事务的实现
事务隔离性由锁来实现。原子性、一致性、持久性通过数据库的redo log和undo log来完成。redo log称为重做日志,用来保证事务的原子性和持久性。undo log用来保证事务的一致性。
redo和undo作用都是一种恢复操作。
- redo:
- 恢复提交事务修改的页操作,
- 物理日志,记录的是页的物理修改操作。
- 保证事务的持久性
- 顺序写
- undo:
- 回滚行记录到某个特定版本
- 逻辑日志,根据每行进行记录
- 帮助事务回滚和MVCC功能
- 随机读写
redo
-
基本概念
重做日志用来实现事务的持久性,由两部分组成
- 内存中的重做日志缓冲
redo log buffer - 重做日志文件
redo log file
InnoDB是事务的存储引擎,其通过
Force Log at Commit机制来实现事务的持久性,即当事务提交时,必须将该事务的所有日志写入到重做日志文件进行持久化,该事务的COMMIT操作才算完成。这里的重做日志文件包括redo 和 undo log。
用户也可以手工设置COMMIT日志刷新策略,通过参数innodb_flush_log_at_trx_commit来控制。- 0:事务提交时不进行写入重做日志操作,这个操作仅在master thread中完成。
- 1:事务提交时必须调用一次fsync操作,默认值
- 2:事务提交时将重做日志写入重做日志文件,但只写入缓存,不进行fsync操作
- 内存中的重做日志缓冲
-
log block
在INNODB中,重做日志都是以512字节进行存储的,因为大小和磁盘扇区大小一样,因此重做日志的写入可以保证原子性。
-
log group
称为重做日志组,其中有多个重做日志文件,但是INNODB进行这个功能,实际上也只有一个log group。
是一个逻辑上的概念,由多个重做日志文件组成,每个log group中的日志文件大小是相同的。大小最大为512GB。
log buffer也是使用块进行存储的管理,同样为512字节。从缓存刷新到磁盘的具体规则为:
- 事务提交时
- 当log buffer已经有一半的内存空间被使用时
- log checkpoint时。
-
重做日志格式
INNODB的重做日志格式是基于页的。虽然有这边冉的重做日志格式,但是他们有着通用的头部格式。
redo_log_type space page_no redo log body - redo_log_type:重做日志类型
- space:表空间ID
- page_no:页偏移量
-
LSN
Log Sequence Number缩写,表示日志序列号。在INNODB存储引擎中,LSN占用8字节,并且单调递增,LSN表示含义有:
-
重做日志写入的总量
若当前重做日志的LSN为1000,一个事务写入了100字节的重做日志,那么LSN变为1100。
-
checkpoint的位置
-
页的版本
每个页的头部,有一个值
FILE_PAGE_LSN,记录该页的LSN。表示该页最后刷新时LSN的大小。用于判断页是否需要进行恢复操作。例如P1的LSN为10000,数据启动时,检测到重做日志文件中的LSN为13000,并且该事务已经提交,那么数据库就要对P1进行恢复操作。
-
恢复
不管运行时是否正常关闭,都会尝尽进行恢复操作。因为记录的都是物理日志,所以恢复速度比逻辑日志快很多。
undo
-
基本概念
进行回滚操作时使用。undo存放在数据库内部的一个特殊段中,成为undo段。位于共享表空间中。undo是逻辑日志,是将数据库逻辑地恢复到原来的样子。这是因为在多用户并发系统中,可能有成百上千个并发事务,如果直接物理回滚页记录,会影响其他正在进行的事务。
所以undo的回滚操作是逻辑操作,对于insert,进行对应的delete;对于delete,执行对象的Insert,对于update,进行反向的update。
undo的另外一个作用是MVCC,实现了非锁定读取。
undo log也会产生redo log。这是因为undo log也需要持久性的保护。
-
undo存储管理
采用段的方式进行管理,首先有
rollback segment,每个回滚段中记录了1024个undo log segment,而在每个undo log segment段中进行undo页的申请。 对
rollback segment做进一步的设置:-
innodb_undo_directory 用于设置文件所在的路径。即可以设置为独立表空间。该参数默认值为“.”,表示当前INNODB存储引擎的目录。
-
innodb_undo_logs 用来设置
rollback segment个数,默认值为128。 -
innodb_undo_tablespaces 设置构成
rollback segment文件的数量,这样rollback segment可以较为平均地分布在多个文件中。
SHOW VARIABLES LIKE 'innodb_undo%'; SHOW VARIABLES LIKE 'datadir'; 事务在
undo log segment分配页并写入undo log的这个过程同样需要写入重做日志。- 将
undo log放入列表中,以供之后的purge操作 - 判断
undo log所在的页是否可以重用,若可以分配给下个事务使用。
事务提交之后并不能马上删除undo log以及undo log所在的页,这是因为可能有MVVC使用。所以将undo log放在一个链表中,是否可以最终删除由purge线程判断。
-
-
undo log格式有两种:
-
insert undo log
在insert操作中产生的undo log。由于事务隔离性的要求,所以该undo log可以在事务提交后直接删除。不需要进行Purge操作。
-
update undo log
对delete和update操作产生的
undo log。改undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。
-
-
查看undo 信息
# 查看rollback segment DESC INNODB_TRX_ROLLBACK_SEGMENT; # 查看rollback segment所在的页 SELECT segment_id, space, page_no from INNODB_TRX_ROLLBACK_SEGMENT; # 记录事务对应的undo log SELECT * FROM information_schema.INNODB_TRX_UNDOG;
purge
delete和update操作可能并不直接删除原有的数据,undo log只将对应记录的delete flag设置为1,没有直接删除记录,真正删除的操作被延时到purge操作中完成。
因为MVVC的关系,purge要等待该行记录已经不被任何其他事务引用,才进行清理操作。
INNODB存储引擎中含有一个history list,按照事务提交的顺序将undo log进行组织。在执行purge的过程中,INNODB存储引擎首先从history list中找到第一个需要被清理的记录,清理之后,会继续在该记录所在的undo log页中继续寻找可以被清除的记录,然后再继续从history list中去查找,重复执行。
参数innodb_purge_batch_size用来设置每次Purge操作需要清理的undo page数量。
参数innodb_max_purge_lag用来控制history list的长度,若长度大于该参数时,其会“延缓”DML的操作。默认为0,表示不做任何限制。当大于0时,就会延缓DML的操作,延缓的算法为:
delay = ((length(history_list) - innodb_max_purge_lag) * 10) - 5
单位是毫秒。delay的对象是行,而不是DML操作。
参数innodb_max_purge_lag_delay,用来控制delay的最大毫秒数。当上述计算的delay数值大于该参数值,限制住。
group commit
若事务为非只读事务,则每次提交都要进行依次fsync操作,以此保证重做日志都已经写入磁盘。为了提高磁盘fsync效率,提供了group commit功能,依次fsync可以刷新确保多个事务日志被写入文件。
但是在开启了二进制日志之后,为保证存储引擎层中的事务和二进制日志的一致性,二者之间使用了两阶段事务,步骤如下:
- 当事务提交时InnoDB存储引擎进行prepare操作
- MYSQL数据上层写入二进制日志
- INNODB存储引擎层将日志写入重做日志文件
- 修改内存中事务对应的信息,并且将日志写入重做日志缓冲
- 调用fsync将确保日志都从重做日志缓冲写入磁盘。
一旦写入了二进制日志,就确保了事务的提交,即使执行步骤3发生了宕机。此外,每个步骤都需要进行依次fsync才能保证上下两层数据一致。步骤二由sync_binlog控制,步骤三由innodb_flush_log_at_trx_commit控制。
因为备份以及恢复的需要,需要保证MYSQL数据库上层二进制日志的写入顺序和INNODB层的事务提交顺序一致,MYSQL数据库内部使用了prepare_commit_mutex这个锁。但是启用这个锁之后,步骤3中的步骤1不可以再其他事务执行步骤二时执行。从而导致group commit失效。
为了解决这个问题,5.6版本之后使用了BLGC技术。
在MYSQL数据库上层进行提交时先按照顺序将其放入一个队列中,队列中的第一个事务成为leader,其他事务成为follower,leader控制follower的行为。BLGC的步骤分为以下三个阶段:
Flush阶段:将每个事务的二进制日志写入内存。Sync阶段:将内存中的二进制日志刷新到磁盘,若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的写入,这就是BLGC。Commit阶段,leader根据顺序调用存储引擎层事务的提交,InnoDB存储引擎本就支持Group commit,所以就解决了gourp commit失效的问题。
当一组事务在进行commit阶段时,其他新事务可以进行Flush阶段,从而使group commit不断生效。group commit的效果由队列中书屋的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多,甚至会更差。但当提交的事务越多时,group commit的效果越明显,数据库性能的提升也就越大。
参数binlog_max_flush_queue_time用来控制Flush阶段中等待的时间,即使之前的一组事务完成提交,当前一组的事务也不马上进入Sync阶段,而是至少需要等待一段时间。这个好处是group commit数量更多,该参数默认值为0,推荐这是依旧为0。
事务控制语句
START TRANSACTION | BEGIN:显式地开启一个事务COMMIT:提交事务ROLLBACK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改SAVEPOINT identifier:允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT。RELEASE SAVEPOINT identifier:删除一个事务的保存点,当没有一个保存点执行这句语句时,会抛出一个异常。ROLLBACK TO [SAVEPOINT] identifier:与SAVEPOINT命令一起使用,可以把事务回滚到标记点,而不会管在此标记点之前的任何工作。SET TRANSACTION:用来设置事务的隔离级别READ UNCOMMITTEDREAD COMMITTEDREPEATABLE READSERIALIZABLE
COMMIT WORK用来控制事务结束后的行为是CHAIN还是RELEASE。如果是CHAIN方式,那么事务就变成了链事务。
通过参数completion_type来控制
- 该参数默认为0,表示没有任何操作,这时和
COMMIT是完全等价的 - 设置为1,等同于
COMMIT AND CHAIN,表示马上自动开启一个相同隔离级别的事务。 - 设置为2 ,等同于
COMMIT AND RELEASE,表示事务提交之后会自动断开与服务器的连接。
对于事务操作的统计
-
QPS
Question Per Second:每秒请求数 -
TPS
Transaction Per Second:每秒事务处理能力计算TPS的方法是(com_commit + com_rollback) / time。计算前提是所有事务必须是显式提交的。
事务的隔离级别
SQL标准定义的四个隔离级别为:
READ UNCOMMITTED:浏览访问READ COMMITED:游标稳定REPEATABLE READ:是2.9999°的隔离,没有幻读的保护。SERIALIZABLE:称为隔离,或者3°的隔离。
MYSQL引擎默认支持的隔离级别是REPEATABLE READ,但是已经通过Next-Key Lock锁的算法,避免了幻读产生。达到SQL标准的SERIALIZABLE隔离界别。
隔离级别越低,事务请求的锁越少或者保持锁的时间就越短。默认的事务隔离级别是READ COMMITTED。
修改MYSQL启动时设置的默认隔离级别,需要修改MYSQL的配置文件
[mysqld]
transaction-isolation = READ-COMMITTED
如何查看事务隔离级别
# 当前会话的事务隔离级别
SELECT @@tx_isolationG;
# 全局的事务隔离级别
SELECT @@global.tx_isolationG;
主从复制如果发生了不一致,可能发生的原因有两点:
- 在
READ COMMITTED事务隔离级别下,事务没有使用gap lock进行锁定,因此用户在会话B中可以在小于等于5的范围内插入一条记录。 STATEMENT格式记录的是master上产生的SQL语句,因此在master服务器上执行的顺序为先删后插,但是STATEMENT格式记录的确实先插后删。逻辑顺序上产生了不一致。
分布式事务
MYSQL数据库分布式事务
INNODB存储引擎提供了对XA事务的支持,并通过XA事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源参与到一个全局的事务中。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚。
INNODB存储引擎的事务隔离级别必须设置为SERIALIZABLE。
XA事务允许不同数据库之前的分布式事务。分布式事务可能在银行的转账系统中比较常见。
XA事务由一个或多个资源管理器、一个事务管理器以及一个应用程序组成。
- 资源管理器:提供访问事务资源的方法。通常一个数据库就是一个资源管理器
- 事务管理器:协调参与全局事务中的各个事务。需要和参与全局事务的所有资源管理器进行通信。
- 应用程序:定义事务的边界,指定全局事务中的操作。
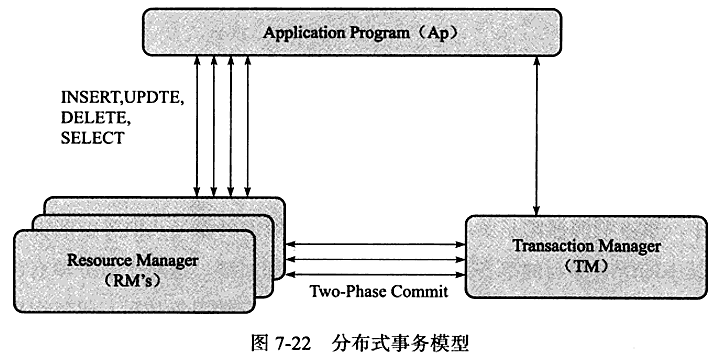
分布式事务采用二段式提交的方式。
- 在第一阶段,所有参与全局事务的节点都开始准备,告诉事务管理器他们准备好提交了。
- 在第二阶段,事务管理器告诉资源管理器执行
ROLLBACK还是COMMIT。如果任何一个节点显示不能提交,则所有的节点都被告知需要回滚。
MYSQL数据库XA事务的SQL语法如下:
XA {START|BEGIN} xid {JOIN|RESUME}
XA END xid[SUSPEND [FOR MIGRATE]]
XA PREPARE xid
XA COMMIT Xid [ONE PHASE]
XA ROLLBACK xid
XA RECOVER
但是一般来说,单个节点上运行分布式事务没有实际意义,一般和变成语言来完成分布式事务的操作。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
class MyXid implements Xid {
public int formatId;
public byte gtrid[];
public byte bqual[];
}
public class xa_demo {
public static MysqlXADataSource GetDataSource(String conString, String user, String passwd) {
try {
MysqlXADataSource ds = new MysqlXADataSource();
ds.setUrl(connString);
ds.setUser(user);
ds.setPassword(passwd);
return ds;
}
catch(Exception e) {
System.out.println(e.toString());
return null;
}
}
}
public static void main() {
String connString1 = "jdbc:mysql://192.168.24.43:3306/bank_shanghai";
String connString2 = "jdbc:mysql://192.168.24.44:3306/bank_beijing";
try {
MysqlXDataSource ds1 = GetDataSource(connString1, "mxr", "12345");
MysqlXDataSource ds2 = GetDataSource(connString2, "cxw", "12345");
XAConnection xaConn1 = ds1.getXAConnect();
XAResource xaRes1 = xaConn1.getXAResource();
Connection conn1 = xaConn1.getConnection();
Statement stmt1 = conn1.createStatement();
XAConnection xaConn2 = ds2.getXAConnect();
XAResource xaRes2 = xaConn2.getXAResource();
Connection conn2 = xaConn2.getConnection();
Statement stmt2 = conn2.createStatement();
Xid xid1 = new MyXid(100, new byte[]{0x01}, new byte[]{0x02});
Xid xid2 = new MyXid(100, new byte[]{0x11}, new byte[]{0x12});
try {
xaRes1.start(xid1, XAResource.TMNOFLAGS);
stmt1.execute("UPDATE account SET money = money - 10000 where user = 'mxr'");
xaRes1.end(xid1, XAResource.TMSUCCESS);
xaRes2.start(xid2, XAResource.TMNOFLAGS);
stmt2.execute("UPDATE account SET money = money + 10000 where user = 'cxw'");
xaRes2.end(xid2, XAResource.TMSUCCESS);
int ret2 = xaRes2.prepare(xid2);
int ret1 = xaRes2.prepare(xid1);
if( ret1 = XAResource.XA_OK && ret2 = XAResource.XA_OK) {
xaRes1.commit(xid1, false);
xaRes2.commit(xid2, false);
}
}
catch(Exception e) {
e.printStackTrace();
}
}
catch(Exception e) {
System.out.println(e.toString());
}
}
通过参数innodb_support_xa可以查看是否启用了XA事务的支持(默认为ON);
内部XA事务
在MYSQL内,存储引擎与插件之间,存储引擎之间也存在一种分布式事务,成为内部XA事务。
最常见的是binlog与INNODB存储引擎之间内部XA事务。binlog和存储引擎的重做日志必须同时写入,保证原子性,否则会导致主备数据不一致。
不好的事务习惯
在循环中提交
CREATE PROCEDURE load(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a', 80);
WHILE S <= count DO
INSERT INTO t1 SELECT NULL, c;
SET S = S + 1;
END WHILE;
END;
每次的insert都会发生自动提交,如果用户插入10000条数据,在5000条是发生了错误,那这5000已存在的数据如何处理?
如果每次都提交,每次都需要写重做日志,影响效率。
所以建议使用同一个事务
CREATE PROCEDURE load(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a', 80);
START TRANSACTION;
WHILE S <= count DO
INSERT INTO t1 SELECT NULL, c;
SET S = S + 1;
END WHILE;
COMMIT;
END;
使用自动提交
编写应用程序开发时,最好把事务的控制权限交给开发人员,在程序端进行事务的开始和结束。
使用自动回滚
使用自动回滚之后,MYSQL在程序段是不会抛出异常信息的,不便于调试,所以一般存储过程中值存放逻辑操作即可。管理操作全部放在java中进行。
长事务
长事务:执行时间较长的事务。
这边一般会将长事务拆解为多个小事务进行操作。这样子,如果发生是失败了,可以继续在失败的小事务上继续进行重试,而不用全部重试。节省时间。