一.正则表达式测试网址
http://tool.oschina.net/regex/
网页格式:https://tool.oschina.net/codeformat/html
二.正则表达式常用匹配规则
三.Python3的三种匹配

1.match()方法
match方法只能从匹配字符的开头进行匹配,不匹配返回None,匹配返回对应的值
""" 1.match()方法会尝试从字符串的起始位置匹配正则表达式: 如果匹配,就返回匹配成功的结果 如果不匹配,就返回None """ import re content = "Hello 123 4567 World_This is a Regex Demo" result = re.match('^Hellosdddsd{4}sw{10}',content) #输出匹配结果 print(result) #输出匹配每一组 print(result.group()) #输出匹配的间距定位 print(result.span())


import re content = "Hello 123 4567 World_This is a Regex Demo" #匹配模式编译 pattern = re.compile('^Hellosdddsd{4}sw{10}') result = re.match(pattern,content) #输出匹配结果 print(result) #输出匹配每一组 print(result.group()) #输出匹配的间距定位 print(result.span())

2.search()方法
search可以根据匹配模式,查找匹配的一个,而不是多个,匹配到返回结果,匹配不到返回空
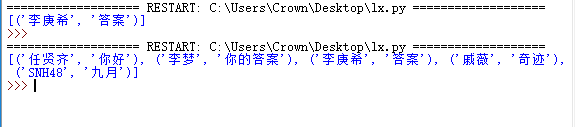
""" 1.上面的match方法是从头开始匹配,不匹配就会失败 match适合检测某个字符串是否符合某个正则表达式的规则 2.search可以匹配一组的值 """ import re html =''' <div id="songs-list"> <h2 class="title">经典老歌</h2> <p class="introduction">经典老歌列表</p> <ul id="list" class="list-group"> <li data-view="2">天山</li> <li data-view="7"> <a href="hello.mp3" singer="任贤齐">你好</a> </li> <li data-view="4"> <a href="world.mp3" singer="李梦">你的答案</a> </li> <li data-view="6" class="active"> <a href="My.mp3" singer="李庚希">答案</a> </li> <li data-view="5"> <a href="name.mp3" singer="戚薇">奇迹</a> </li> <li data-view="5"> <a href="Justice.mp3" singer="SNH48">九月</a> </li> </ul> </div> ''' #匹配结果 result = re.search('<li.*?active".*?singer="(.*?)">(.*?)</a>',html,re.S) if result: print(result.group(1),result.group(2))
import re html =''' <div id="songs-list"> <h2 class="title">经典老歌</h2> <p class="introduction">经典老歌列表</p> <ul id="list" class="list-group"> <li data-view="2">天山</li> <li data-view="7"> <a href="hello.mp3" singer="任贤齐">你好</a> </li> <li data-view="4"> <a href="world.mp3" singer="李梦">你的答案</a> </li> <li data-view="6" class="active"> <a href="My.mp3" singer="李庚希">答案</a> </li> <li data-view="5"> <a href="name.mp3" singer="戚薇">奇迹</a> </li> <li data-view="5"> <a href="Justice.mp3" singer="SNH48">九月</a> </li> </ul> </div> ''' pattern = re.compile('<li.*?active".*?singer="(.*?)">(.*?)</a>',re.S) #匹配结果 result = re.search(pattern,html) if result: print(result.group(1),result.group(2))

3.findall()方法
""" 1.finall相当于多个search进行匹配,获取所有符合匹配的 """ import re html =''' <div id="songs-list"> <h2 class="title">经典老歌</h2> <p class="introduction">经典老歌列表</p> <ul id="list" class="list-group"> <li data-view="2">天山</li> <li data-view="7"> <a href="hello.mp3" singer="任贤齐">你好</a> </li> <li data-view="4"> <a href="world.mp3" singer="李梦">你的答案</a> </li> <li data-view="6" class="active"> <a href="My.mp3" singer="李庚希">答案</a> </li> <li data-view="5"> <a href="name.mp3" singer="戚薇">奇迹</a> </li> <li data-view="5"> <a href="Justice.mp3" singer="SNH48">九月</a> </li> </ul> </div> ''' #匹配结果 result = re.findall('<li.*?singer="(.*?)">(.*?)</a>',html,re.S) if result: print(result)
import re html =''' <div id="songs-list"> <h2 class="title">经典老歌</h2> <p class="introduction">经典老歌列表</p> <ul id="list" class="list-group"> <li data-view="2">天山</li> <li data-view="7"> <a href="hello.mp3" singer="任贤齐">你好</a> </li> <li data-view="4"> <a href="world.mp3" singer="李梦">你的答案</a> </li> <li data-view="6" class="active"> <a href="My.mp3" singer="李庚希">答案</a> </li> <li data-view="5"> <a href="name.mp3" singer="戚薇">奇迹</a> </li> <li data-view="5"> <a href="Justice.mp3" singer="SNH48">九月</a> </li> </ul> </div> ''' pattern = re.compile('<li.*?singer="(.*?)">(.*?)</a>',re.S) #匹配结果 result = re.findall(pattern,html) if result: print(result)
四.贪婪模式和非贪婪模式
贪婪模式就是在使用匹配符号(.*)的时候,会匹配更多的内容
非贪婪模式就是在匹配符号(.*?),减少最多匹配,防止缺失
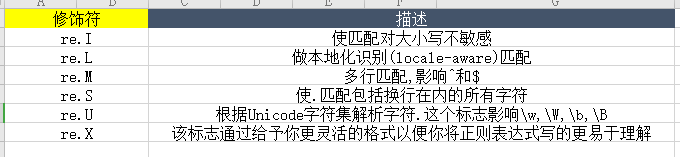
五.Python3的修饰符
六.一些常用匹配解析库
正则表达式
XPath
BeautifulSoup
pyquery