Caffe
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors.Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license
1.FrameWork of Caffe
Caffe是一种开源软件框架,内部提供了一套基本的编程框架,或者说一个模板框架,用以实现GPU并行架构下的深度卷积神经网络,DeepLearning等算法,能在性能上大幅度提升,相比较
A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, 2012.中的Highperformance convnet而言,我们可以按照框架定义各种各样的卷积神经网络的结构,并且可以再此框架下增加自己的代码,设计新的算法,该框架的一个问题就是,只能够使用卷积网络,所有框架都是再基于卷积神经网路的模型上进行的。
大家如果对别的深度学习算法感兴趣,推荐使用TensorFlow,这个能够完成更多的算法,比如RNN,LSTM等
2.Caffe的三大不可更改的基本组成结构
caffe具有三个基本都是额原子结构,顾名思义,原子结构就是说不能随意更改,caffe的编程框架就是在这三个原子下实现,它们分别是:Blobs, Layers, and Nets
- Blob
A Blob is a wrapper over the actual data being processed and passed along by Caffe, and also under the hood provides synchronization capability between the CPU and the GPU. Mathematically, a blob is a 4-dimensional array that stores things in the order of (Num, Channels, Height and Width), from major to minor, and stored in a C-contiguous fashion. The main reason for putting Num (the name is due to legacy reasons, and is equivalent to the notation of “batch” as in minibatch SGD).
Caffe stores and communicates data in 4-dimensional arrays called blobs. Blobs provide a unified memory interface, holding data e.g. batches of images, model parameters, and derivatives for optimization.
Blobs conceal the computational and mental overhead of mixed CPU/GPU operation by synchronizing from the CPU host to the GPU device as needed. Memory on the host and device is allocated on demand (lazily) for efficient memory usage.
The conventional blob dimensions for data are number N x channel K x height H x width W. Blob memory is row-major in layout so the last / rightmost dimension changes fastest. For example, the value at index (n, k, h, w) is physically located at index ((n * K + k) * H + h) * W + w.
- Number / N is the batch size of the data. Batch processing achieves better throughput for communication and device processing. For an ImageNet training batch of 256 images B = 256.
- Channel / K is the feature dimension e.g. for RGB images K = 3.
Note that although we have designed blobs with its dimensions corresponding to image applications, they are named purely for notational purpose and it is totally valid for you to do non-image applications. For example, if you simply need fully-connected networks like the conventional multi-layer perceptron, use blobs of dimensions (Num, Channels, 1, 1) and call the InnerProductLayer (which we will cover soon).
Caffe operations are general with respect to the channel dimension / K. Grayscale and hyperspectral imagery are fine. Caffe can likewise model and process arbitrary vectors in blobs with singleton. That is, the shape of blob holding 1000 vectors of 16 feature dimensions is 1000 x 16 x 1 x 1.
Parameter blob dimensions vary according to the type and configuration of the layer. For a convolution layer with 96 filters of 11 x 11 spatial dimension and 3 inputs the blob is 96 x 3 x 11 x 11. For an inner product / fully-connected layer with 1000 output channels and 1024 input channels the parameter blob is 1 x 1 x 1000 x 1024.
For custom data it may be necessary to hack your own input preparation tool or data layer. However once your data is in your job is done. The modularity of layers accomplishes the rest of the work for you.
以上是官网上对Blob的介绍,讲了这么多,其实就是想说,Blob就是一个包装器,在caffe这个流程中,所有的数据都要被包装成blob格式。然后在caffe的架构下进行编程和处理,这点事我们不能随意更改的,因为caffe本身提供了很多已经设计好的函数和类,我们随意更改数据包转器就等于没法再使用其中的函数,你就没法再Caffe的框架下设计深度神经网络。
blob的格式就是(Number,Channel,Height,Width)将数据按照四元组的方式存储,这里由于是处理的图像数据,所以后面三维代表图像的数据格式,Channel代表图像的通道数,如灰度图是1通道,Channel=1,RGB图像是3通道,Channel=3,Height和Width分别是图像的长宽。至于Number则代表Batch,由于内存有限,所以我们进行训练的时候我们只能分批进行,这里还为每个batch设置了一个标识号,后面会看到我们使用随机梯度下降算法(Schocastic gredient descent,SGD)对模型进行训练,其中就是要使用到Batch,blob不仅仅只用来保存深度网路进行前向过程时的数据,还用来保存在后向求梯度过程时的提梯度数据
具体使用方式:
const Dtype* cpu_data() const;
Dtype* mutable_cpu_data();
上面两中格式分别表示数据的固态模式和和自由模式,blob具有CPU的数据保存和GPU的数据保存,同时blob将数据在CPU和GPU之间的交换封装起来了,
并进行了同步处理,因此我们不需要理会数据在GPU和CPU之间的交互。
-
layer
Layer computation and connections,层是组成网络结构的单位,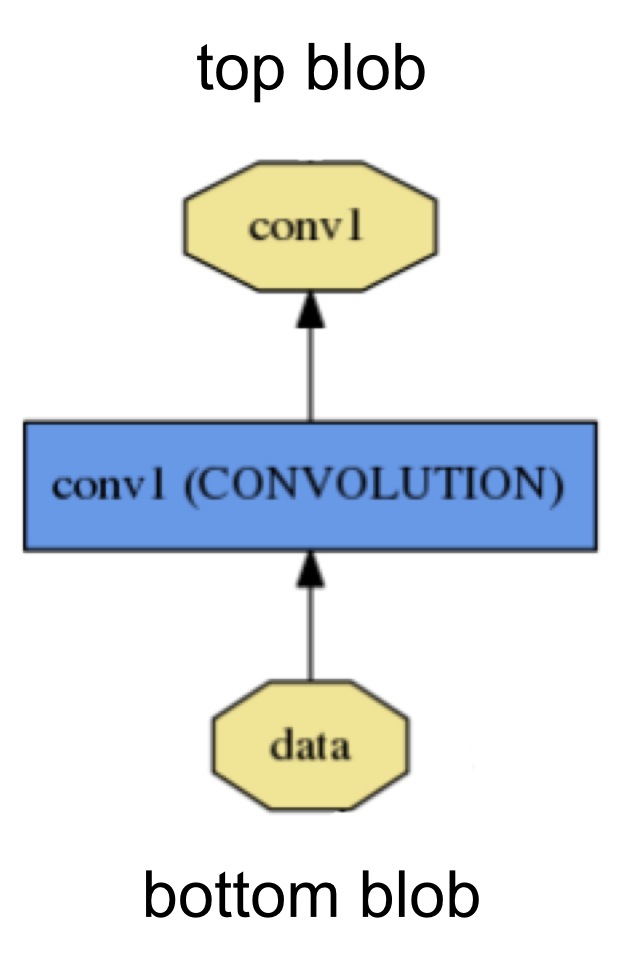
层接受下层的数据输出作为输入,通过内部的运算输出,这是卷积神经网络的内容这里不再详细介绍,主要说下Caffe中定义的层的结构的使用和编程方法
A layer takes input through bottom connections and makes output through top connections.
Each layer type defines three critical computations: setup, forward, and backward.
- Setup: initialize the layer and its connections once at model initialization.
- Forward: given input from bottom compute the output and send to the top.
- Backward: given the gradient w.r.t. the top output compute the gradient w.r.t. to the input and send to the bottom. A layer with parameters computes the gradient w.r.t. to its parameters and stores it internally.
以上是官网中对Caffe中网络层的使用定义,和一般的深度学习库类似,,都有三个步骤,1:建立层,包括建立连接关系初始化其中一些变量。2:前向计算过程,接受输入数据并计算出输出,3:后向过程,进行反向梯度的计算,并把梯度保存在层结构中
- Net definition
网络是由层组成的,定义了输入输出,网络各层,就定义了一个网络,官网说法:The net is a set of layers connected in a computation graph – a directed acyclic graph (DAG) to be exact,举一个回归网络的定义:

定义代码如下:
name: "LogReg"
layers {
name: "mnist"
type: DATA
top: "data"
top: "label"
data_param {
source: "input_leveldb"
batch_size: 64
}
}
layers {
name: "ip"
type: INNER_PRODUCT
bottom: "data"
top: "ip"
inner_product_param {
num_output: 2
}
}
layers {
name: "loss"
type: SOFTMAX_LOSS
bottom: "ip"
bottom: "label"
top: "loss"
}实际上,代码只有三层,输入,中间层,输出层,这是一种最基本的单隐层的网络。我们可以使用 Net::Init()对定义的网络进行初始化和检查,初始化包括对一些变量权值初始化,,检查包括对网络的结构的正确性进行检查,因为涉及到网络的上下层连接
关系的匹配和耦合连接