1.linux查看cpu数目
https://www.cnblogs.com/emanlee/p/3587571.html,这个讲的非常详细了。
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 # 查看物理CPU个数 cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l # 查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo| grep "cpu cores"| uniq # 查看逻辑CPU的个数 cat /proc/cpuinfo| grep "processor"| wc -l
2. transformer的一个通用教程
我觉得也能从中学到内容吧,

每一个example都要经过长截短补,然后token转换为输入特征吧。
3.python csv模块
https://www.cnblogs.com/qican/p/11122206.html
import csv with open('eggs.csv', newline='') as csvfile: spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|') for row in spamreader: print(', '.join(row))
读取文件需要先open,然后reader那个open的文件对象,感觉不是很方便啊。写入的时候也比较麻烦,现在用的比较多的是pd.read_csv吧。
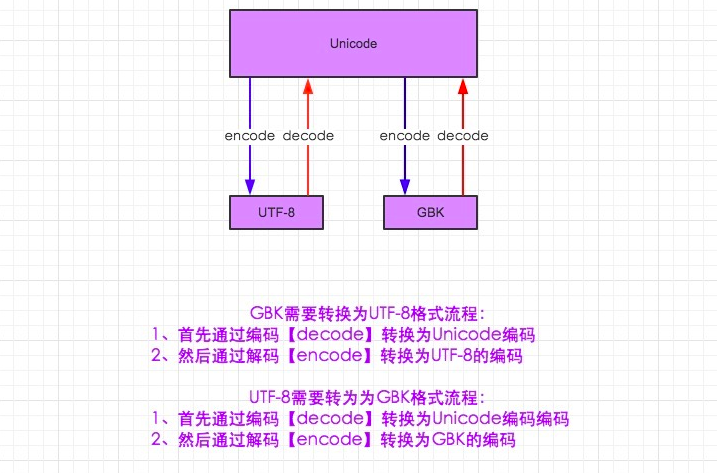
4.UTF-8 和 GBK 编码转换
5.sys.version_info
>>> sys.version_info sys.version_info(major=3, minor=7, micro=5, releaselevel='final', serial=0) >>> sys.version '3.7.5 (default, Oct 25 2019, 15:51:11) [GCC 7.3.0]'
可以发现上面的会输出python的版本号,比较详细,而下面的会输出一个总的python版本号,总之都是查看当前环境中的py版本的。
https://www.pythonheidong.com/blog/article/189983/
6.python multiprocessing模块
https://docs.python.org/zh-cn/3.7/library/multiprocessing.html#module-multiprocessing
from multiprocessing import Pool def f(x): return x*x if __name__ == '__main__': with Pool(5) as p: print(p.map(f, [1, 2, 3]))
这是一个简单的例子,它提供了一种方便的方法,可以跨多个输入值并行化函数的执行,跨进程分配输入数据(数据并行)。
//并行执行函数,跨进程分配数据。
Pool 类表示一个工作进程池。它具有允许以几种不同方式将任务分配到工作进程的方法。
可以看到上面map函数中,第一个参数为要并行处理的函数,第二个为输入函数的参数。
8.Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
https://github.com/NVIDIA/apex/issues/318,这里面有同样的问题,这个是关于fp16精度apex包的,
但是回答说:在训练开始时,随着标定值的校准,该消息可能会连续多次出现。所以就不必在意。
10.RuntimeError: cudnn RNN backward can only be called in training mode
https://blog.csdn.net/dongwanli666/article/details/103072635
https://discuss.pytorch.org/t/cudnn-rnn-backward-can-only-be-called-in-training-mode/37622/2
这两个回答都是说要调用model.train()回来,是ok的,可以解决。
11.wandb 包
https://www.cnpython.com/pypi/wandb,也是一个用来记录模型训练过程中的参数的包,并且可以上传到云端,通过浏览器多人访问?

import wandb # Your custom arguments defined here args = ... wandb.init(config=args, project="my-project") wandb.config["more"] = "custom" def training_loop(): while True: # Do some machine learning epoch, loss, val_loss = ... # Framework agnostic / custom metrics wandb.log({"epoch": epoch, "loss": loss, "val_loss": val_loss})
这样的话就可以记录一些实验变量,具体怎么使用我还没有在实验中用过。