第II节简要介绍与本文有关的先前工作
第III节介绍文中使用的定义以及术语
第IV节介绍如何从原始ASR lattices中生成倒排索引结构
第V节详细介绍了ASR结构以及实验使用的数据
第VI节提供了在一个大数据集之上,提出的倒排索引结构
的STD实验评估。
第VII节总结倒排索引结构的优点以及未来展望
IV 带权自动机的时间因子转换器
本节提出了一种为大数据集语料库构建时间索引的有效算法。在解决了[15]中的非确定性因子转换器相关的问题之后,我们提出了一种因子转换器结构——时间因子转换器
(TFT),弧(arc)的权重存储时间信息。为了便于比较,本文基于[2]进行开发。
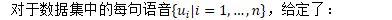
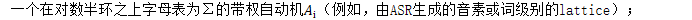


Timed Factor Transducer of Weighted Automata
factor(因子,substring),子字符串,子串
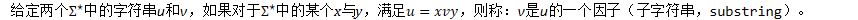
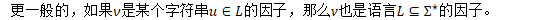

为大语音数据集构造一种有效的时间系数的算法,提出了一种新的因子转换器结构——基于时间的因子转换器(TFT)。
问题在于如何创建一个基于时间的索引,可用于被这些自动机接收的任意字符串的任意因子的直接搜索。
核心想法是,通过带权有限状态转换器T将每个因子进行映射,因子的时间索引可以表示为:
- 该因子所属的多个自动机的集合;
- 因子在每个自动机中间隔的开始-结束时间;
- 在对应时间间隔中实际出现在对应自动机中的后验概率;
- 预处理:对每个输入自动机进行预处理,以获得一个后验Lattice,其中不重叠的弧集被分别标记;
- 构建时间因子转换器:对每个处理过的输入自动机中,构造一个能确切识别输入因子集的中间因子转换器;
- 因子选择:将这些中间因子转换器转换为确定性转换器,方法是用消歧符号对每个因子进行扩展,然后应用加权自动机优化;
- 在时间因子转换器中搜索:对这些确定性转换器进行合并、进一步优化,以获得整个数据集的确定性倒排索引。
以下详述算法的各个阶段
- 预处理

由[2]给出的算法为语句中出现的所有因子生成索引项(一个因子生成一个索引)。这是SUR(话语检索)问题的理想做法。对于STD(话语检测),我们希望为非重叠事件(occurrences)保留单独的索引项,以确保包含查询条件的确切时间间隔。这种分离可以通过对具有相同输入标签和重叠时间跨度的弧进行聚类来实现。
聚类算法如下。对于每个输入标签:
1)根据结束时间对收集的二元组(开始时间,结束时间)进行排序;
2)确定最大的一组不重叠的二元组(开始时间,结束时间)并将它们分配为簇头;
3)根据最大重叠分类剩余的弧。
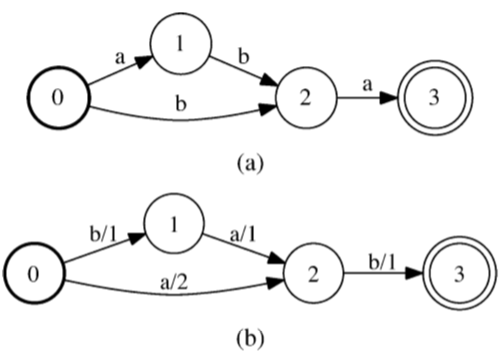
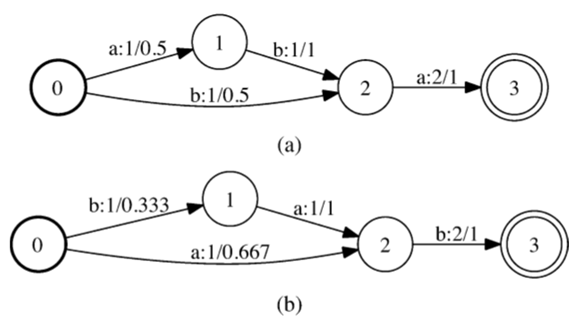
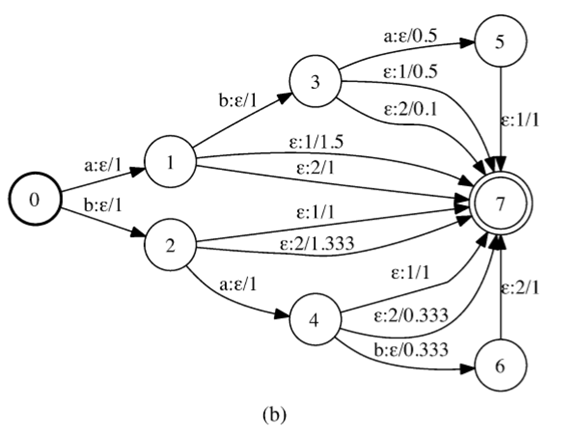
我们有效地将输入自动机转换为转换器,转换器的每个弧的输出标签上携带一个簇标识符。换句话说,转换器的每个二元组(输入标签,输出标签)都指定一个弧簇。请注意,聚类操作不会引入额外的路径,即它只是将每个弧分配给弧簇。图2示出了预处理算法对图1的自动机的应用。
预处理后:
- 构建时间因子转换器


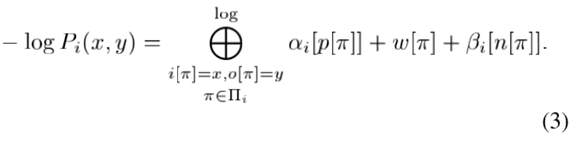

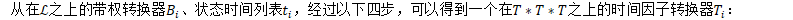
- 因子生成。通常以以下方式对所有因子进行索引:
- 将每个弧的权重进行映射:


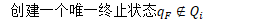



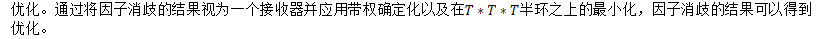

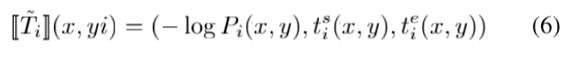
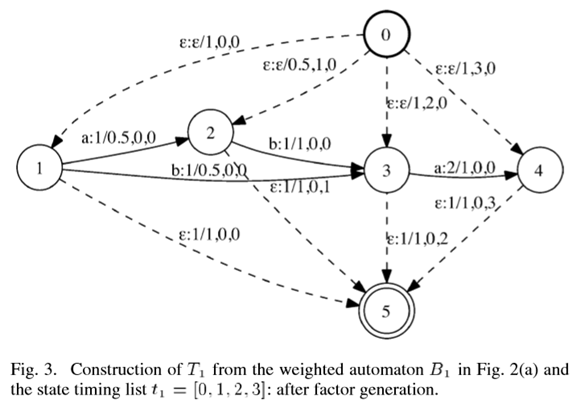



- 因子选择
除了通过对每一个因子进行分析,我们可以利用WFST形式的因子选择滤波来限制、转化或减少索引数。[2]介绍了应用于算法各个阶段的各种滤波器。每个滤波器都由算法过程中获得的一些自动机组成,以实现特定的滤波操作。一种这样的过滤器是将单词映射到音素序列的发音词典。 这个过滤器应用于词级lattice来获得音素级lattice。在我们的例子中,应用这样的过滤器可以保证相应的状态更新。另一个例子是限制因子数的简单语法。在因子生成步骤之后应用该过滤器,并删除语法不接受的因子。我们利用这种语法来拒绝静音符号,即,包括静音符号的因子未被索引。
- 在TFT(时间因子转换器)中进行搜索
用户查询通常是一个未加权的字符串,但它也可以是一个随机的自动加权自动机X,或者是可编译为自动机的布尔查询或者正则表达式的字符串。通过以下步骤得到对查询X的响应R的另一个自动机:


- 在输入端[22]对X与Y进行合成,并将得到的转换器投影到其输出标签上;



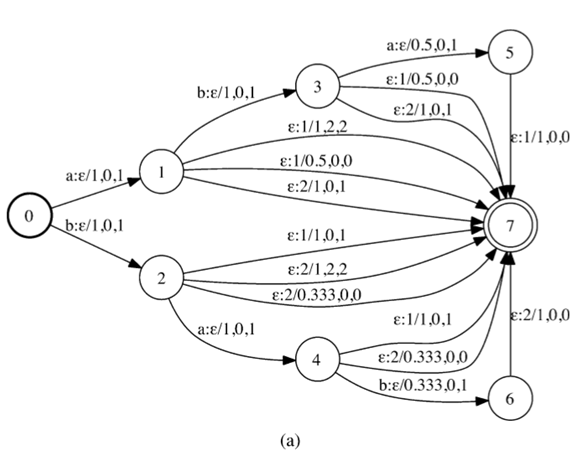
- 将因子转换器与修改的因子转换器进行对比
为了便于比较,图5(b)和(c)给出了从图1中的自动机中获得的FT [2]和MFT [15]。结构性来说,FT与TFFT十分类似。区别在于,FT没有储存任何时间信息。另一方面,MFT与FT或TFT相比,差异较大。TFT信息编码与输出标签 即非最终弧上的每个输出标签都表示一个时间间隔。 在第二节中,我们指出了与这两种结构有关的问题。 所提出的方法通过索引定时信息并为非重叠因子保留单独的条目 - 而不是用于FTFT的外部转换,从而缓解了FT的问题。另一方面,通过将定时信息嵌入到权重中来解决MFT的问题。除去群集中的消息之后,最终的TFT可以是 除了最后的过渡之外,它是完全确定的。 另外请注意,我们不再有量化问题,这是量化标签时间的产品。