0 - 背景
Facebook AI Research(FAIR)开源了一项将2D的RGB图像的所有人体像素实时映射到3D模型的技术(DensePose)。支持户外和穿着宽松衣服的对象识别,支持多人同时识别,并且实时性良好。
本研究的目的是通过建立从人体的2D图像到基于表面的3D表征的密集对应(dense correspondence)来进一步推进机器对图像的理解。该任务涉及到其他一些问题,如物体检测、姿态估计、作为特例或前提的部位和实例分割。在图形处理、增强现实或者人机交互等不只需要平面关键特征位置标记的问题中,这一任务的解决将能够实现很多应用,并还能助力实现通用型的基于3D的物体理解。
1 - 贡献
- 通过收集SMPL模型和COCO数据集中的人体外观之间的密对应对应而为该任务引入第一个人工收集的真实数据集(利用3D表面信息的全新标注流程实现)
- 通过在任何图像像素对人体表面坐标进行回归,我们使用所得到的数据集训练了可以得到自然环境中密集对应的基于CNN的系统(全卷积网络、mask R-CNN、级联)
- 我们探索了利用我们构建的真实信息的不同方法,我们使用了在每个训练样本中随机选择的图像像素子集上定义的稀疏监督信号来训练一个教师网络(“teacher”),可以修补图像其余区域的监督信号
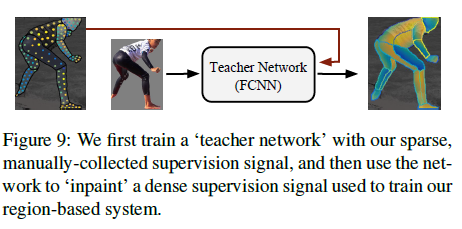
2 - 思路
采用一种全面的监督学习方法并收集了人体的图像与详细准确的参数表面模型之间的真实对应数据。
2.1 - 标注数据集
对于一般的姿态识别(骨骼追踪),能够识别出一二十个点便可以构成一个人体姿态,但如果要构造出一个平滑的3D模型,则需要更多的关键点,DensePose需要336个(24个部位,每个部位14个点)。
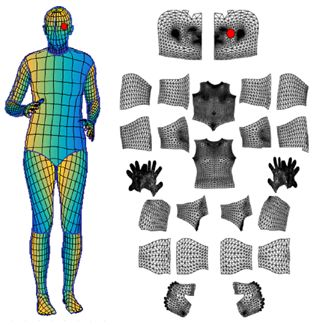


同时要求注释者在标记的时候要标出被衣物掩盖住的部位,比如宽松的裙子。

上述工作进行之后,研究人员对每一个展开部位区域进行采样,会获得6个不同视角的标记图,提供二维坐标图使标记者更直观的判断哪个标记是正确的。

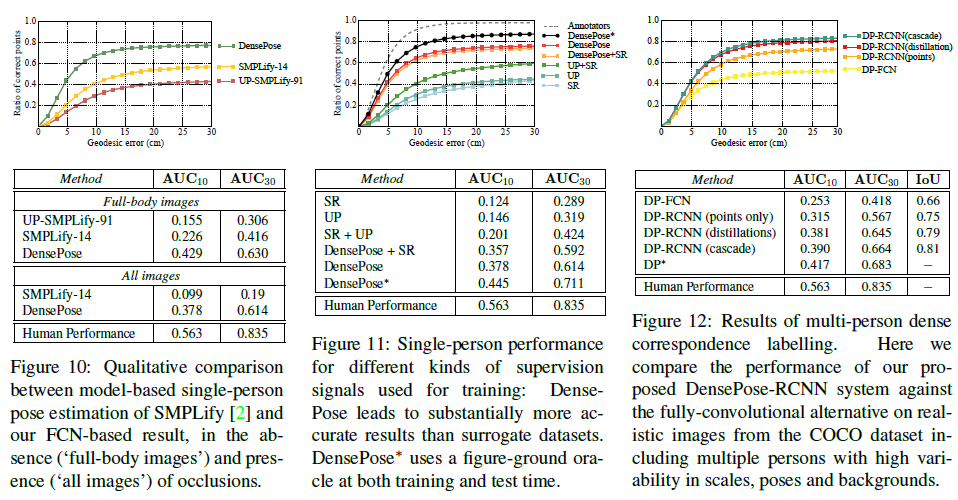
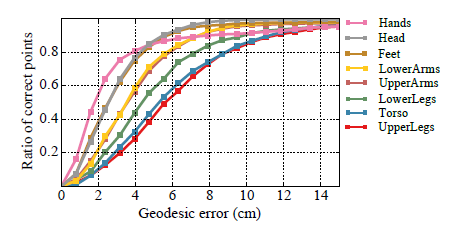
最后将平面重新组合成3D模型,进行最后一步校准。这样下来,可以以高效准确的方式获得准确标记的数据集。各部位错误率如下,可以看到在躯干、背部和臀部存在较大误差。
2.2 - 模型
2.2.1 - Fully-convolutional dense pose regression

2.2.2 - Region-based Dense Pose Regression
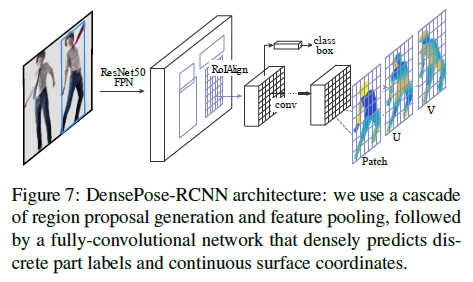

2.3 - 效果