前言
Openfire的单机并发量,一直是一个比较含糊的东西,即使官方也没有很清楚的介绍。但按我自已评估,以4核、8G内存这样的机器配置,5万+的并发应问题不大。而当用户体量逐步上涨,前期可以通过扩容的方式提升性能,但若体量足够大,如几十万并发,单机的扩容已不是首选的方案,一来考虑性价比,二来如果整套系统跑在一台机器上,出现异常可能会波及所有在线的用户,用户感受极差。这时候,就需要把系统的压力分摊到多个服务器上,这就是集群。
集群的引入,是为了解决单机的并发瓶颈,在多个服务器上,分别运行Openfire实例,并进行数据共享,使得多台机器的协作运行效果,与单机一样。
而优秀的集群系统,不仅仅能提升性能,而且能自我管理。当其中某台机器出现异常,将触发集群的维护机制,比如剔除该异常节点,为系统的稳定性提供保障。
Openfire为集群的接入提供了透明接口,可以通过添加插件的形式实现集群。
具体Openfire的集群机制是如何,我们在后面的章节再来分析,本章主要讲解集群的配置,使用的集群插件是:Hazelcast。
硬件说明
1、两台服务器
IP1:192.168.5.1 IP2:192.168.5.2
2、Mysql数据库,安装在服务器1
数据地址:192.168.5.1:3306
插件安装与配置
1、安装插件:Hazelcast Plugin,直接在Openfire管理后台安装即可。
2、配置:
(1)两台Openfire服务器配置相同的域
(2)连接同一个数据库
(3)服务器的集群配置:
服务器1:
<join> <multicast enabled="false"> <multicast-group>224.2.2.3</multicast-group> <multicast-port>54327</multicast-port> </multicast> <tcp-ip enabled="true"> <member>192.168.5.2:5701</member> <member>192.168.5.1:5701</member> </tcp-ip> <aws enabled="false"/> </join> <interfaces enabled="true"> <interface>192.168.5.1</interface> </interfaces>
服务器2:
<join> <multicast enabled="false"> <multicast-group>224.2.2.3</multicast-group> <multicast-port>54327</multicast-port> </multicast> <tcp-ip enabled="true"> <member>192.168.5:1:5701</member> <member>192.168.5.2:5701</member> </tcp-ip> <aws enabled="false"/> </join> <interfaces enabled="true"> <interface>192.168.5.2</interface> </interfaces>
说明:其中member中是集群中各节点的IP地址和端口号,interface中是当前机器的IP地址。
(4)在Openfire控制台,Server-->Clustering-->Clutering Enabled中,选择Enabled,保存,集群启动。
测试
使用两个客户端,分别登录两个机器,如果客户端能进行通信,则集群功能已经具备。
(1)在任意一台服务器,登录Openfire管理后台,创建两个用户如:10023、10024
(2)在另一台服务器的管理后台用户列表,即可看到刚刚创建的用户
(3)在两台PC机,用Spark分别登录上面两个帐号,注意设置连接不同的主机:
客户端 1 连接服务器 1(下图为Spark高级设置界面):
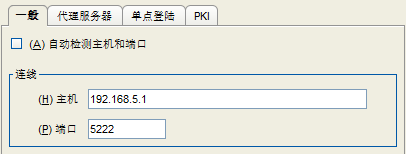
客户端 2 连接服务器 2:
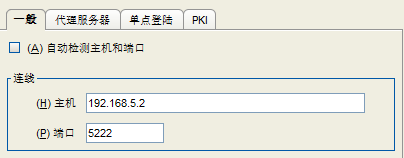
(4)测试互发消息,若能完成通信说明集群OK。
说明
本章节以最简化了的操作,配置Openfire集群,仅是为验证Openfire集群的可行性,并为后续的分析做准备。
但实际使用中,要使不同的客户端连接分配到不同的服务器,需要加入一台服务器,作为负载均衡,可安装开源的负载均衡组件Haproxy,或者用nginx都可以。
另外,数据库方面,实际的Openfire集群中,数据库也应是集群使用。
下一章,集群分析
OVER!