一、源码解析
1、 LinkedList类定义
2、LinkedList数据结构原理
3、私有属性
4、构造方法
5、元素添加add()及原理
6、删除数据remove()
7、数据获取get()
8、数据复制clone()与toArray()
9、遍历数据:Iterator()
二、ListItr
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
为什么要继承自AbstractSequentialList ?
AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)这些骨干性函数。降低了List接口的复杂度。这些接口都是随机访问List的,LinkedList是双向链表;既然它继承于AbstractSequentialList,就相当于已经实现了“get(int index)这些接口”。
此外,我们若需要通过AbstractSequentialList自己实现一个列表,只需要扩展此类,并提供 listIterator() 和 size() 方法的实现即可。若要实现不可修改的列表,则需要实现列表迭代器的 hasNext、next、hasPrevious、previous 和 index 方法即可。
LinkedList的类图关系:
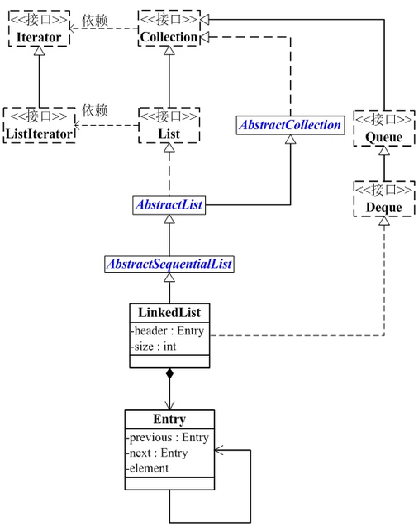
LinkedList底层的数据结构是基于双向循环链表的,且头结点中不存放数据,如下:

既然是双向链表,那么必定存在一种数据结构——我们可以称之为节点,节点实例保存业务数据,前一个节点的位置信息和后一个节点位置信息,如下图所示:

LinkedList中之定义了两个属性:
1 private transient Entry<E> header = new Entry<E>(null, null, null);
2 private transient int size = 0;
header是双向链表的头节点,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
size是双向链表中节点实例的个数。
首先来了解节点类Entry类的代码。
1 private static class Entry<E> {
2 E element;
3 Entry<E> next;
4 Entry<E> previous;
5
6 Entry(E element, Entry<E> next, Entry<E> previous) {
7 this.element = element;
8 this.next = next;
9 this.previous = previous;
10 }
11 }
节点类很简单,element存放业务数据,previous与next分别存放前后节点的信息(在数据结构中我们通常称之为前后节点的指针)。
LinkedList的构造方法:
1 public LinkedList() {
2 header.next = header.previous = header;
3 }
4 public LinkedList(Collection<? extends E> c) {
5 this();
6 addAll(c);
7 }
LinkedList提供了两个构造方法。
第一个构造方法不接受参数,将header实例的previous和next全部指向header实例(注意,这个是一个双向循环链表,如果不是循环链表,空链表的情况应该是header节点的前一节点和后一节点均为null),这样整个链表其实就只有header一个节点,用于表示一个空的链表。
执行完构造函数后,header实例自身形成一个闭环,如下图所示:
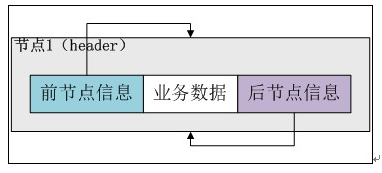
第二个构造方法接收一个Collection参数c,调用第一个构造方法构造一个空的链表,之后通过addAll将c中的元素全部添加到链表中。
1 public boolean addAll(Collection<? extends E> c) {
2 return addAll(size, c);
3 }
4 // index参数指定collection中插入的第一个元素的位置
5 public boolean addAll(int index, Collection<? extends E> c) {
6 // 插入位置超过了链表的长度或小于0,报IndexOutOfBoundsException异常
7 if (index < 0 || index > size)
8 throw new IndexOutOfBoundsException("Index: "+index+
9 ", Size: "+size);
10 Object[] a = c.toArray();
11 int numNew = a.length;
12 // 若需要插入的节点个数为0则返回false,表示没有插入元素
13 if (numNew==0)
14 return false;
15 modCount++;//否则,插入对象,链表修改次数加1
16 // 保存index处的节点。插入位置如果是size,则在头结点前面插入,否则在获取index处的节点插入
17 Entry<E> successor = (index==size ? header : entry(index));
18 // 获取前一个节点,插入时需要修改这个节点的next引用
19 Entry<E> predecessor = successor.previous;
20 // 按顺序将a数组中的第一个元素插入到index处,将之后的元素插在这个元素后面
21 for (int i=0; i<numNew; i++) {
22 // 结合Entry的构造方法,这条语句是插入操作,相当于C语言中链表中插入节点并修改指针
23 Entry<E> e = new Entry<E>((E)a[i], successor, predecessor);
24 // 插入节点后将前一节点的next指向当前节点,相当于修改前一节点的next指针
25 predecessor.next = e;
26 // 相当于C语言中成功插入元素后将指针向后移动一个位置以实现循环的功能
27 predecessor = e;
28 }
29 // 插入元素前index处的元素链接到插入的Collection的最后一个节点
30 successor.previous = predecessor;
31 // 修改size
32 size += numNew;
33 return true;
34 }
构造方法中的调用了addAll(Collection<? extends E> c)方法,而在addAll(Collection<? extends E> c)方法中仅仅是将size当做index参数调用了addAll(int index,Collection<? extends E> c)方法。
1 private Entry<E> entry(int index) {
2 if (index < 0 || index >= size)
3 throw new IndexOutOfBoundsException("Index: "+index+
4 ", Size: "+size);
5 Entry<E> e = header;
6 // 根据这个判断决定从哪个方向遍历这个链表
7 if (index < (size >> 1)) {
8 for (int i = 0; i <= index; i++)
9 e = e.next;
10 } else {
11 // 可以通过header节点向前遍历,说明这个一个循环双向链表,header的previous指向链表的最后一个节点,这也验证了构造方法中对于header节点的前后节点均指向自己的解释
12 for (int i = size; i > index; i--)
13 e = e.previous;
14 }
15 return e;
16 }
下面说明双向链表添加元素的原理:
添加数据:add()
// 将元素(E)添加到LinkedList中
public boolean add(E e) {
// 将节点(节点数据是e)添加到表头(header)之前。
// 即,将节点添加到双向链表的末端。
addBefore(e, header);
return true;
}
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}
addBefore(E e,Entry<E> entry)方法是个私有方法,所以无法在外部程序中调用(当然,这是一般情况,你可以通过反射上面的还是能调用到的)。
addBefore(E e,Entry<E> entry)先通过Entry的构造方法创建e的节点newEntry(包含了将其下一个节点设置为entry,上一个节点设置为entry.previous的操作,相当于修改newEntry的“指针”),之后修改插入位置后newEntry的前一节点的next引用和后一节点的previous引用,使链表节点间的引用关系保持正确。之后修改和size大小和记录modCount,然后返回新插入的节点。
下面分解“添加第一个数据”的步骤:
第一步:初始化后LinkedList实例的情况:
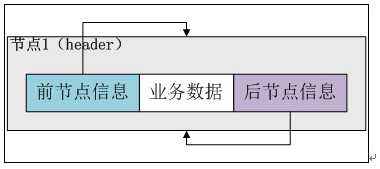
第二步:初始化一个预添加的Entry实例(newEntry)。
Entry newEntry = newEntry(e, entry, entry.previous);
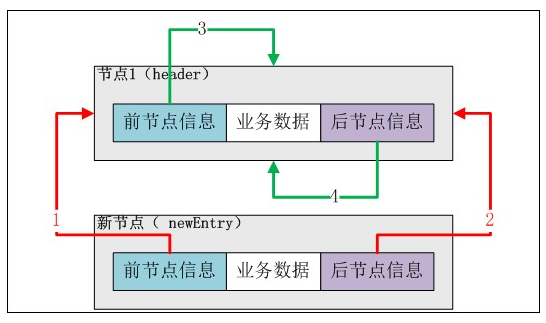
第三步:调整新加入节点和头结点(header)的前后指针。
newEntry.previous.next = newEntry;
newEntry.previous即header,newEntry.previous.next即header的next指向newEntry实例。在上图中应该是“4号线”指向newEntry。
newEntry.next.previous = newEntry;
newEntry.next即header,newEntry.next.previous即header的previous指向newEntry实例。在上图中应该是“3号线”指向newEntry。
调整后如下图所示:
图——加入第一个节点后LinkedList示意图
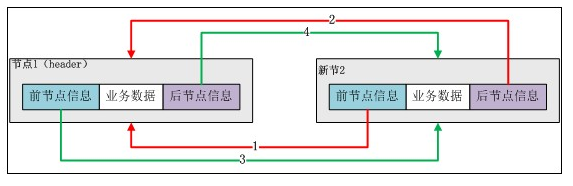
下面分解“添加第二个数据”的步骤:
第一步:新建节点。
图——添加第二个节点

第二步:调整新节点和头结点的前后指针信息。
图——调整前后指针信息

添加后续数据情况和上述一致,LinkedList实例是没有容量限制的。
总结,addBefore(E e,Entry<E> entry)实现在entry之前插入由e构造的新节点。而add(E e)实现在header节点之前插入由e构造的新节点。为了便于理解,下面给出插入节点的示意图。

public void addFirst(E e) {
addBefore(e, header.next);
}
public void addLast(E e) {
addBefore(e, header);
}
看上面的示意图,结合addBefore(E e,Entry<E> entry)方法,很容易理解addFrist(E e)只需实现在header元素的下一个元素之前插入,即示意图中的一号之前。addLast(E e)只需在实现在header节点前(因为是循环链表,所以header的前一个节点就是链表的最后一个节点)插入节点(插入后在2号节点之后)。
清除数据clear()
1 public void clear() {
2 Entry<E> e = header.next;
3 // e可以理解为一个移动的“指针”,因为是循环链表,所以回到header的时候说明已经没有节点了
4 while (e != header) {
5 // 保留e的下一个节点的引用
6 Entry<E> next = e.next;
7 // 解除节点e对前后节点的引用
8 e.next = e.previous = null;
9 // 将节点e的内容置空
10 e.element = null;
11 // 将e移动到下一个节点
12 e = next;
13 }
14 // 将header构造成一个循环链表,同构造方法构造一个空的LinkedList
15 header.next = header.previous = header;
16 // 修改size
17 size = 0;
18 modCount++;
19 }
数据包含 contains(Object o)
public boolean contains(Object o) {
return indexOf(o) != -1;
}
// 从前向后查找,返回“值为对象(o)的节点对应的索引” 不存在就返回-1
public int indexOf(Object o) {
int index = 0;
if (o==null) {
for (Entry e = header.next; e != header; e = e.next) {
if (e.element==null)
return index;
index++;
}
} else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element))
return index;
index++;
}
}
return -1;
}
indexOf(Object o)判断o链表中是否存在节点的element和o相等,若相等则返回该节点在链表中的索引位置,若不存在则放回-1。
contains(Object o)方法通过判断indexOf(Object o)方法返回的值是否是-1来判断链表中是否包含对象o。
几个remove方法最终都是调用了一个私有方法:remove(Entry<E> e),只是其他简单逻辑上的区别。下面分析remove(Entry<E> e)方法。
1 private E remove(Entry<E> e) {
2 if (e == header)
3 throw new NoSuchElementException();
4 // 保留将被移除的节点e的内容
5 E result = e.element;
6 // 将前一节点的next引用赋值为e的下一节点
7 e.previous.next = e.next;
8 // 将e的下一节点的previous赋值为e的上一节点
9 e.next.previous = e.previous;
10 // 上面两条语句的执行已经导致了无法在链表中访问到e节点,而下面解除了e节点对前后节点的引用
11 e.next = e.previous = null;
12 // 将被移除的节点的内容设为null
13 e.element = null;
14 // 修改size大小
15 size--;
16 modCount++;
17 // 返回移除节点e的内容
18 return result;
19 }
由于删除了某一节点因此调整相应节点的前后指针信息,如下:
e.previous.next = e.next;//预删除节点的前一节点的后指针指向预删除节点的后一个节点。
e.next.previous = e.previous;//预删除节点的后一节点的前指针指向预删除节点的前一个节点。
清空预删除节点:
e.next = e.previous = null;
e.element = null;
交给gc完成资源回收,删除操作结束。
与ArrayList比较而言,LinkedList的删除动作不需要“移动”很多数据,从而效率更高。
Get(int)方法的实现在remove(int)中已经涉及过了。首先判断位置信息是否合法(大于等于0,小于当前LinkedList实例的Size),然后遍历到具体位置,获得节点的业务数据(element)并返回。
注意:为了提高效率,需要根据获取的位置判断是从头还是从尾开始遍历。
// 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前先后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
注意细节:位运算与直接做除法的区别。先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历
clone()
1 public Object clone() {
2 LinkedList<E> clone = null;
3 try {
4 clone = (LinkedList<E>) super.clone();
5 } catch (CloneNotSupportedException e) {
6 throw new InternalError();
7 }
8 clone.header = new Entry<E>(null, null, null);
9 clone.header.next = clone.header.previous = clone.header;
10 clone.size = 0;
11 clone.modCount = 0;
12 for (Entry<E> e = header.next; e != header; e = e.next)
13 clone.add(e.element);
14 return clone;
15 }
调用父类的clone()方法初始化对象链表clone,将clone构造成一个空的双向循环链表,之后将header的下一个节点开始将逐个节点添加到clone中。最后返回克隆的clone对象。
toArray()
1 public Object[] toArray() {
2 Object[] result = new Object[size];
3 int i = 0;
4 for (Entry<E> e = header.next; e != header; e = e.next)
5 result[i++] = e.element;
6 return result;
7 }
创建大小和LinkedList相等的数组result,遍历链表,将每个节点的元素element复制到数组中,返回数组。
toArray(T[] a)
1 public <T> T[] toArray(T[] a) {
2 if (a.length < size)
3 a = (T[])java.lang.reflect.Array.newInstance(
4 a.getClass().getComponentType(), size);
5 int i = 0;
6 Object[] result = a;
7 for (Entry<E> e = header.next; e != header; e = e.next)
8 result[i++] = e.element;
9 if (a.length > size)
10 a[size] = null;
11 return a;
12 }
先判断出入的数组a的大小是否足够,若大小不够则拓展。这里用到了发射的方法,重新实例化了一个大小为size的数组。之后将数组a赋值给数组result,遍历链表向result中添加的元素。最后判断数组a的长度是否大于size,若大于则将size位置的内容设置为null。返回a。
从代码中可以看出,数组a的length小于等于size时,a中所有元素被覆盖,被拓展来的空间存储的内容都是null;若数组a的length的length大于size,则0至size-1位置的内容被覆盖,size位置的元素被设置为null,size之后的元素不变。
为什么不直接对数组a进行操作,要将a赋值给result数组之后对result数组进行操作?
LinkedList的Iterator
除了Entry,LinkedList还有一个内部类:ListItr。
ListItr实现了ListIterator接口,可知它是一个迭代器,通过它可以遍历修改LinkedList。
在LinkedList中提供了获取ListItr对象的方法:listIterator(int index)。
1 public ListIterator<E> listIterator(int index) {
2 return new ListItr(index);
3 }
该方法只是简单的返回了一个ListItr对象。
LinkedList中还有通过集成获得的listIterator()方法,该方法只是调用了listIterator(int index)并且传入0。
下面详细分析ListItr。
1 private class ListItr implements ListIterator<E> {
2 // 最近一次返回的节点,也是当前持有的节点
3 private Entry<E> lastReturned = header;
4 // 对下一个元素的引用
5 private Entry<E> next;
6 // 下一个节点的index
7 private int nextIndex;
8 private int expectedModCount = modCount;
9 // 构造方法,接收一个index参数,返回一个ListItr对象
10 ListItr(int index) {
11 // 如果index小于0或大于size,抛出IndexOutOfBoundsException异常
12 if (index < 0 || index > size)
13 throw new IndexOutOfBoundsException("Index: "+index+
14 ", Size: "+size);
15 // 判断遍历方向
16 if (index < (size >> 1)) {
17 // next赋值为第一个节点
18 next = header.next;
19 // 获取指定位置的节点
20 for (nextIndex=0; nextIndex<index; nextIndex++)
21 next = next.next;
22 } else {
23 // else中的处理和if块中的处理一致,只是遍历方向不同
24 next = header;
25 for (nextIndex=size; nextIndex>index; nextIndex--)
26 next = next.previous;
27 }
28 }
29 // 根据nextIndex是否等于size判断时候还有下一个节点(也可以理解为是否遍历完了LinkedList)
30 public boolean hasNext() {
31 return nextIndex != size;
32 }
33 // 获取下一个元素
34 public E next() {
35 checkForComodification();
36 // 如果nextIndex==size,则已经遍历完链表,即没有下一个节点了(实际上是有的,因为是循环链表,任何一个节点都会有上一个和下一个节点,这里的没有下一个节点只是说所有节点都已经遍历完了)
37 if (nextIndex == size)
38 throw new NoSuchElementException();
39 // 设置最近一次返回的节点为next节点
40 lastReturned = next;
41 // 将next“向后移动一位”
42 next = next.next;
43 // index计数加1
44 nextIndex++;
45 // 返回lastReturned的元素
46 return lastReturned.element;
47 }
48
49 public boolean hasPrevious() {
50 return nextIndex != 0;
51 }
52 // 返回上一个节点,和next()方法相似
53 public E previous() {
54 if (nextIndex == 0)
55 throw new NoSuchElementException();
56
57 lastReturned = next = next.previous;
58 nextIndex--;
59 checkForComodification();
60 return lastReturned.element;
61 }
62
63 public int nextIndex() {
64 return nextIndex;
65 }
66
67 public int previousIndex() {
68 return nextIndex-1;
69 }
70 // 移除当前Iterator持有的节点
71 public void remove() {
72 checkForComodification();
73 Entry<E> lastNext = lastReturned.next;
74 try {
75 LinkedList.this.remove(lastReturned);
76 } catch (NoSuchElementException e) {
77 throw new IllegalStateException();
78 }
79 if (next==lastReturned)
80 next = lastNext;
81 else
82 nextIndex--;
83 lastReturned = header;
84 expectedModCount++;
85 }
86 // 修改当前节点的内容
87 public void set(E e) {
88 if (lastReturned == header)
89 throw new IllegalStateException();
90 checkForComodification();
91 lastReturned.element = e;
92 }
93 // 在当前持有节点后面插入新节点
94 public void add(E e) {
95 checkForComodification();
96 // 将最近一次返回节点修改为header
97 lastReturned = header;
98 addBefore(e, next);
99 nextIndex++;
100 expectedModCount++;
101 }
102 // 判断expectedModCount和modCount是否一致,以确保通过ListItr的修改操作正确的反映在LinkedList中
103 final void checkForComodification() {
104 if (modCount != expectedModCount)
105 throw new ConcurrentModificationException();
106 }
107 }
下面是一个ListItr的使用实例。
1 LinkedList<String> list = new LinkedList<String>();
2 list.add("First");
3 list.add("Second");
4 list.add("Thrid");
5 System.out.println(list);
6 ListIterator<String> itr = list.listIterator();
7 while (itr.hasNext()) {
8 System.out.println(itr.next());
9 }
10 try {
11 System.out.println(itr.next());// throw Exception
12 } catch (Exception e) {
13 // TODO: handle exception
14 }
15 itr = list.listIterator();
16 System.out.println(list);
17 System.out.println(itr.next());
18 itr.add("new node1");
19 System.out.println(list);
20 itr.add("new node2");
21 System.out.println(list);
22 System.out.println(itr.next());
23 itr.set("modify node");
24 System.out.println(list);
25 itr.remove();
26 System.out.println(list);
1 结果:
2 [First, Second, Thrid]
3 First
4 Second
5 Thrid
6 [First, Second, Thrid]
7 First
8 [First, new node1, Second, Thrid]
9 [First, new node1, new node2, Second, Thrid]
10 Second
11 [First, new node1, new node2, modify node, Thrid]
12 [First, new node1, new node2, Thrid]
LinkedList还有一个提供Iterator的方法:descendingIterator()。该方法返回一个DescendingIterator对象。DescendingIterator是LinkedList的一个内部类。
1 public Iterator<E> descendingIterator() {
2 return new DescendingIterator();
3 }
下面分析详细分析DescendingIterator类。
1 private class DescendingIterator implements Iterator {
2 // 获取ListItr对象
3 final ListItr itr = new ListItr(size());
4 // hasNext其实是调用了itr的hasPrevious方法
5 public boolean hasNext() {
6 return itr.hasPrevious();
7 }
8 // next()其实是调用了itr的previous方法
9 public E next() {
10 return itr.previous();
11 }
12 public void remove() {
13 itr.remove();
14 }
15 }
从类名和上面的代码可以看出这是一个反向的Iterator,代码很简单,都是调用的ListItr类中的方法。
参考: