1.整体分析
1.1.首先看一下源代码,可以直接Copy。


public class HtmlUtil { /** * 获取 html 中的纯文本 */ public static String Html2Text(String inputString) { String htmlStr = inputString; // 含html标签的字符串 String textStr = ""; Pattern p_script; Matcher m_script; Pattern p_style; Matcher m_style; Pattern p_html; Matcher m_html; Pattern p_html1; Matcher m_html1; try { String regEx_script = "<[//s]*?script[^>]*?>[//s//S]*?<[//s]*?///[//s]*?script[//s]*?>"; // 定义script的正则表达式{或<script[^>]*?>[//s//S]*?<///script> String regEx_style = "<[//s]*?style[^>]*?>[//s//S]*?<[//s]*?///[//s]*?style[//s]*?>"; // 定义style的正则表达式{或<style[^>]*?>[//s//S]*?<///style> String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式 String regEx_html1 = "<[^>]+"; p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE); m_script = p_script.matcher(htmlStr); htmlStr = m_script.replaceAll(""); // 过滤script标签 p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE); m_style = p_style.matcher(htmlStr); htmlStr = m_style.replaceAll(""); // 过滤style标签 p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE); m_html = p_html.matcher(htmlStr); htmlStr = m_html.replaceAll(""); // 过滤html标签 p_html1 = Pattern.compile(regEx_html1, Pattern.CASE_INSENSITIVE); m_html1 = p_html1.matcher(htmlStr); htmlStr = m_html1.replaceAll(""); // 过滤html标签 textStr = htmlStr; } catch (Exception e) { System.err.println("Html2Text: " + e.getMessage()); } return textStr;// 返回文本字符串 } /** * 移除段落标签 */ public static String removeP(String html) { String result = html; if (result.contains("<p>") && result.contains("</p>")) { result = result.replace("<p>", ""); result = result.replace("</p>", "<br>"); while (result.endsWith("<br>")) { result = result.substring(0, result.length() - 4); } } return result; } }
1.2.这里面总共定义了两个静态方法。
- 获取html中的纯文本
- 移除段落标签
除此之外,其他方法,可以看情况添加进去。
2.局部分析
2.1.如何获取html中的纯文本
这里传进去一个html的字符串,然后通过一些过滤操作,返回一个纯文本。
其实有多种方法都可以实现提取html纯文本==>Java实现从Html文本中提取纯文本



2.2.移除段落标签
先将<p>==>""
将</p>==>"<br>"
最后判断末尾是否有<br>标签,如果有则清除。
3.案例
3.1.测试转换html
有如下html代码:
<html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> <style> body {color:red;} h1 {color:#00ff00;} p.ex {color:rgb(0,0,255);} </style> </head> <body> <h1>这是标题 1</h1> <p>这是一个普通的段落。请注意,本文是红色的。页面中定义默认的文本颜色选择器。</p> <p class="ex">这是一个类为"ex"的段落。这个文本是蓝色的。</p> </body> </html>
页面效果:

然后转换过后的数据为:

3.2.测试移除段落标签
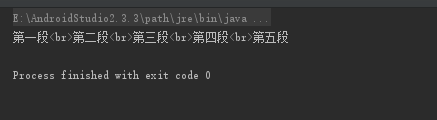
测试几段文字
<p>第一段</p>
<p>第二段</p>
<p>第三段</p>
<p>第四段</p>
<p>第五段</p>
执行结果: