一、分类数据的概念
1、什么是分类数据
分类数据(Category Data)是指Pandas数据类型为分类类型的数据
分类数据是由固定的且数量有限的变量组成,通常是字符串。例如:
-
- 性别:男、女
- 血型:A型、B型、C型
- 国家:中国、美国、德国
分类数据可以设置逻辑顺序,如:高 > 中 > 低
>>> df = pd.read_excel('C:/Users/xhl/Desktop/input/class.xlsx')
>>> df
class sex score_math score_music
0 A male 95 79
1 A female 96 90
2 B female 85 85
3 C male 93 92
4 B female 84 90
5 B male 88 70
6 C male 59 89
7 A male 88 86
8 B male 89 74
>>> df.dtypes
class object
sex object
score_math int64
score_music int64
dtype: object
使用astype()将性别转换成分类类型
>>> df['sex'].astype('category')
0 male
1 female
2 female
3 male
4 female
5 male
6 male
7 male
8 male
Name: sex, dtype: category
Categories (2, object): [female, male]
2、分类数据的values
分类数据的values值是一个pandas.Categorical对象,而不再是Numpy对象
#未分类时
>>> type(df['sex'].values)
<class 'numpy.ndarray'>
#分类后
>>> type(df['sex'].astype('category').values)
<class 'pandas.core.arrays.categorical.Categorical'>
3、分类数据的属性
包括类别(categories)和编码(codes)两个属性;
分类数据将一个类别映射到一个整数上,其内部数据结构有一个类别数组和一个整数数组构成
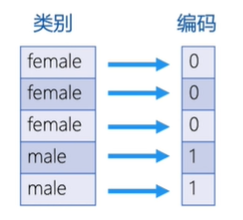
>>> sex_cate = df['sex'].astype('category')
>>> sex_cate.values
[male, female, female, male, female, male, male, male, male]
Categories (2, object): [female, male]
#查看类别
>>> sex_cate.values.categories
Index(['female', 'male'], dtype='object')
查看编码
>>> sex_cate.values.codes
array([1, 0, 0, 1, 0, 1, 1, 1, 1], dtype=int8)
4、使用分类数据的好处
分类数据通过将类别进行数字编码,可以大大节省内存的占用,提高运行速度,可使用memory_usage()检验
5、为何使用分类数据?
分类数据可以指定逻辑顺序,并能够进行逻辑顺序上的排序和筛选最大/最小值的操作
使用Series.cat.as_ordered()可设置逻辑顺序,但并没有什么实际含义,并不怎么常用
>>> df['class'].astype('category').cat.as_ordered()
0 A
1 A
2 B
3 C
4 B
5 B
6 C
7 A
8 B
Name: class, dtype: category
Categories (3, object): [A < B < C]
使用Series.cat.set_categories()自定义逻辑顺序,有实际含义
>>> df['class'].astype('category').cat.set_categories(["C","B","A"])
0 A
1 A
2 B
3 C
4 B
5 B
6 C
7 A
8 B
Name: class, dtype: category
Categories (3, object): [C, B, A]
分类数据的排序仍然使用sort_values()
>>> df['class'].astype('category').cat.set_categories(['C','B','A']).sort_values()
3 C
6 C
2 B
4 B
5 B
8 B
0 A
1 A
7 A
Name: class, dtype: category
Categories (3, object): [C, B, A]
筛选最大值与最小值
>>> df['class'].astype('category').cat.as_ordered().min()
'A'
>>> df['class'].astype('category').cat.as_ordered().max()
'C'
二、分类数据的创建
1、通过参数dtype创建分类数据
创建Series或DataFrame时,可指定参数dtype = ‘category’创建Series或DataFrame
#创建Series
>>> s = pd.Series(['female','male','male'],dtype='category')
>>> s
0 female
1 male
2 male
dtype: category
Categories (2, object): [female, male]
#创建DataFrame
>>> df = pd.DataFrame({'sex':['female','male','male'],'grade':list('BAB')},dtype='category')
>>> df
sex grade
0 female B
1 male A
2 male B
>>> df.dtypes
sex category
grade category
dtype: object
2、通过pd.Categorical对象创建分类数据
创建一个pd.Categorical对象,并将其传入Series或者DataFrame,即可创建分类数据
>>> c = pd.Categorical(['C','A','B'])
>>> c
[C, A, B]
Categories (3, object): [A, B, C]
>>> c_df = pd.Categorical({'sex':['female','male','male'],'grade':list('BAB')})
>>> c_df
[sex, grade]
Categories (2, object): [grade, sex]
>>> df = pd.DataFrame({'sex':['female','male','male']})
>>> df['grade'] = c
>>> df
sex grade
0 female C
1 male A
2 male B
>>> df.dtypes
sex object
grade category
dtype: object
在创建pd.Categorical对象时,可以通过参数categoeies指定类别,没被指定的数据则会显示为缺失值
>>> c = pd.Categorical(['C','A','B','A'],categories=['A','B']) >>> s = pd.Series(c) >>> s 0 NaN 1 A 2 B 3 A dtype: category Categories (2, object): [A, B]
3、通过pd.Categorical.from_codes创建分类数据
当已知类别编码时,可通过pd.Categorical.from_codes创建分类数据;
>>> categories = ['female','male'] >>> codes = [1,1,1,0,0,1,0] >>> c = pd.Categorical.from_codes(codes,categories) >>> c [male, male, male, female, female, male, female] Categories (2, object): [female, male] >>> categories = ['female','male','unkonw'] >>> codes = [1,2,0,0,1,0] >>> c = pd.Categorical.from_codes(codes,categories) >>> c [male, unkonw, female, female, male, female] Categories (3, object): [female, male, unkonw]
注意:此时的categories = ['female','male','unkonw']的对应的codes值分别为0,1,2....。
4、通过cut()/qcut()创建分类数据---分类数值型数据
使用cut()/qcut()进行离散化会自动转为分类类型。
>>> math = pd.cut(df['score_math'],[0,60,80,100],right=False) >>> math[:3] 0 [80, 100) 1 [80, 100) 2 [80, 100) Name: score_math, dtype: category Categories (3, interval[int64]): [[0, 60) < [60, 80) < [80, 100)] #使用参数lables修改类别名称 >>> math = pd.cut(df['score_math'],[0,60,80,100],right=False,labels=['C','B','A']) >>> math[:3] 0 A 1 A 2 A Name: score_math, dtype: category Categories (3, object): [C < B < A]
结合groupby()查看分类数据,例:修改后的成绩等级无法看到分数区间的范围,可结合groupby查看各最大值、最小值等:
>>> df['score_math'].groupby(math).agg(['count','max','min'
count max min
score_math
C 1 59.0 59.0
B 0 NaN NaN
A 8 96.0 84.0
三、分类数据的常用操作方法
1、分类数据的特殊属性Series.cat
包含分类数据的Series有很多操作方法,可通过特殊属性Series.cat访问;
通过Series.cat查看其类别categories和编码codes.
>>> s = pd.Series(pd.Categorical(['C','A','B','C'])) >>> s 0 C 1 A 2 B 3 C dtype: category Categories (3, object): [A, B, C] >>> s.cat.categories Index(['A', 'B', 'C'], dtype='object') >>> s.cat.codes 0 2 1 0 2 1 3 2 dtype: int8
2、分类数据的常用操作方法
| 方法 | 说明 |
| rename_categories | 更改类别名称 |
| add_categories | 添加新类别 |
| remove_categories | 删除类别 |
| remove_unused_categories | 删除数据中没有出现的类别 |
| set_categories | 替换、增加和删除类别 |
| as_ordered | 分类数据设置有逻辑顺序 |
| as_unordered | 分类数据设置无逻辑顺序 |
| reorder_categories | 重排分类数数据的顺序 |
(1)更改类别名称-----可通过传入字典的方式进行更改
>>> s1 = s.cat.rename_categories({'A':'grade A','B':'grade B','C':'grade C'})
>>> s1
0 grade C
1 grade A
2 grade B
3 grade C
dtype: category
Categories (3, object): [grade A, grade B, grade C]
(2)添加新类别
>>> s2 = s.cat.add_categories('D')
>>> s2
0 C
1 A
2 B
3 C
dtype: category
Categories (4, object): [A, B, C, D]
(3)删除类别
注意:被删除的类别在数据集中显示值为空值
>>> s3 = s2.cat.remove_categories('D')
>>> s3
0 C
1 A
2 B
3 C
dtype: category
Categories (3, object): [A, B, C]
>>> s4 = s2.cat.remove_categories('A')
>>> s4
0 C
1 NaN
2 B
3 C
dtype: category
Categories (3, object): [B, C, D]
(4)删除数据中没有出现的类别,remove_categories只能删除某一特定的类别,并不能确定哪些类别并未使用过
>>> s2 0 C 1 A 2 B 3 C dtype: category Categories (4, object): [A, B, C, D] >>> s5 = s2.cat.remove_unused_categories() >>> s5 0 C 1 A 2 B 3 C dtype: category Categories (3, object): [A, B, C]
(5)同时添加或删除类别,使用set_categories,只需将需要的类别直接set即可
>>> s6 = s2.cat.set_categories(['B','C','E']) >>> s6 0 C 1 NaN 2 B 3 C dtype: category Categories (3, object): [B, C, E]
(6)设置逻辑顺序
分类数据的逻辑顺序可以通过as_ordered进行设置,也可以通过as_unordered设置为无逻辑顺序
>>> s_ordered = s2.cat.as_ordered() >>> s_ordered 0 C 1 A 2 B 3 C dtype: category Categories (4, object): [A < B < C < D] >>> s_unordered = s_ordered.cat.as_unordered() >>> s_unordered 0 C 1 A 2 B 3 C dtype: category Categories (4, object): [A, B, C, D]
在设置分类数据时,也可通过设置参数ordered = True设置逻辑顺序
>>> s_ordered_new = s2.cat.set_categories(['C','B','A'],ordered=True) >>> s_ordered_new 0 C 1 A 2 B 3 C dtype: category Categories (3, object): [C < B < A]
(7)重排逻辑顺序
方法一:前面已介绍,可通过set_categories自定义逻辑顺序
方法二:通过reorde_categories方法重排逻辑顺序
>>> s_or = s.cat.reorder_categories(['B','C','A'],ordered=True) >>> s_or 0 C 1 A 2 B 3 C dtype: category Categories (3, object): [B < C < A]
注意:使用reorder_categories方法不能添加或删除类别,否则会报错
>>>s.cat.reorder_categories(['B','C','A','D'],ordered=True) ValueError: items in new_categories are not the same as in old categories