Requests库 (https://www.python-requests.org/) 是一个擅长处理那些复杂的 HTTP 请求、cookie、header(响应头和请求头)等内容的 Python 第三方库。
提交一个最基本的表单
大多数网页表单都是由一些HTML字段、一个提交按钮、一个在表单处理完之后跳转的“执行结果”(表单属性action的值)页面构成。
一个最简单的表单(http://www.pythonscraping.com/pages/files/form.html)
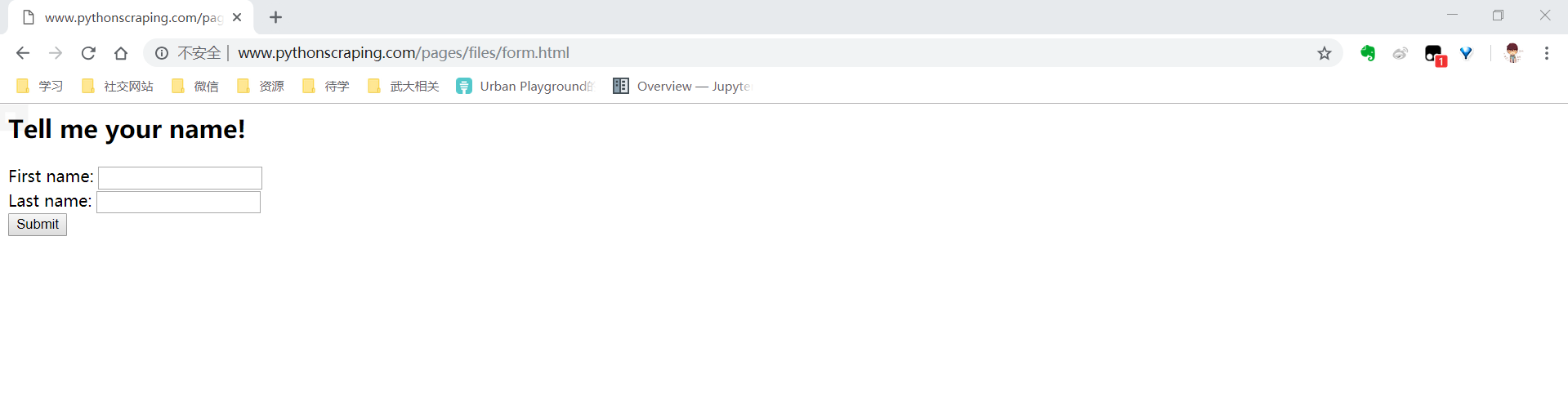
这个表单的源码在下面。可以通过chrome的开发者工具(F12)查看。
<form method="post" action="processing.php">
First name: <input type="text" name="firstname"><br>
Last name: <input type="text" name="lastname"><br>
<input type="submit" value="Submit" id="submit">
</form>
有几个要点:
- 两个要输入字段的名称是firstname和lastname。字段的名称决定了表单被确认后要被传送到服务器上的变量名称,要模拟表单提交数据的行为,就要保证变量名称与字段名称是一一对应的。
- 表单的真实行为其实发生在processing.php(绝对路径是http://www.pythonscraping.com/pages/files/processing.php)。表单的任何POST请求其实都发生在这个页面上,并非表单本身所在的页面。HTML表单的目的,知识帮助网站的访问者发送格式合理的请求,向服务器请求没有出现的页面。
那么提交这个最简单的表单,只要四行代码就可以了。
import requests
params = {'firstname': 'Ivy', 'lastname': 'Wong'}
r= requests.post("http://www.pythonscraping.com/pages/files/processing.php", data=params)
print(r.text)
表单提交后,程序应该会返回执行页面的源代码,包括这行内容。

提交文件和图像
在http://www.pythonscraping.com/files/form2.html有一个文件上传表单,表单的源代码是下面这样的。
<form action="../pages/files/processing2.php" method="post" enctype="multipart/form-data">
Submit a jpg, png, or gif: <input type="file" name="uploadFile"><br>
<input type="submit" value="Upload File">
</form>
发现input标签里有一个type属性是file,和文字其实差不多。
import requests
filess = {'uploadFile': open('..files/Python-logo.png','rb')}
r= requests.post("http://www.pythonscraping.com/pages/files/processing2.php", files=files)
print(r.text)
处理登录与cookie
大多数新式的网站都用cookies跟踪用户是否已登录的状态信息。一旦网站验证了你的登录权证,它就会将它们保存在你的浏览器的cookie中,里面通常包含一个服务器生产的令牌、登录有效时限和状态跟踪信息。网站会把这个cookie当作信息验证的证据,在你浏览网站的每个页面时出示给服务器。
Ryan Mitchell在http://www.pythonscraping.com/pages/cookies/login.html创建了一个简单的登录表单。

用户名可以是任意值,但是密码必须是"password"。
在简介页面,网站会监测浏览器的cookie,看它有没有页面已登录的设置信息。
import requests
params = {'username':'Ryan','password':'password'}
r=requests.post("http://www.pythonscraping.com/pages/cookies/welcome.php",params)
print("Cookie is set to:")
print(r.cookies.get_dict())
print("-----------------------")
print("Going to profile page...")
r=requests.get("http://www.pythonscraping.com/pages/cookies/profile.php",cookies=r.cookies)
print(r.text)
有些网站比较复杂,cookie经常暗自调整。那么可以用session函数。
import requests
session = requests.Session()
params = {'username':'Ryan','password':'password'}
r=session.post("http://www.pythonscraping.com/pages/cookies/welcome.php",params)
print("Cookie is set to:")
print(r.cookies.get_dict())
print("-----------------------")
print("Going to profile page...")
r=session.get("http://www.pythonscraping.com/pages/cookies/profile.php")
print(r.text)
会话(session)对象会持续跟踪会话信息,比如cookie、header,甚至包括运行HTTP协议的信息,比如HTTPAdapter。
修改请求头
HTTP的请求头是在你每次向网络服务器发送请求时,传递的一组属性和配置信息。HTTP定义了十几种古怪的请求头类型,不过大多数都不常用。只有下面的七个字段被大多数浏览器用来初始化所有网络请求。(表内是我的浏览器数据)
| 属性 | 内容 |
|---|---|
| Host | hpd.baidu.com |
| Connection | keep-alive |
| Accept | image/webp,image/apng,image/,/*;q=0.8 |
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36 |
| Referrer | https://www.baidu.com/ |
| Accept-Encoding | gzip, deflate, br |
| Accept-Language | zh-CN,zh;q=0.9 |
而经典的Python爬虫在使用urllib标准库时,都会发送如下的请求头:
| 属性 | 内容 |
|---|---|
| Accept-Encoding | indentity |
| User-Agent | Python-urllib/3.4 |
http://www.whatismybrowser.com/网站可以让服务器测试浏览器的属性。用下面的代码来采集这个网站的信息,验证我们浏览器的cookie设置:
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"}
url="https://www.whatismybrowser.com/developers/what-http-headers-is-my-browser-sending"
req=session.get(url, headers=headers)
bsObj = BeautifulSoup(req.text, "lxml")
print(bsObj.find("table",{"class":"table-striped"}).get_text)
和Ryan给的代码稍有点不一样,加上了BeautifulSoup要用lxml解析,可能是由于我的header和Ryan不一样。
通常真正重要的参数就是User-Agent。如果在处理一个警觉性非常高的网站,就要注意那些经常用却很少检查的请求头。
请求头还可以让网站改变内容的布局样式。例如,用移动设备浏览网站时,通常会看到一个没有广告、Flash以及其他干扰的简化的网站版本。
Ryan给了一个移动设备的User-Agent如下。
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, lke Gecko) Version/7.0 Mobile/11D257 Safari/95
37.53
【参考】
[1]《Python网络数据采集》Ryan Mitchell