区的概念
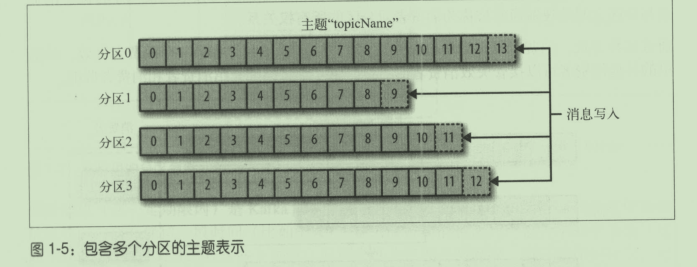
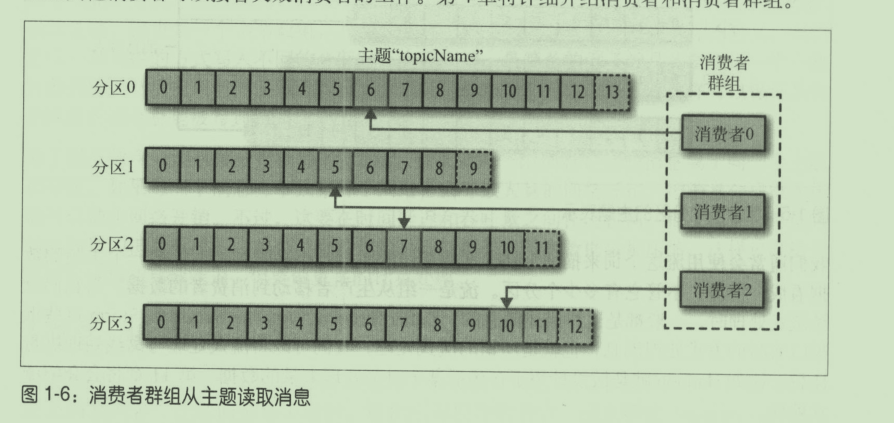
消费者消费数据
生产者
创建kafka生产者:
public class Main {
public static void main(String[] args) {
// 配置Producer属性 47.94.139.116:9092
Properties kafkaProperties = new Properties();
// fixme: 运行时请修改47.94.139.116:9092为自己的kafka broker地址
kafkaProperties.put("bootstrap.servers", "192.168.20.4:9092");
kafkaProperties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProperties.put("value.serializer", "cn.edu.neu.demo.ch3.avro.AvroCustomerSerializer");
kafkaProperties.put("acks", "all");
// 根据配置创建Kafka生产者
KafkaProducer<String, Customer> kafkaProducer = new KafkaProducer<>(kafkaProperties);
Customer customer = new Customer(1, "Tim");
// 创建ProducerRecord,它是一种消息的数据结构
ProducerRecord<String, Customer> producerRecord = new ProducerRecord<>(
"customer", "s1", customer);
// 发送消息
kafkaProducer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println(recordMetadata);
e.printStackTrace();
}
});
kafkaProducer.flush();
}
}
发送消息主要有以下的方式
1.发送并忘记
2.同步发送: 调用send然后返回一个Future对象
3.异步发送: 调用send方法并指定一个回调函数
生产者比较重要的参数
1.acks:指定必须要有多少个分区副本接收到消息,生产者才认为消息写入是成功的
acks=0: 表示不会接受服务器的任何回应
acks=1: 表示首领接收到后可以认为是接收成功
acks=all: 所有节点接收到消息才返回成功




序列化器
通用的序列化器有: Avro,Thrift,Protobuf
自定义序列化器
public class CustomerSerializer implements Serializer<Customer> {
public void configure(Map<String, ?> configs, boolean isKey) {
// 不需要配置任何
}
/**
* Customer对象的序列化函数,组成如下
* 前4字节: customerId
* 中间4字节: customerName字节数组长度
* 后面n字节: customerName字节数组
* */
public byte[] serialize(String topic, Customer data) {
try{
byte[] serializedName;
int stringSize;
if(data == null){
return null;
}else{
if(data.getCustomerName() != null){
serializedName = data.getCustomerName().getBytes("utf-8");
stringSize = serializedName.length;
} else{
serializedName = new byte[0];
stringSize = 0;
}
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + stringSize);
buffer.putInt(data.getCustomerId());
buffer.putInt(stringSize);
buffer.put(serializedName);
return buffer.array();
} catch(Exception e){
throw new SerializationException("Error when serializing Customer to byte[] " + e);
}
}
public byte[] serialize(String topic, Headers headers, Customer data) {
return serialize(topic, data);
}
public void close() {
// 不需要关闭任何
}
}
自定义序列化器的缺点就是不方便修改,兼容性比较差
Avro序列化器


分区
kafka的消息是一个个键值对,消息可以只有主题和值,但是一般会加上键
键可以作为消息的附加信息,用来决定消息应该路由到哪个分区,拥有相同键的消息会分到同一分区
如果键设置为空,则分区器使用轮询算法均匀发送消息到各个分区上
如果改变分区数量,则键与分区的映射会改变,所有最好在一开始就确定好分区的数量
自定义分区
public class MyPartitioner implements Partitioner{
public int partition(String topic, Object key, byte[] KeyBytes, Object value, byte[] ValueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic("java_topic");
int numPartitions = partitionInfos.size();
if ((KeyBytes==null)||(! (key instanceof String))){
throw new InvalidRecordException("we except all messages to have customer name as key");
}
if (((String)key).equals("melo")){
return numPartitions; //melo always go to the last partition
}
//other partition will get hashed to the rest of the partitions
return (Math.abs(Utils.murmur2(KeyBytes)) % (numPartitions - 1));
}
public void close() {
}
public void configure(Map<String, ?> map) {
}
}
消费者
尽量让消费者不要超过分区的数量,因为没什么用

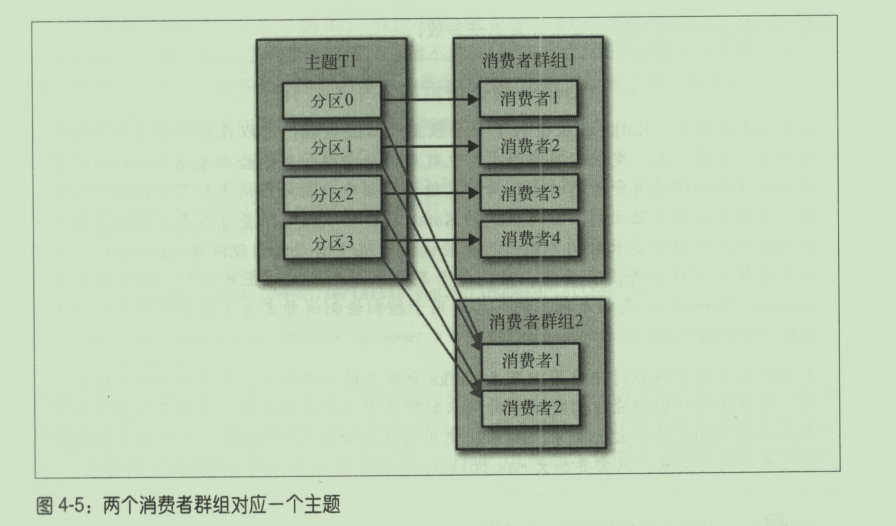
消费者群组: 群组里的消费者共同读取主题的分区
分区再均衡: 分区所有权从一个消费者转移到另外一个消费者,实现了高可用和伸缩性
群组协调器: 消费者通过向群组协调器发送心跳维持它们和群组的从属关系以及它们对分区的所有权关系

提交: 更新当前分区的位置




