1. 首先我们的目标函数是 最大似然估计,需要计算的是P(Y|X),即为给定vector x 的情况下,输出vector为Y的概率
1) 根据下图公式,我们可以看出,例如输入为 'we',输出为汉字的情况下,我们需要穷举计算所有汉字计算分母,是不可能的
2)所以将其优化为RNN的概率连乘

2. 最简单的self-attention
1)在之前的seq2seq中的attention机制,我们是用Xi乘以querySj,得到Wij,再softmax得到权重Wi的,再用权重Wi点乘Xi再相加的
那么这里面的 Query : Sj Key: Xi Value: Xi
2) 在self-attention中
1- 不再使用seq2seq中的RNN(时序)结构,允许并行计算
2- Query从Sj变为Xi,将Query Key Value三者全变成Xi


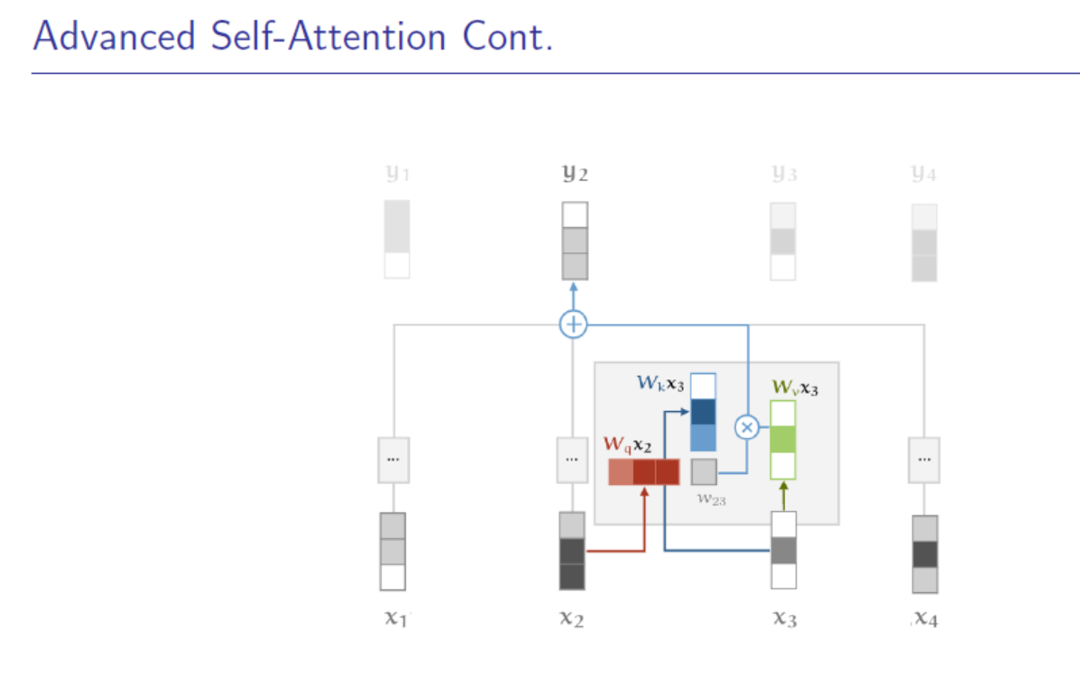
3. 带参数的self-attention
1)高阶self-attention,由于Query , Key , Value 都是Xi,可以将其做线性变换进行区分
2)在做softmax时,可以除以根号下dk,来减少softmax对极大值的敏感


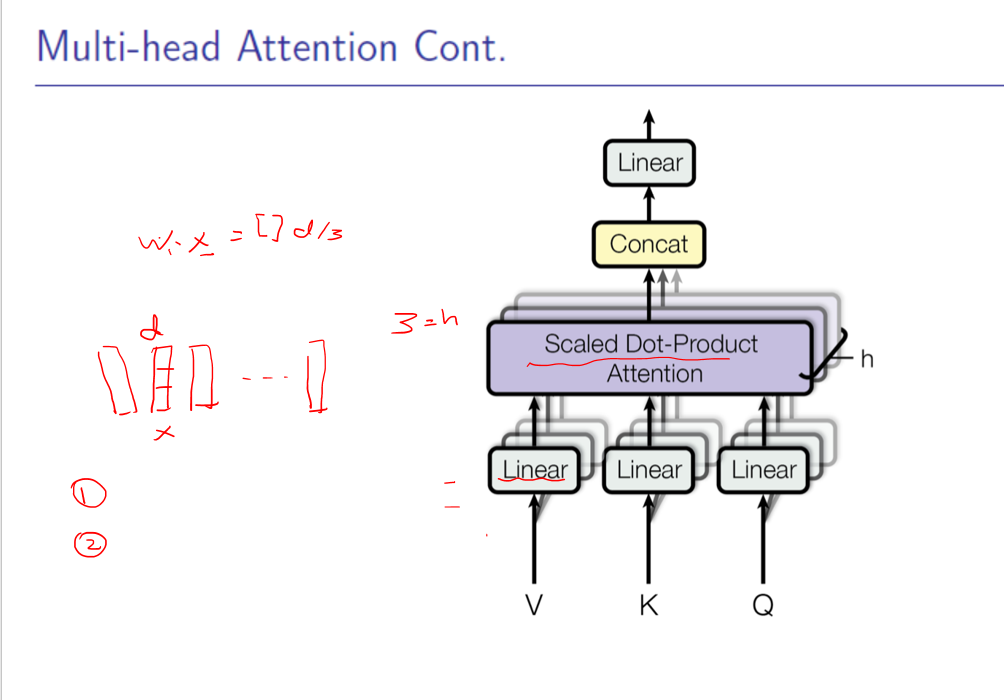
4. multi-head attention , 这边就讲的不清楚了
1) 对输入序列Xi,将其维度等分成dk(自定义参数)份,对于每份都计算其self-attention的输出,再拼接起来
2) 比如X为三维输入 (123,212,432),然后对每维度单独多维映射成query,key,value再计算其输出,最后拼接起来。

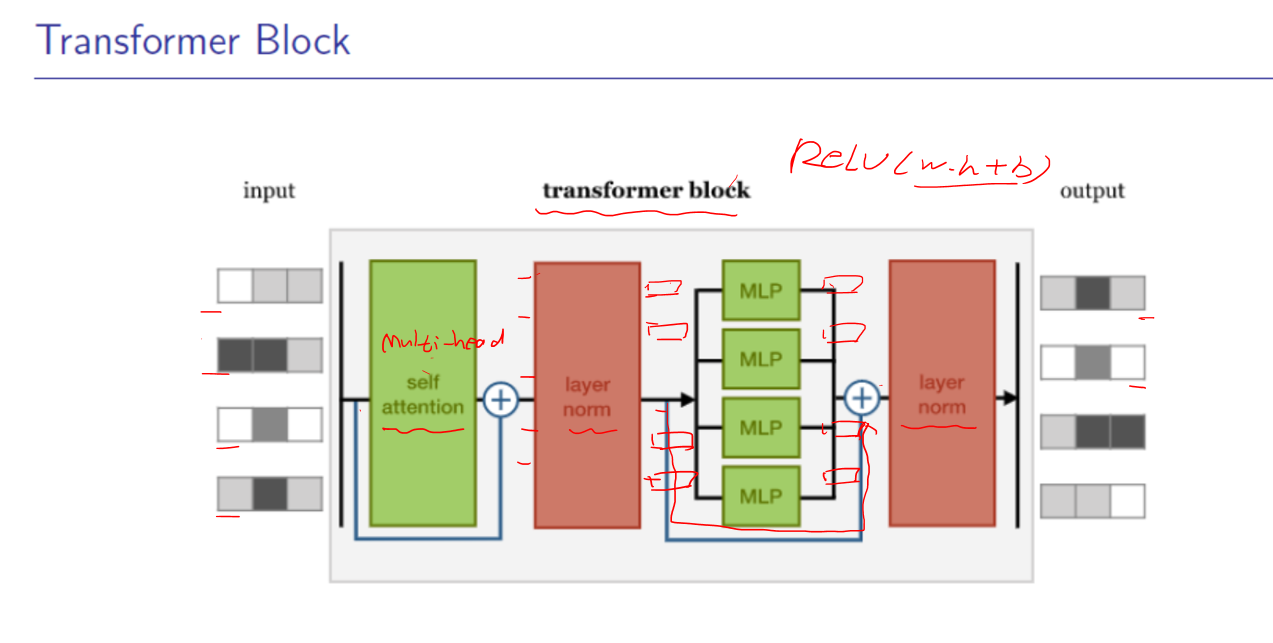
5. Transformer 细节也讲的不清楚