一、大数据技术涉及的技术层面
- 数据采集,通过etl将结构化、非结构化数据抽取到中间层,进行清洗、转换、加载到数据集市,作为数据分析、数据挖掘和流计算的基础
- 数据存储和管理,通过分布式文件系统、数仓、关系型数据库、NoSql数据库,对数据进行存储和管理
- 数据处理和分析,通过分布式计算框架,进行数据挖掘、数据分析
- 数据安全
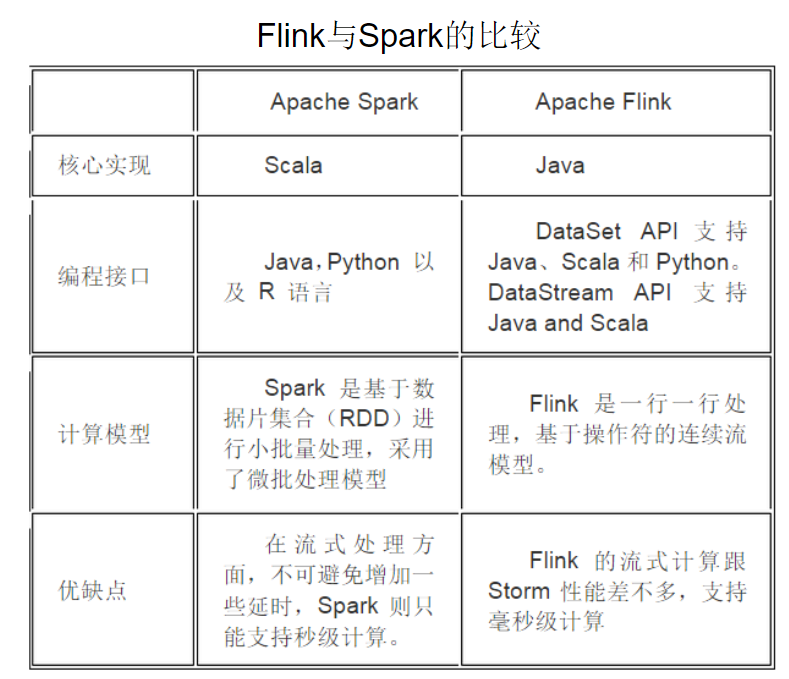
为实现上述功能,hadoop大数据架构核心功能,分布式架构(hdfs)和分布式处理(MapReduce)
hadoop生态通过MapReduce实现数据的分布式处理,spark则是代替MapReduce的更高效组件,spark只是代替mapReduce的分布式处理,spark借助hadoop的hafs、Hbase完成数据存储,然后由spark完成数据的计算。
延生:flink和spark都是基于内存计算框架进行实时计算,全都运行在hadoop Yarn上,性能上 flink > spark > hadoop(MR)。流失计算中,flink是一行一行处理,spark是基于数据片(RDD)进行小批量处理。
二、大数据常用计算模式及代表产品
1> 批处理计算,spark/mapReduce;2> 流计算,Storm/Streams;3> 图计算,GraphX、Pregel;4>查询分析计算,Impala/hive
企业常见业务场景:使用mapReduce实现离线批处理;使用Impala实现实时交互查询分析;使用Storm实现流式数据实时分析;使用Spark实现迭代计算
三、hadoop生态系统

以HDFS为基础,通过YARN来管理和调度集群资源,最终通过MapReduce实现分布式计算。而上层的Hive、Pig、Mahout等通过更简单的语言编译为MapReduce语句,给用户以更好的交互体验以及更低的使用门槛。
YARN
- YARN的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统 一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架 ;
- 由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种 计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性 收缩;
四、Spark的优势
hadoop计算框架存在如下缺点:表达能力有效、磁盘IO开销大;延迟高
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了 MapReduce所面临的问题 相比于Hadoop MapReduce,Spark主要具有如下优点 :
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作 ,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更 灵活
- Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算 效率更高
- Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的 迭代执行机制
Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
五、Spark生态系统
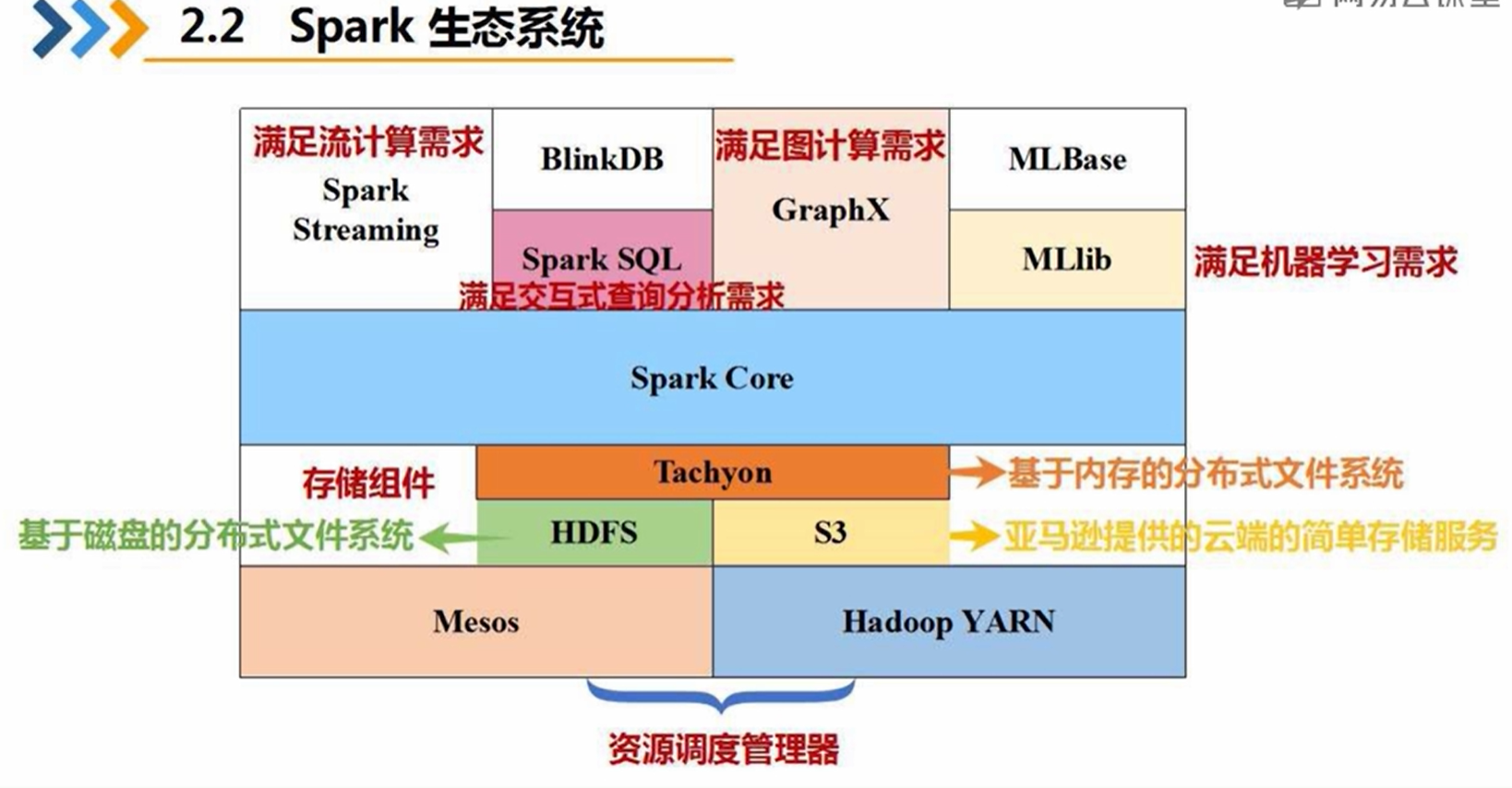
RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。弹性--》数据集可大可小,分布的数量可变
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
应用(Application):用户编写的Spark应用程序
任务( Task ):运行在Executor上的工作单元
作业( Job ):一个作业包含多个RDD及作用于相应RDD上的各种操作
阶段( Stage ):是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为阶段,或者也被称为任务集合,代表了一组关联的、相互之间 没有Shuffle依赖关系的任务组成的任务集

在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
spark运行流程:
- 当一个Spark应用被提交时,Driver创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源 ;
- 资源管理器为Executor分配资源,并启动Executor进程,Executor发送心跳到资源管理器上;
- SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”,并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
- 任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源 。
该过程的特点:
- 数据本地化,计算向数据靠拢;
- 多线程方式,executor执行task的时候采用多线程方式,减少了多进程任务频繁的启动开销;
- BlockManager存储模块,存储中间结果。
宽窄依赖

图中左边是宽依赖,父RDD的4号分区数据划分到子RDD的多个分区(一分区对多分区),这就表明有shuffle过程,父分区数据经过shuffle过程的hash分区器(也可自定义分区器)划分到子RDD。例如GroupByKey,reduceByKey,join,sortByKey等操作。
图右边是窄依赖,父RDD的每个分区的数据直接到子RDD的对应一个分区(一分区对一分区),例如1号到5号分区的数据都只进入到子RDD的一个分区,这个过程没有shuffle。Spark中Stage的划分就是通过shuffle来划分。(shuffle可理解为数据的从原分区打乱重组到新的分区)如:map,filter
总结:如果父RDD的一个Partition被一个子RDD的Partition所使用就是窄依赖,否则的话就是宽依赖。
job和stage和task的区分
1.一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job。
2.stage : stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。
3.task :即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个partition,就会有多少个 task,因为每一个 task 只是处理一个partition 上的数据。
Spark的运行架构由Driver(可理解为master)和Executor(可理解为worker或slave)组成,Driver负责把用户代码进行DAG切分,划分为不同的Stage,然后把每个Stage对应的task调度提交到Executor进行计算,这样Executor就并行执行同一个Stage的task。
六、弹性分布数据集(RDD)
RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD是只读的记录分区的集合,不能修改,可以再转换过程中进行修改。RDD提供了丰富的数据运算,转换类(map/filter),动作类(count/collect)。RDD运行原理 fork/join机制。
RDD特性:
- 只读(不能修改原始的RDD,可以再新生成RDD过程中进行修改)
- 内存操作,中间结果写入到内存,不落地到磁盘
Spark 根据DAG 图中的RDD 依赖关系,把一个作业分成多个阶段。阶段划分的依据是窄依赖和宽依赖。
RDD在Spark架构中的运行过程:
- 创建RDD对象;
- SparkContext负责计算RDD之间的依赖关系,构建DAG;
- DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个 Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
七、spark SQL 基础
Hive库是一种基于Hadoop开发的数据仓库,相当于是SQL on Hadoop。其内部将SQL转译为MapReduce作业。
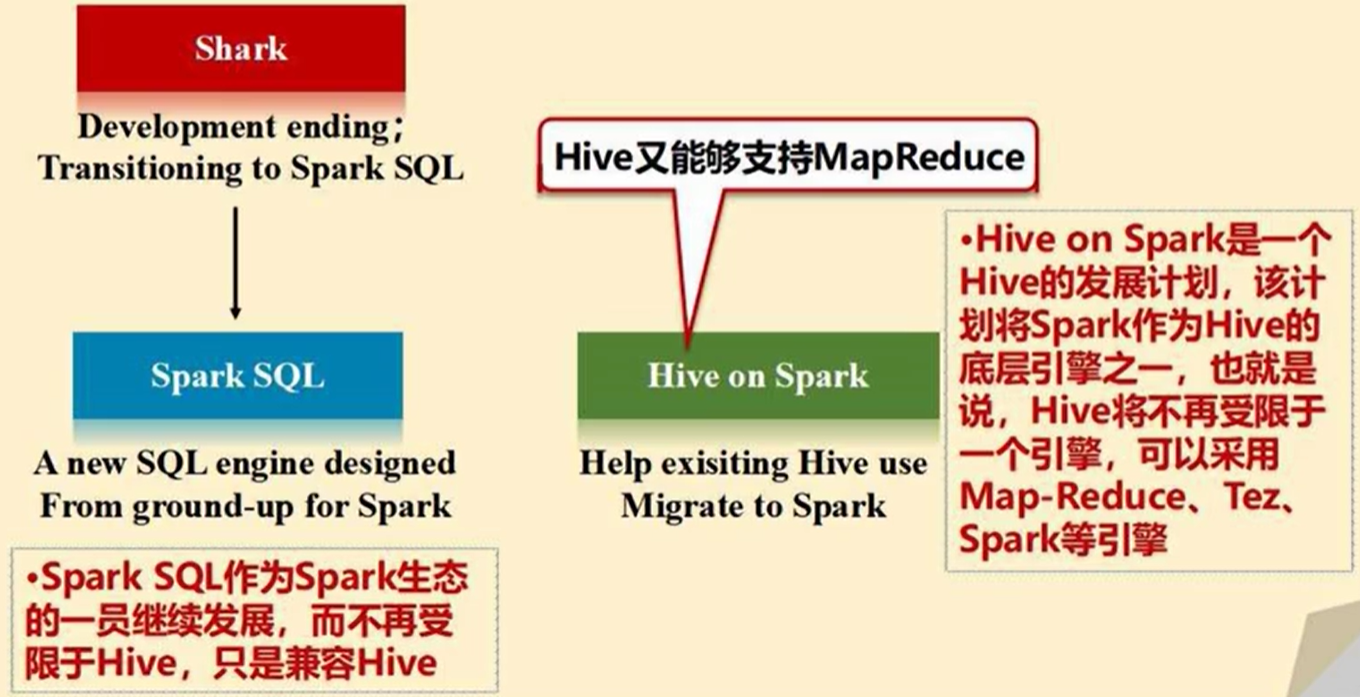
Spark SQL中新增了DataFrame(包含模式的RDD)。在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、 HDFS、Cassandra等外部数据源。
DataFrame与RDD的区别
- DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原 有的RDD转化方式更加简单易用,而且获得了更高的计算性能 ;
- Spark能够轻松实现从MySQL到DataFrame的转化 ,并且支持SQL查询;
- RDD是分布式的Java对象的集合。但是,对象内部结构,对于RDD而言却是不可知的。DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息 。
SparkSession支持从不同的数据源加载数据,并把数据转换成 DataFrame,并且支持把DataFrame转换成SQLContext自身中的表, 然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其 他依赖于Hive的功能的支持。
from pyspark import SparkContext,SparkConf from pyspark.sql import SparkSession spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate() 创建DataFrame时,可以使用spark.read操作 #读取文本文件people.txt创建DataFrame spark.read.text("people.txt") #读取people.json文件创建DataFrame。在读取本地文件或HDFS文件时,要注意给出正确的文件路径 。 spark.read.json("people.json") #读取people.parquet文件创建DataFrame spark.read.parquet("people.parquet") #读取文本文件people.json创建DataFrame spark.read.format("text").load("people.txt") #读取JSON文件people.json创建DataFrame spark.read.format("json").load("people.json") 保存DataFrame df.write.text("people.txt") df.write.json("people.json“) 或者 df.write.format("text").save("people.txt") df.write.format("json").save("people.json")
RDD转换DataFrame
首先生成RDD文件,然后生成DataFrame文件。 >>> from pyspark.sql import Row >>> people = spark.sparkContext. ... textFile("file:///usr/local/spark/examples/src/main/resources/people.txt"). ... map(lambda line: line.split(",")). ... map(lambda p: Row(name=p[0], age=int(p[1]))) >>> schemaPeople = spark.createDataFrame(people) 必须注册为临时表才能供下面的查询使用 >>> schemaPeople.createOrReplaceTempView("people") >>> personsDF = spark.sql("select name,age from people where age > 20") DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用 p.name和p.age来获取值。既可以再的得到RDD文件 >>> personsRDD=personsDF.rdd.map(lambda p:"Name: "+p.name+ ","+"Age:"+str(p.age)) >>> personsRDD.foreach(print) Name: Michael,Age: 29 Name: Andy,Age: 30 当无法提前获知数据结构时,就需要采用编程方式定义RDD模式。 需要通过编程方式把people.txt加载进来生成 DataFrame,并完成SQL查询 >>> from pyspark.sql.types import * >>> from pyspark.sql import Row #下面生成“表头” >>> schemaString = "name age" >>> fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split(" ")] >>> schema = StructType(fields) #下面生成“表中的记录” >>> lines = spark.sparkContext. ... textFile("file:///usr/local/spark/examples/src/main/resources/people.txt") >>> parts = lines.map(lambda x: x.split(",")) >>> people = parts.map(lambda p: Row(p[0], p[1].strip())) #下面把“表头”和“表中的记录”拼装在一起 >>> schemaPeople = spark.createDataFrame(people, schema)
spark sql 读写mysql ,可以通过jdbc连接数据库,读取数据
要向spark.student表中插入两条记录 。则该过程可分为4步进行:
- 建立表头
- 生成Row对象
- 将表头与Row对象对应起来
- 写入数据库
建立表头 #!/usr/bin/env python3 from pyspark.sql import Row from pyspark.sql.types import * from pyspark import SparkContext,SparkConf from pyspark.sql import SparkSession #生成一个指挥官(SparkSession) spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate() #下面设置模式信息(表头),每个字段指定为一个StructField schema = StructType([StructField("id", IntegerType(), True), StructField("name", StringType(), True), StructField("gender", StringType(), True), StructField("age", IntegerType(), True)]) 生成Row对象 #下面设置两条数据,表示两个学生的信息,parallelize得到包含两个元素的RDD,".map"不改变元素个数 studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda x:x.split(" ")) #下面创建Row对象,每个Row对象都是rowRDD中的一行,通过Row对象转化为DataFrame rowRDD = studentRDD.map(lambda p:Row(int(p[0].strip()), p[1].strip(),p[2].strip(), int(p[3].strip()))) 利用数据和表头生成DataFrame: #建立起Row对象和模式之间的对应关系,也就是把数据(Row对象)和模式(表头)对应起来 studentDF = spark.createDataFrame(rowRDD, schema)
将DataFrame存入数据库中: #写入数据库 prop = {} prop['user'] = 'root' #用户名 prop['password'] = '123456' #密码 prop['driver'] = "com.mysql.jdbc.Driver" #驱动程序名称 #jdbc中的4个参数分别代表"数据库","表名","追加","相关信息全部写入" studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)
八、Spark Streaming
Spark Streaming可整合多种输入数据源,如Kafka、 Flume、HDFS,甚至是普通的TCP套接字。经处理后的 数据可存储至文件系统、数据库,或显示在仪表盘里。
Spark Streaming并不是真正意义上的流计算 。其基本原理是将实时输入数据流以时间片(最小单位为秒)为单位进行拆分,然后经Spark引擎以微小批处理的方式处理每个时间片数据。
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作 。因此,Spark Streaming是建立在SparkCore之上的。其逻辑本质很简单,就是一系列的RDD。
每一种Spark工作方式都有一种数据抽象,回顾一下:
- Spark Core:数据抽象为 RDD;
- Spark SQL:数据抽象为 DataFrame;
- Spark Streaming:数据抽象为 DStream。
Spark Streaming与Storm的对比:
- Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应;
- Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理;
- Spark Streaming可以同时兼容批量和实时数据处理的逻辑和算法。因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合。
编写Spark Streaming程序的基本步骤是:
- 通过创建输入DStream来定义输入源;
- 通过对DStream应用转换操作和输出操作来定义流计算;
- 用streamingContext.start()来开始接收数据和处理流程 ;
- 通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束);
- 可以通过streamingContext.stop()来手动结束流计算进程。
如果要运行一个Spark Streaming程序,就需要首先生成一个 StreamingContext对象 ,它是Spark Streaming程序的主入口。可以从一个SparkConf对象创建一个StreamingContext对象。
在pyspark中的创建方法:进入pyspark以后,就已经获得 了一个默认的SparkConext对象,也就是sc。因此,可以采用如下方式来创建StreamingContext对象。详见代码注释:
>>> from pyspark.streaming import StreamingContext >>> ssc = StreamingContext(sc, 1)#每隔1秒做一次 #如果是编写一个独立的Spark Streaming程序,而不是在 pyspark中运行,则需要通过如下方式创建StreamingContext 对象 ,详见代码注释: from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext conf = SparkConf() conf.setAppName('TestDStream') #设置数据流应用的名称 conf.setMaster('local[2]') #本地,2个线程 sc = SparkContext(conf = conf) #生成SparkContext主入口 ssc = StreamingContext(sc, 1)
流计算的数据源分为两大类,一部分为基础数据源,另一部分为高级数据源
文件流 套接字流 RDD队列流
第一步定义文件流输入源,第二步针对源源不断出现的数据进行转,第三步对结果进行输出,第四步启动流计算。
from pyspark import SparkContext >>> from pyspark.streaming import StreamingContext >>> ssc = StreamingContext(sc, 10) #每隔10秒 >>> lines = ssc. ... textFileStream('file:///usr/local/spark/mycode/streaming/logfile') #监控目录,本地文件用3个"/" >>> words = lines.flatMap(lambda line: line.split(' ')) >>> wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b) #得到键值对并聚合得到词频统计 >>> wordCounts.pprint() #第三步格式化输出 >>> ssc.start() #启动流计算,对目录进行监控、捕捉。 >>> ssc.awaitTermination() #等待流计算结束 编写独立应用程序 首先在指定目录中构建一个py程序。 $ cd /usr/local/spark/mycode $ cd streaming $ cd logfile $ vim FileStreaming.py 流计算的基本步骤和交互式环境类似,编辑代码如下。 #!/usr/bin/env python3 from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext conf = SparkConf() #生成指挥官 conf.setAppName('TestDStream') #流计算程序名称 conf.setMaster('local[2]') #本地模式流计算,两个线程 sc = SparkContext(conf = conf) ssc = StreamingContext(sc, 10) #每隔10秒 lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile') #定义输入源 words = lines.flatMap(lambda line: line.split(' ')) #分割处理 wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b) #词频统计 wordCounts.pprint() #输出 ssc.start() #启动流计算,对目录进行监控、捕捉。 ssc.awaitTermination() #等待流计算结束。 通过如下命令启动上述流计算过程。 $ cd /usr/local/spark/mycode/streaming/logfile/ $ /usr/local/spark/bin/spark-submit FileStreaming.py
九、spark MLlib
大数据时代的到来 ,完全颠覆了传统的思维方式:
- 分析使用全量样本,而非抽样后进行分析 ;
- 更注重处理效率,而非精确度 ;
- 丰富的数据源与分析目标相关,而不具有直接的因果关系。
传统的机器学习算法,由于技术和单机存储的限制,只能在少量数据上使用,依赖于数据抽样 。由于强大的数据存储与传输能力,可以支持在 全量数据上实现机器学习。机器学习算法涉及大量迭代计算 ,而基于磁盘的Map-Reduce在计算时磁盘IO开销较大,因此需要使用基于内存的Spark。
Spark作为现阶段Hadoop架构中,替代Map-Reduce进行分布式处理的主要数据处理组件,和HDFS、Hbase等数据组件共同构成了现阶段主流大数据工具系统。现阶段已经不需要通过抽样方法来实现建模操作。
不进行抽样,而是使用全量样本进行建模分析,是大数据建模技术的标志。
Spark提供了一个基于海量数据的机器学习库——Spark MLib,它提供 了常用机器学习算法的分布式实现。开发者只需要有Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程。Pyspark的即席查询也是一个关键。算法工程师可以边写代码边运行,边看结果。