原创By DeeZeng [ Intel FPGA笔记 ]
在用Nios II测试 DDR3时候发现一个现象 (测试为:写全片,读全片+比对)
- 用单独的PLL产生时钟(200MHz)驱动 Nios II, 测试DDR3时间为87s
- 用 DDR3 IP的 afi_clk(200MHz) 驱动 Nios II, 测试DDR3时间为67s
只是换了个时钟为什么影响这么大?相差近 20s
分析发现
- PLL 产生的时钟 和 DDR3 的afi_clk 是两个时钟域
- Qsys interconnect 会在 Avalon MM 不同时钟域 自动插入 Clock Crossing Adapter
- Nios II的读写 和 Clock Crossing Adapter 特性造成传输效率低下
接下来将具体分析一下,为什么测试时间会相差那么大:
一、跨时钟域 Qsys自动插入 Clock Crossing Adapter
1. 当Avalon MM Master 和 Avalon MM Slave 的时钟为不同时钟的时候 (类似Nios II 用pll 200MHz , DDR3 都用了 afi_clk 200MHz)
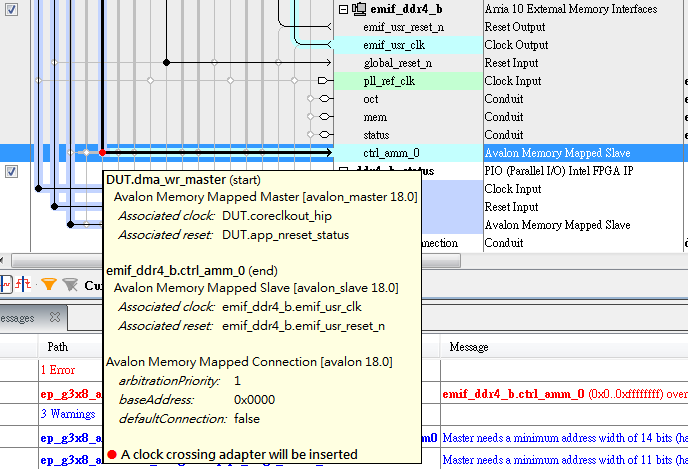
我们将鼠标悬浮在 黑圆点那 可以看到连接信息,并且 红点提示:A Clock Crossing adapter will be inserted
2. 当Avalon MM Master 和 Avalon MM Slave 的时钟为同一个的时候 (类似Nios II 和 DDR3 都用了 afi_clk)
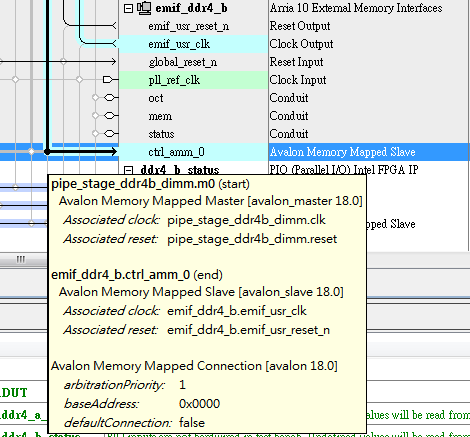
我们将鼠标悬浮在 黑圆点那 可以看到连接信息, 然后不会有Clock Crossing Bridge提示
二、 Clock Crossing Adapter 将增加 多个周期 的 latency
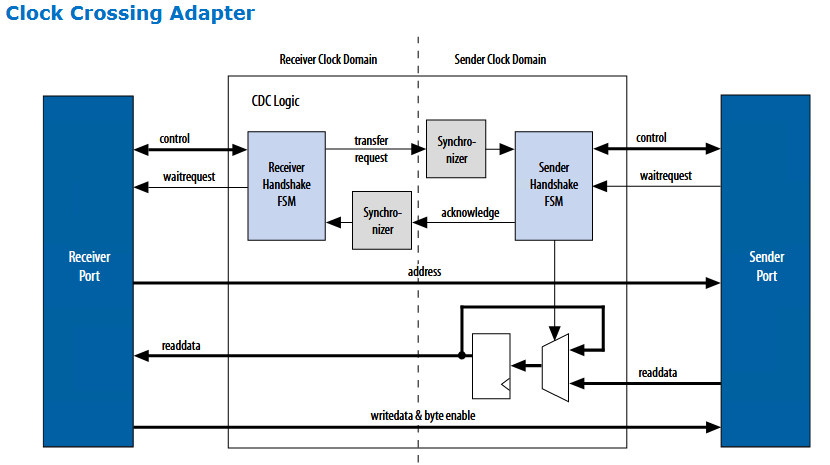

如上两图,可以看出Clock Crossing Adapter的架构 将导致增加几个周期的 latency
三、增加的Latency 对传输效率有什么影响?
1. 低效率的读写操作,雪上加霜
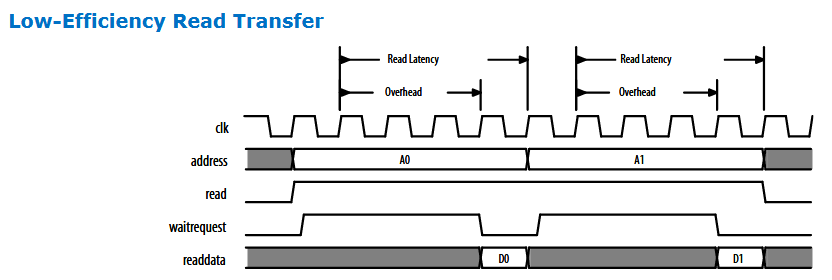
如果本身传输协议就是如上图这种低效的。 动作半天,只读了一个word。 那增加几个latency后效率变得更低下
举例:
如果原来4个周期出一个Word, 那效率是 25%
而加上5个周期 latency后,变为9个周期出一个Word,效率降低为 11%
2. 高效率的读写操作,影响不大
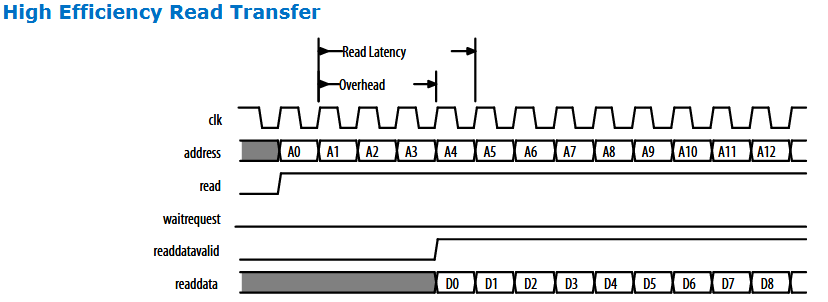
如果本身传输协议就是如上图这种高效的。 burst传输,只是延迟几个周期
举例:
如果原来4个周期出delay,一次传输100个word 耗时 104 ,效率为 96%
而加上5个周期 latency后,变为109个周期出100 Word,效率降低为 92%
四、Nios II 的读写是什么情况呢?
从上面 一 二 三 点分析,我们已经知道测试时间增长的原因:增加的 Timing Crossing Adapter造成传输效率变低了
经查手册,找到一个 Nios II 的 操作时序图(并非Nios II 操作DDR3的) ,操作 latency4个周期 一次操作8个
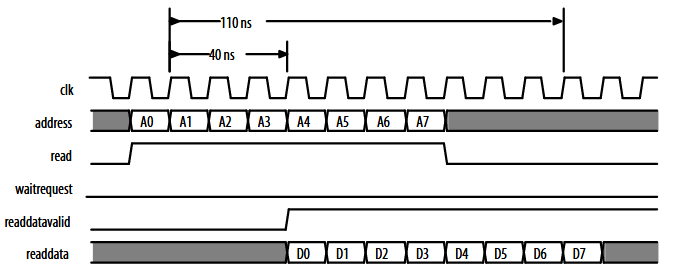
举例:
如果原来4个周期出delay,一次传输8个word 耗时 12,效率为 66%
插入Timing Adapter 假设增加了5个周期 latency后,变为17个周期出8Word,效率降低为 47%
(这里只是举例, Nios II操作DDR3实际并非这种时序。 DDR3 -> DDR -> Quarter Bridge ->,
DDR3的read latency也会随着这些bridge变换。bus变换过程中也增加了Width Adapter等,所以只是简单判断原因 )
所以 测试DDR3为:写全片,读全片+比对。比对耗时一致。读写变慢导致时间差异
这篇博文的目的:
1. 关注带宽和吞吐量的应用,注意一下这些 Clock Crossing Adapter 和 Pipe Bridge 的添加 (注意到 Bridge有可能降低传输效率这回事)
分析 bridge带来 fmax 的提升,和效率降低的权衡。 (其实关键就是尽量burst 提升传输效率)
2. 这篇分析 并不是不建议用 Timing Clock Crossing Adapter (注意到 Bridges 还有很多其他作用)
它还有很多的作用 如
1. 提升fmax
2.调节架构(多个master,多个slave)节省逻辑资源
3. ...