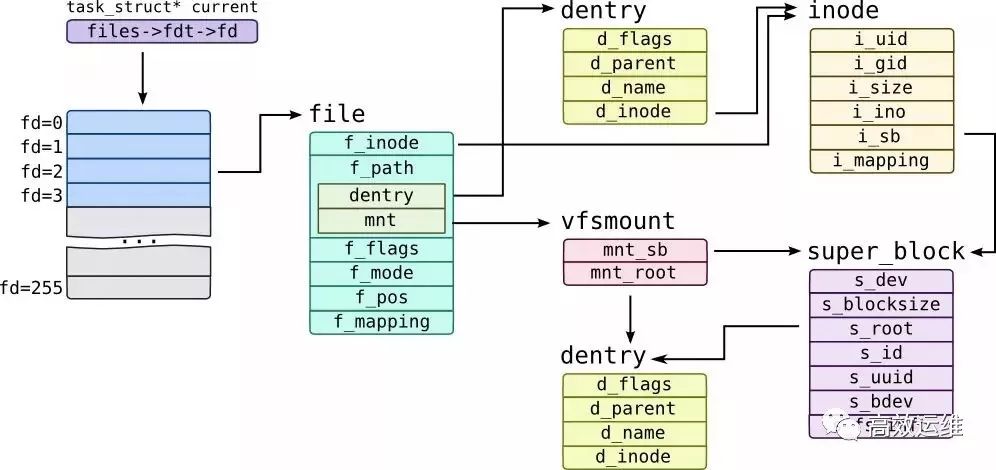
这里我们先区分好两个概念:文件描述符和文件句柄
简单来说,每个进程都有一个打开的文件表(fdtable)。表中的每一项是struct file类型,包含了打开文件的一些属性比如偏移量,读写访问模式等,这是真正意义上的文件句柄。
文件描述符是一个整数。代表fdtable中的索引位置(下标),指向具体的struct file(文件句柄)。
哪些地方会分配文件句柄?
知道文件句柄最终是通过get_empty_filp函数从filp cache中分配的之后,我们顺着函数调用链路简单梳理下,就能知道有哪些地方会分配文件句柄了:
- open系统调用打开文件(path_openat内核函数)
- 打开一个目录(dentry_open函数)
- 共享内存attach (do_shmat函数)
- socket套接字(sock_alloc_file函数)
- 管道(create_pipe_files函数)
- epoll/inotify/signalfd等功能用到的匿名inode文件系统(anon_inode_getfile函数)
file-nr文件里面的第一个字段代表的是内核分配的struct file的个数,也就是文件句柄个数,而不是文件描述符
机器上的常常会出现文件句柄使用量与常用的lsof命令的数量相去甚远的情况

因为文件描述符和文件句柄是两个不同的东西:lsof在用户空间,主要还是从文件描述符的角度来看文件句柄。
我们来做一个实验:只打开一次文件,然后复制1000次文件描述符。
我们启动dupfd进程打开了一次/dev/zero文件,复制了1000次文件描述符。file-nr中的文件句柄数只是个位数的变化,而lsof看到的结果涨了1000多。
如果我们把前面的代码换成open 1000次, 就可以看到file-nr和lsof的输出几乎都涨了1000。
我们循环1000次打开/dev/zero文件,之后mmap映射到进程地址空间,然后把这些打开的文件描述符都关掉。很显然,打开的描述符都被close掉了,不会有什么变化。 那为什么文件句柄数还是增加了1000个左右呢?
原来,linux内核中很多对象都是有引用计数的。 虽然文件句柄是由open先打开的,但mmap之后,引用计数被加1,尽管我们接着把文件描述符close掉了,但是底层指向的struct file由于引用数大于0,不会被回收。
通过上面两个例子,你应该知道lsof的输出和实际的文件句柄数有差距的原因了。