相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量的相关密切程度。
相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
相关系数在[-1,1]之间。
一、图示初判
通过pandas做散点矩阵图进行初步判断
df1 = pd.DataFrame(np.random.randn(200,4)*100,columns=['A','B','C','D']) pd.plotting.scatter_matrix(df1,figsize=(12,12),diagonal='kde',marker='o',range_padding=0.1)
二、Pearson相关系数(皮尔森相关系数)
前提条件:数据满足正太分布
皮尔森相关系数,也称皮尔森积矩相关系数,是一种线性相关关系。
衡量向量相似度的一种方法,输出范围为-1到1,0,0代表无相关性,负值为负相关,正值为正相关。
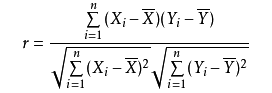
公式意义:分子为,(x-x的均值) 乘以 (y-y的均值)的累计和;分母为,(x-x的均值)的累计和的平方根 乘以 (y-y的均值)的累计和的平方根
|r| <= 0.3 → 不存在线性相关
0.3 < |r| <= 0.5 → 低度线性相关
0.5 < |r| <= 0.8 → 显著线性相关
|r| > 0.8 → 高度线性相关
1.皮尔森相关系数的推导
from scipy import stats s1 = pd.Series(np.random.rand(100)*100).sort_values() s2 = pd.Series(np.random.rand(100)*50).sort_values() df = pd.DataFrame({'value1':s1.values,'value2':s2.values}) u1,u2 = df['value1'].mean(),df['value2'].mean() std1,std2 = df['value1'].std(),df['value2'].std() print('value1正太性检验结果:',stats.kstest(df['value1'],'norm',(u1,std1))) #需要先验证满足正太分布 print('value2正太性检验结果:',stats.kstest(df['value2'],'norm',(u2,std2))) df['(x-u1)*(y-u2)'] = (df['value1'] - u1) * (df['value2'] - u2) df['(x-u1)**2'] = (df['value1'] - u1) ** 2 df['(y-u2)**2'] = (df['value2'] - u2) ** 2 print(df.head(3)) r = df['(x-u1)*(y-u2)'].sum()/(np.sqrt(df['(x-u1)**2'].sum()) * np.sqrt(df['(y-u2)**2'].sum())) print('皮尔森相关系数为%.4f'%r)


value1正太性检验结果: KstestResult(statistic=0.09073501372253845, pvalue=0.36300244109659735) value2正太性检验结果: KstestResult(statistic=0.11608587123064174, pvalue=0.12471026010748129) value1 value2 (x-u1)*(y-u2) (x-u1)**2 (y-u2)**2 0 2.727329 0.101045 1163.135987 1864.420003 725.633345 1 4.566353 0.296802 1105.504546 1708.987866 715.125206 2 6.132681 0.308134 1063.167351 1581.937521 714.519254 皮尔森相关系数为0.9699
2.pandas的corr()方法
上述方法为计算过程,可使用pandas的corr()方法直接生成相关系数矩阵
s1 = pd.Series(np.random.rand(100)*100).sort_values() s2 = pd.Series(np.random.rand(100)*50).sort_values() df = pd.DataFrame({'value1':s1.values,'value2':s2.values}) r = df.corr() #参数默认为pearson print(r) # value1 value2 # value1 1.000000 0.988596 # value2 0.988596 1.000000
三、Sperman秩相关系数(斯皮尔曼相关系数)
皮尔森相关系数只能用于分析服从正态分布的连续变量的相关性,对于不服从正态分布的变量,可采用Sperman秩相关系数进行相关性分析。
Sperman秩相关系数,也称等级相关系数。如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或−1。
计算逻辑:对两个变量的取值按照从小到大顺序编秩,如果两个值大小相等,则秩次为(index1+index2)/2,
1.spearman相关系数的推导
df = pd.DataFrame({'智商':[106,86,100,101,99,103,97,113,112,110],'每周看电视小数':[7,0,27,50,28,29,20,12,6,17]})
n = len(df)
df.sort_values('智商',inplace = True)
df['range1'] = np.arange(1,n+1)
df.sort_values('每周看电视小数',inplace = True)
df['range2'] = np.arange(1,n+1)
df['d'] = df['range1'] - df['range2']
df['d**2'] = df['d'] ** 2
rs = 1 - 6 * (df['d**2'].sum())/(n*(n**2-1))
print('斯皮尔曼相关系数为%.4f'%rs)
# 斯皮尔曼相关系数为-0.1758
2.pandas的corr()方法
corr()默认为pearson相关系数,添加参数method='spearman'转化为spearman相关系数。
df = pd.DataFrame({'智商':[106,86,100,101,99,103,97,113,112,110],'每周看电视小数':[7,0,27,50,28,29,20,12,6,17]})
rs = df.corr(method='spearman')
print(rs)
# 智商 每周看电视小数
# 智商 1.000000 -0.175758
# 每周看电视小数 -0.175758 1.000000