前言
索引对于MySQL来说,是非常重要的篇章。索引知识点巨多,要想掌握透彻,需要逐个知识点--击破。本文介绍关于什么情况导致索引失效问题。
图片总结
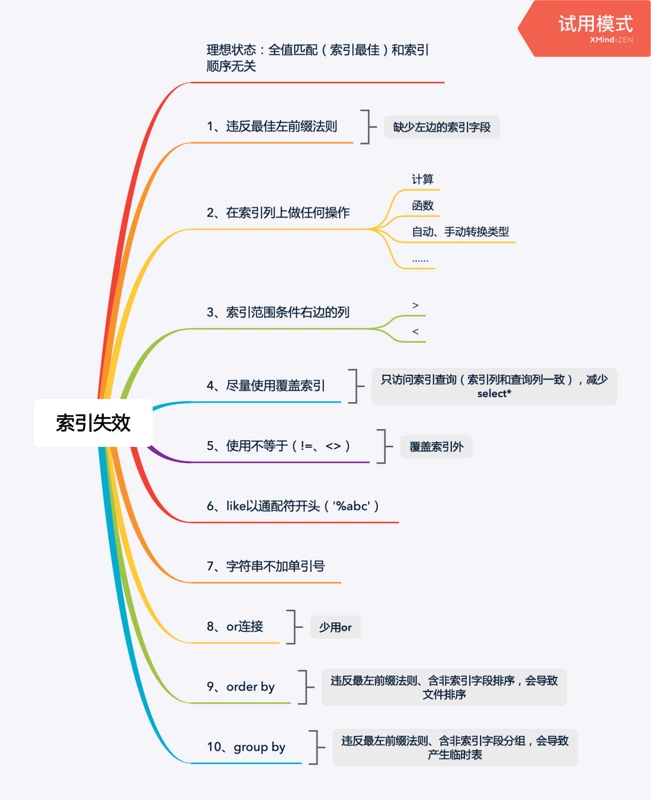
索引失效
全值匹配(索引最佳)


若主键索引和唯一索引都存在,优先主键索引。 没有主键索引 使用唯一索引。
1. 违反最左前缀法则
如果索引有多列(复合索引),要遵守最左前缀法则 即查询从索引的最左/前列必须存在,与顺序无关,查询从索引的最左前列开始并且不跳过索引中的列。
如下图,k1列是最左/前列,无论在哪个位置,都会使用到索引查询。

如下图,最左/前列k1不存在,索引失效,忽略了索引查询,启动了全表扫描。

2. 不要在索引列上做任何操作
如计算、函数、(自动or手动)类型转换等操作,会导致索引失效从而全表扫描。
如图,下面两个SQL结果集相同。
3. 索引范围条件右边的列
当SQL中出现范围性条件筛选,则在范围条件后面的索引条件失效。


4. 尽量使用覆盖索引
SQL中的查询列和条件中都为索引字段。

5. 不要使用不等于(!=、<>)
MySQL在使用不等于(!<>、<>)的时候无法使用索引会导致全表扫描(除覆盖索引外)

如果是覆盖索引

6. like相关SQL
① like通配符%出现在开头,会导致索引失效

② like通配符%出现在字符后面,不会导致索引失败

7. 字符串不加单引号索引失效
加单引号

不加单引号

8 or连接
尽量少用or

9. order by
备注:索引有两个作用:排序和查找
① 索引参与了排序,正常使用索引

② 导致额外的文件排序(会降低性能)
explain select * from user where k1 ='werew' order by k3; //违反最左/前法则,顺序不对,k1之后为k2,但是order by 后为k3
explain select * from user where k1 ='ewrew' order by k2,address; //含非索引字段,address不是索引字段

10. group by
备注:分组之前必排序
① 索引参与了排序,正常使用索引

② 导致产生临时表(降低性能)
explain select * from user where k1 ='werew' group by k3; //违反最左/前法则,顺序不对,k1之后为k2,但是order by 后为k3
explain select * from user where k1 ='werew' group by k2,address; //含非索引字段,address不是索引字段

查询优化
1. 小表驱动大表
小的数据集驱动大的数据集。
·

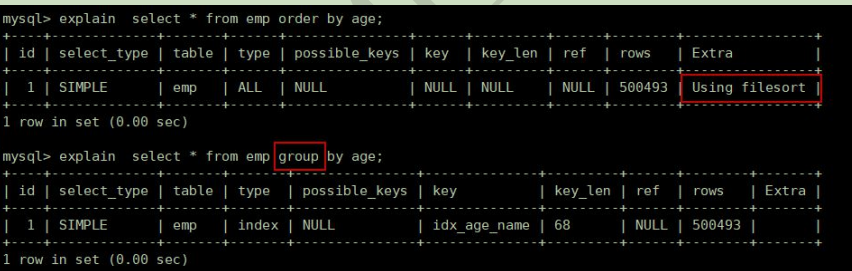
2. order by关键字排序
MySQL支持两种方式的排序:FileSort和Index,Index效率高。
index指MySQL扫描索引本身完成排序;filesort方式效率较低。
order by满足两种情况,会使用Index方式排序:
1. order by语句使用索引最前列
2. 使用where子句与order by子句条件列组合满足索引最左前列原则

3. group by
4. 排序算法
如何优化?
①增大 sort_butter_size 参数的设置
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的 1M-8M 之间调整。②增大 max_length_for_sort_data 参数的设置mysql 使用单路排序的前提是排序的字段大小要小于 max_length_for_sort_data。提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出 sort_buffer_size 的概率就增大,明显症状是高的磁盘 I/O 活动和低的处理器使用率。(1024-8192 之间调整)。③减少 select 后面的查询的字段。当 Query 的字段大小总和小于 max_length_for_sort_data 而且排序字段不是 TEXT|BLOB 类型时,会用改进后的算法——单路排序, 否则用老算法——多路排序。两种算法的数据都有可能超出 sort_buffer 的容量,超出之后,会创建 tmp 文件进行合并排序,导致多次 I/O,但是用单路排序算法的风险会更大一些,所以要提高 sort_buffer_size。