先简单介绍一下编码的情况,我们都知道机器上显示的字符最终存在计算机内存里都是以二进制码的形式存在的。
最开始的计算机字符只能用ASCII编码的方式去存储,而一个ASCII码占用一个字节,也就是说ASCII编码最多只能编码256个字符(键盘上所有的半角字符)。 但为了表示别的国家文字,就必须对原有的字符编码方式进行扩充。而对于中文来说,主要有两种编码方式,分别是gb2312和gbk,前者主要是用于编码简体中文字符,而后者除了简体中文字符还包括繁体中文字符。计算机迅速国际化之后,编码便不能只局限于英文字符和中文字符,于是出现了一个叫Unicode编码的方式,这种编码方式对每个字符都使用四个字节的方式存储,这样一来就足够表示所有字符了,但事实上所有的半角字符我们只需要1个字节来表示便足够了,全部字符都用Unicode编码方式的话,很容易造成资源浪费的情况,所以作为折中的考虑,UTF-8逐渐成为全球的流行的编码标准,UTF-8编码能够根据字符分别不同的字节大小,英文字符依然用一个字节表示,而中文有些则是两个字节表示,有些则是三个字节。
本文直接通过三个例子来讲解字符编码和解码的原理:
- 记事本字符的编码
- 前端页面中的<meta charset='utf-8'>
- 编程语言中读写文件的编码(python3.x)
顾名思义,编码就是把一个字符编码成二进制码存起来的方式,而解码就是把这个二进制码按照原本编码的规则还原成原来的字符。
1. 记事本字符编码
当我们打开记事本,然后打下一行字符的时候,对机器来说都是一串不可识别的字符,于是我们保存的时候,就是要对这些我们输入的字符进行编码了。如果你输入一串非英文字符,计算机会提醒你有些字符不能正确编码(windows中文版的话没有这种情况,因为你按下ctrl+s计算机会有一个默认的中文编码方式,则没有出现无法编码的情况。此处指的是英文版操作系统,当然中文操作系统也可以自主选择编码方式的,请往下看~),如下图:
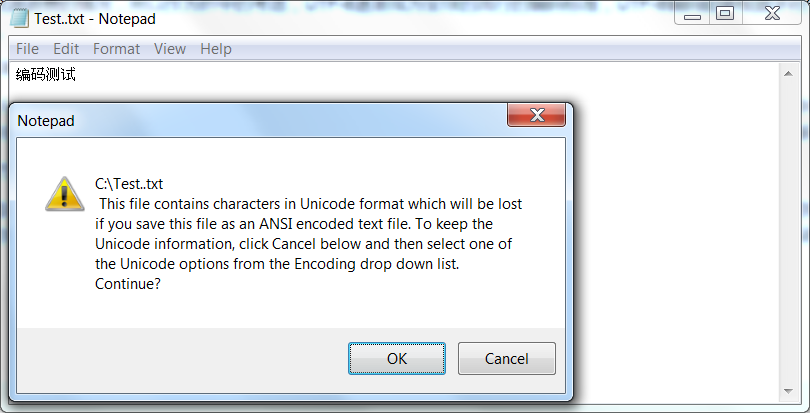
这个提示是说,如果你把这个文本保存为ANSI编码的文本文件时,有些Unicode字符会丢失,问你是否确定,我们先点ok保存,看看文本效果:
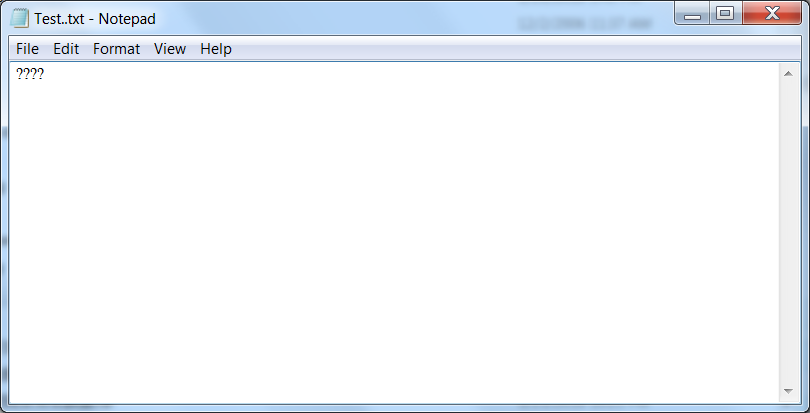
当我们去打开的时候,和编码相对的概念,解码就要用到了,系统会检测到这个文本是一个ANSI文本,于是用ASCII编码方式去解码,结果无法正常解析,出现乱码,情理之中。(这是英文系统会出现的步骤,中文系统的测试由此处开始)。
我们删除这个文件,重新建立一个,然后输入同样的内容,此时不要直接保存,点击 【文件】-->【另存为】,下面有选择编码的下拉列表,我的机器记事本只能使用四种编码方式(如下所示)
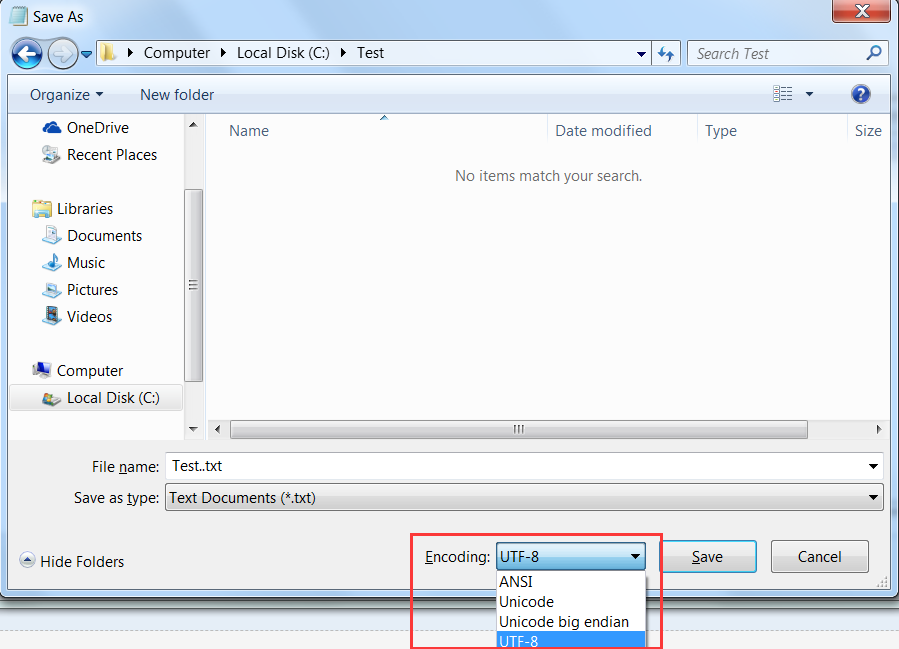
我们选择UTF-8,保存,没有出现任何提示,打开文本,内容正常显示(如下图所示)。

2. 前端页面中的<meta charset='utf-8'>
然后我们注意到写网站的时候我们会写<meta charset='utf-8'>,这里指定的utf-8是指定编码方式还是解码方式呢,其实都不是,由上面所述,编码方式取决于我们写完文本之后保存所选择的编码方式。而浏览器解码呢,取决于浏览器的设置(这个表述并不准确,请往下看,就会明朗),这个设置当然也是可以自己修改的,在这里:
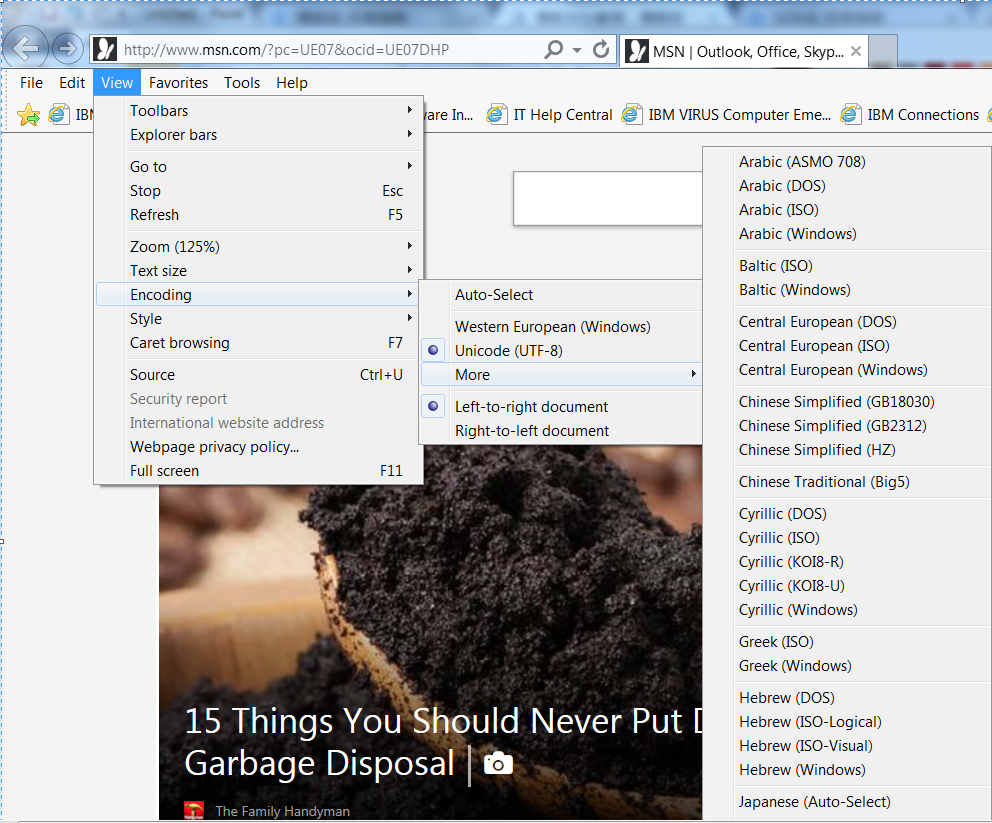
咦,怎么还有这个东西~
回到前面meta里面指定的编码有什么用呢,这里的编码是你手工告诉浏览器说你这个网页是使用什么编码去保存的,然后用浏览器去打开的时候,浏览器会用本身设置的编码方式去解码内容,当遇到<meta charset='utf-8'>的时候,浏览器会放弃设置中的方式,改用你指定的charset去解码内容,以保证内容都能正常显示,下面我们来测试一下:
新建一个Test.html,用notepad++(为了方便)打开,选择编码方式为gb2312(nodepad++设置:【编码】-->【编码字符集】-->【中文】->【GB2312】),然后写下代码(如下图所示),在这里我们“骗”浏览器说我们用utf-8编码(但事实上我们是用GB2312啊):

然后用ie打开看看效果:
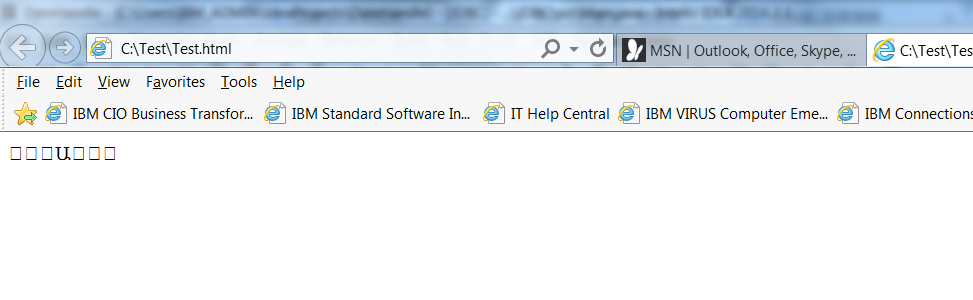
浏览器“被骗“之后,果然不能正确解码内容了,然后我们此时强制把浏览器的编码方式设置为GB2312,不能刷新(为什么?),结果如下: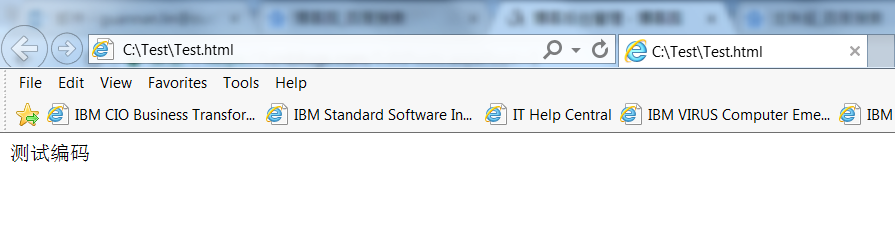
我们不管浏览器了,编辑Test.html,保存编码方式为UTF-8,然后刷新(此时浏览器编码方式还是GB2312),浏览器解析到<meta charset='utf-8'>的时候,则使用utf-8编码方式,结果就能正常显示.了...
3. 编程语言中读写文件的编码
在学习过程中,很多人会抛出一串乱码求解决方案,而很多人的建议就是使用UTF-8,反正不知道为什么,编码错了,就用UTF-8试试,当改成UTF-8之后(python中就是在文件第一行加上#encoding:utf-8或者对字节码使用.decode('utf-8')之类),还不能成功的话,接下来就不知道怎么做了。 这种做法都只是碰运气尝试,并没有针对性修改,当理解了这种情况之后,面对编码问题并不难解决。
既然问题是从python学习过程中跑出来的,那就用python再写一个例子好了,用open去写文件的时候可以传入一个encoding参数用于指定编码方式,同样的,读文件的时候encoding参数就视作解码方式。我们编写以下python代码:
path = r'C:Test est.txt' with open(path, 'w', encoding='gb2312') as f: f.write("测试编码") with open(path, 'r', encoding='utf-8') as f: print(f.read())
运行查看结果,很明显吧,解码错误~
 我们用UTF-8去解码文本,结果报错说这不是UTF-8编码。
我们用UTF-8去解码文本,结果报错说这不是UTF-8编码。
把代码 with open(path, 'r', encoding='utf-8') as f: 修改为 with open(path, 'r', encoding='gb2312') as f: ,重新运行py文件运行,结果如下
![]()
如果一开始我们不加encoding这个参数,打印的内容也能正常显示,由上述可知,当我们打开一个文件的时候,系统检测到这个文件的编码方式,然后去解码文件内容的,但我们在用python读文件的时候并没有去“打开文件“这个步骤啊, 这就需要用到上述提到的#encoding:utf-8的作用了,这句注释指定了我们当前py文件的默认编码方式,我们编写py文件的时候,都有一个默认的编码方式,然后这份代码的编码和解码(如果没有特别指定的话),都会按照这个方式来进行,这就解释了我们读的时候是应该是字节码,打印出来却是字符的原因了,是python解释器用默认编码方式解码,帮我们做了这个步骤。
同样的道理,我们去爬一个网页内容的时候也是,爬到的是字节码,然后我们要调用decode()方法对字节码进行解码,所以现在就知道如果出现乱码,原因应该从哪里找起了吧,并不是都是简单一句“试试UTF-8”就能解决所有情况的。
至此,以上为本人对字符编码与解码的一些拙见,如有不妥之处,敬请提出斧正。
尊重知识产权,转载引用请通知作者并注明出处!