主要针对第三单元的三次作业
JML语言的理论基础、应用工具链情况
JML指的是Java建模语言,全称是Java modeling language,是一种行为接口规范语言,可用于指定Java模块的行为。它结合了Eiffel的契约方法设计和Larch系列接口规范语言的基于模型的规范方法,以及细化演算的一些元素
Design by Contract with JML(由Gary T. Leavens和Yoonsik Cheon撰写)的草案解释了JML作为Java合同设计(DBC)语言的最基本用法,这个草案应该就是JML的使用规范,也就是告诉我们JML应该怎么写,一些关于JML的语法
JML是一个开放项目,有许多使用了JML的开源工具,如断言检查编译器(jmlc),单元测试工具(jmlunit)等
个人认为JML在应用时有这几种情况:(1)代码(接口)实现前,先写好JML,描述好规格,这样能更加精确地描述代码所要完成的任务,实现规格化的设计
(2)代码进行完善,增加新功能时,同时对JML进行更新,这样能减少随着应用程序的进展而引入错误的机会,产生始终与应用程序代码保持同步的精确文档
(3)代码已经实现,根据代码写JML,这样能大大提高代码的可维护性,在别人接手你的项目时不会是一头雾水,知道你写的这些东西都是干什么的,并且加以应用
(参考)
部署JMLUnitNG/JMLUnit,实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
尝试学习使用jmlunit,但是没学会。
看了讨论区的帖子,写了一个很简单的Test,可以用JMLUnitNG生成这些文件:

可能自己的操作有误,许多文件都有错误,错误也没太看懂,不知道该怎么处理...
用javac编译生成文件,报了100个错误,好像是运行Test_JML_Test就会自动生成测试样例。这部分实在有点懵,在网上查了很久也没查到,好像关于JML的东西不是很多
架构设计梳理,迭代中对架构的重构分析
这次作业的架构相比之前应该是比较清晰的,因为主要的业务部分官方已经给出,而且具体要实现的类也给了,我们只需要根据JML实现接口定义的方法完成他们。不像之前从头到尾都得自己写,写着写着可能就变得一片混乱......
这三次作业是对于node,path功能的不断扩充,从最基本的容器,到一个图,一个地铁系统;从一个比较虚的东西逐渐扩展到实际生活,难度也逐渐提升,但一切还是基于这两个小东西。同时因为用到了接口,每次在写新的Myxxxx类时可以进行许多代码的复用,只要复杂度(使用的算法)没什么太大问题,应该可能大概也许不需要重构吧。如果需要重构应该也不是完全的重构。三次作业,主要有三个类,以第一次的PathContainer为基础,每次的类在此基础之上不断进行完善,他们相互独立但是又相互联系,每个类都能够相对独立地实现自己的功能。还有一个path类,主要用来管理path自己的node,也实现了各个node、path的独立。看了标程,也能看出整体的架构是基于功能进行设计的,这样才能实现各个部分功能独立,大大增加了代码的扩展性和可维护性。但不仅如此,标程对层次的划分也很细节,比如数据结构层、缓存、建模层等,我在写的时候把这些都揉在一起了,就显得有些臃肿,这确实很值得学习。“设计父类时,应该充分考虑未来的扩展性”(来自README),我这方面的意识比较垃圾薄弱,经常有一种“应该没什么能扩展的”的念头。一是因为只是为了完成作业,比较懒,二是没接触过真正的项目、工程设计,对于这种未来可能的需求没有具体的概念。这一点现在可能影响不大,但在以后实际应用时一定有很大的帮助
还有一点就是在每次写新的应用类时,可以继承上一个类并且实现新的接口,也可以不继承,只实现接口然后CtrlC + CtrlV......一开始我是直接复制的,虽说没什么限制可以根据个人喜好选择,但是这样会使一个类很臃肿,而且功能的独立性不强,可维护性比较低,没有体现出OO的特点。
第一次作业UML类图如下:
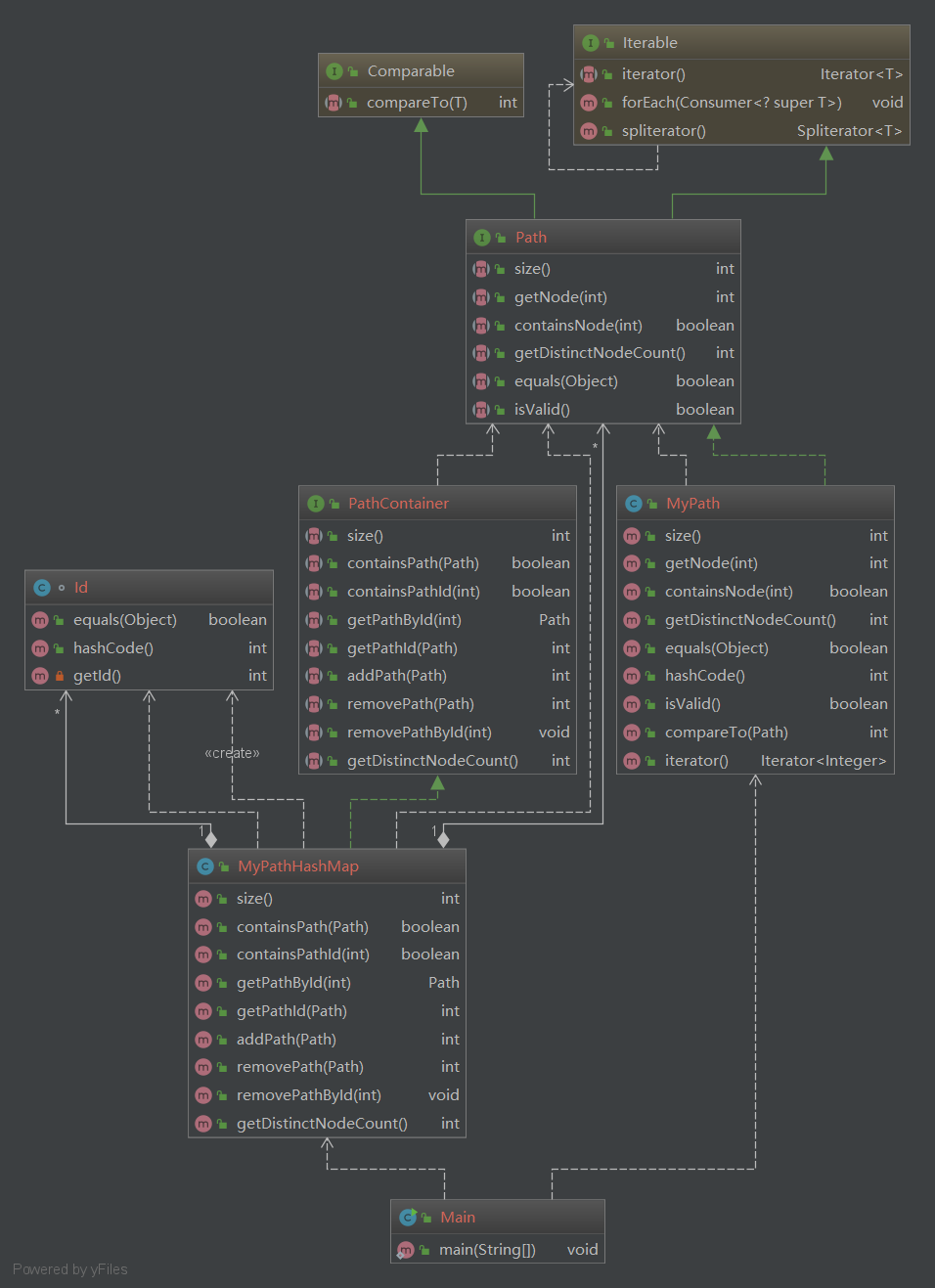
第二次作业:
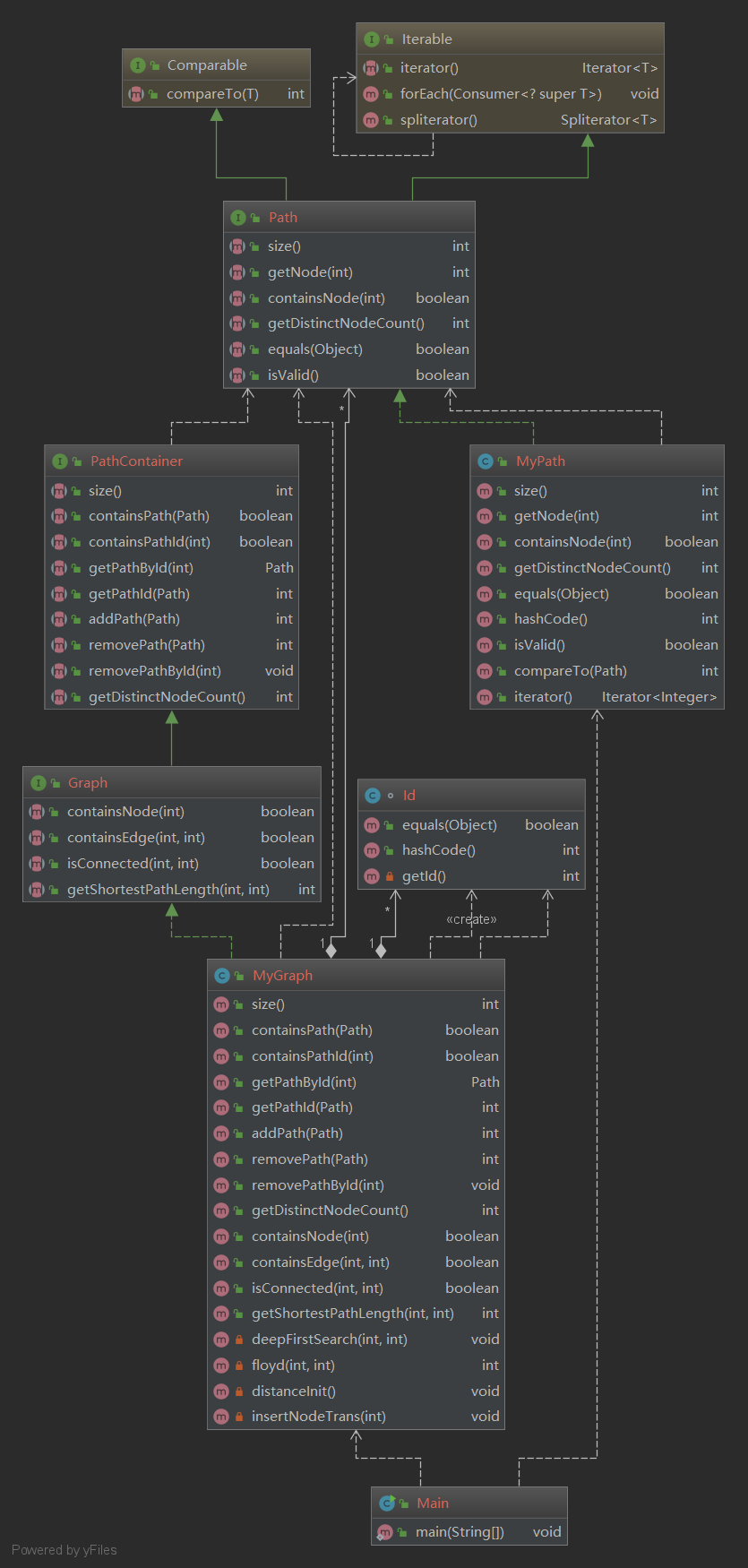
第三次作业:

根据作业分析代码实现出现的bug和修复情况
这次的作业主要有两种错误:WA和TLE,好像还出现了一种MLE的错误,可能是写算法的时候内存开的太大了之类的......
首先是第一次作业,一开始写了两个版本,一个是单纯地用Arraylist实现,另一个用HashMap实现。因为之前对HashMap使用的比较少,习惯用Arraylist,怕HashMap写错,因此提交了Arraylist的版本,结果有几个点TLE了。但提交HashMap版本后依旧是TLE,最后发现是没写一种类似缓存的东西,如对于不同node总数的记录,避免每次执行命令时都要计算一遍,这样的复杂度非常大,数据量一大肯定顶不住。不过事实也是如此,自己在写代码时对复杂度的关心程度不是很高,总是想着“能实现就好,对了就行”,以后还是得注意一下复杂度这个东西,以及避免一些无用的重复操作,不然总有一天会出错
第二次作业是彻彻底底的炸了,强测15个点全是WA,然后发现是算法开始之前忘初始化了......虽然只是缺了几行代码,但导致了程序全部出错。这个问题在之前学C时也犯过,除了自己不够细心之外,也说明了自己的测试数据太弱,量不够,针对性也不够强。这种错误不容易发现,还容易蒙混过关,因为有时候可能会碰巧正确,但终究是个遗患
第三次作业一开始不太会写,只会求个连通块。最后几天在讨论区看了看同学提供的一些思路,才会写一些。这回主要是建图,图建出来的话后面的就比较简单了,我的建图只建对了一半,对于一条path中出现相同的重复的node会出错。在讨论区发现可以把每条path单独作为一个图,跑Dij,再和其他path构成一整个图,对于不同的问题,只需要修改不同的权值。(讨论区是个好东西,得多看)
通过这三次作业,还有两次实验上机,对JML有了一个初步的认识,也对所谓的规格有了比较确切的认识。
在面对比较庞大的工程时,往往都是每个人负责不同的部分,最后将这些部分整合在一起,完成整个项目。就如同这一次,我们负责完成的MyPath,MyPathContainer,Myxxxx类。这些类中的每个需要实现的方法,在接口中都有相应的JML进行规格描述,我们则根据规格中叙述的前置条件,后置条件等进行完善即可。在完善时,我可以清楚地知道,每个方法的作用是什么,可能带来的结果是什么,我只需要注意我的实现方式,以及代码逻辑的正确性。就像指导书中说的“只要代码实现严格满足JML,就能保证正确性”。JML像是一张蓝图,就像OS中的Makefile在代码实现之前,就已经布置好各部分(方法)的用途。但是也因此产生了一个问题,如果JML写的有问题怎么办。其实这个问题不是特别大,比代码写错了debug简单一些。因为我们在完善这个方法时,首先就已经大致推测出这个方法的作用了,在根据JML实现时也会带入自己的思考,思考这样写到底能不能达到目的,像这几次就有一些同学指出了官方JML可能带有的问题,并且进行了改正。如果代码已经完成,结果在某一天发现有错误,那这个错误可能就很难找出来了
同时,因为有了JML的规范限制,在想增加程序功能时也显得更容易,代码的可扩展性得到了提高。另外,从这几次作业中也感觉到,想写出一个正确的完整的JML还是非常难的,而且写起来会非常复杂,甚至比代码难。比如说起来很简单的“从A到B的最低票价,最少换乘”,JML写起来就要写好几行。但也因为有了JML,代码实现就变得简单了一些,代码和JML相辅相成
总之,规格化设计对我们今后的帮助一定会很大,在面对一定规模的设计时,一定要想起规格化这个东西,别总是按照自己想的去做(别带着一种“我这样写他能看不懂?”的心情)