2019-11-25
23:31:59
5.1. MapReduce or Hadoop?
MapReduce是一个编程框架。
其描述由Google于2004年发布[http://
research.google.com/archive/mapreduce.html]。
与其他框架(例如Spring,Struts或
MFC,MapReduce框架为您做一些事情,并为您提供了一个填写
空白。
MapReduce为您做的是将一个群集中的多台计算机组织起来,以便
执行您需要的计算。
它负责在计算机之间分配工作并放置
一起计算每台计算机的结果。
同样重要的是,它可以解决硬件和网络故障,因此它们不会影响您的计算流程。
反过来,你必须打破你的
将问题分解成可以由多台机器并行处理的单独部分,您可以提供
进行实际计算的代码
Hadoop是Google分布式计算的开源实现。
它由两部分组成:
以Google的GFS和Hadoop MapReduce为模型的Hadoop分布式文件系统(HDFS),
它以Google的MapReduce为模型。
Google的系统是专有代码,因此当Google教书时
大学生使用MapReduce编程的想法,他们也使用Hadoop。
为了进一步强调
我们可以注意到,区别在于Yahoo的Hadoop工程师喜欢挑战Google的工程师,
Hadoop和MapReduce之间的排序竞赛。
5.2. Why Hadoop?
我们已经提到Google,Yahoo和Facebook使用了MapReduce框架。
它有
看到金融,零售,电信和政府部门的快速吸收。
它正在侵入生命科学领域。
为什么是这样?

简短的答案是,它简化了大数据的处理。
这个答案立即引起共鸣
人,这是清楚而简洁的,但还不完整。
Hadoop框架具有内置的功能和灵活性,可以执行您以前无法完成的工作。
实际上,Cloudera在最新的O'Reilly Strata上进行了演示
会议提到MapReduce最初是在Google和Facebook上使用的,而不是主要用于
可扩展性,但它允许您处理数据。
2010年,Cloudera客户集群的平均规模为30台计算机。
在2011年是70岁。
人们开始使用Hadoop,出于很多原因,他们都使用新的处理方式
与数据。
Hadoop解决方案可大规模扩展的知识为他们提供了继续前进的安全性,这一点已在全球最大的计算机中心和全球范围内运行的Hadoop证明了这一点。
最大的公司。
As you will discover, the Hadoop framework organizes the data and the computations, and then runs your code. At times, it makes sense to run your solution, expressed in a MapReduce paradigm, even on a single machine(本地模式)
但是,当然,当您没有一个,而是数十个,数百个或数千个
电脑。
如果您的数据或计算足够重要(这些日子不是吗?),那么您
需要一台以上的机器来处理数字。
如果您尝试自己组织工作,那么您
很快就会发现您必须协调许多计算机的工作,处理故障,重试,以及
一起收集结果,依此类推。
输入Hadoop为您解决所有这些问题。
现在你
用锤子,一切都变成钉子:人们通常会在MapReduce中重新制定他们的问题
术语,而不是创建新的自定义计算平台。
No less important than Hadoop itself are its many friends. The Hadoop Distributed File System (HDFS) provides unlimited file space available from any Hadoop node. HBase is a high-performance unlimited-size database working on top of Hadoop. If you need the power of familiar SQL over your large data sets, Pig provides you with an answer. While Hadoop can be used by programmers and taught to students as an introduction to Big Data, its companion projects (including ZooKeeper, about which we will hear later on) will make projects possible and simplify them by providing tried-and-proven frameworks for every aspect of dealing with large data sets.
在学习概念并使用本书中介绍的技术完善技能时,您将发现在许多情况下,Hadoop存储,Hadoop计算或Hadoop的朋友可以帮你。
让我们看看其中一些情况。
1.
您是否发现自己经常清洁公司中有限的硬盘驱动器?
你需要转移吗
数据从一个驱动器传输到另一个驱动器,作为备份?
许多人已经习惯了这种必要性,他们认为
它是生活中令人不愉快但不可避免的一部分。
Hadoop分布式文件系统HDFS通过添加
服务器。
对您来说,它看起来像一个硬盘。
它是自我复制的(您可以设置复制因子),因此
提供冗余作为RAID的软件替代。


•但是请说您很幸运,您无需维护旧版软件,而要负责构建新的,
适用于贵公司工作流程的渐进软件。
当然,您想拥有无限的存储空间,
一劳永逸地解决这个问题,以便专注于真正重要的事情。
答案是:
您可以将HDFS挂载为FUSE文件系统,并且拥有无限的存储空间。
在我们的案例研究中
我们将HDFS成功地用作大型强子对撞机的网格存储。
想象一下,您有多个使用在线资源,计算或数据的客户端。
每次使用
保存在日志中,您需要按天或按天生成每个客户端的资源使用摘要
小时。
由此您将开具发票,因此这很重要。
但是数据集很大。
您可以为此编写一个快速的MapReduce作业。
更好的是,您可以使用Hive,它是基于
Hadoop的顶部及其ETL功能可立即生成发票。
我们将谈论Hive
一旦开始思考并没有通常的限制,您就可以改善已经做过的事情提出新的有用项目。实际上,这本书的一部分是通过询问人们如何使用Hadoop在他们的工作中。欢迎您(读者)提交您的申请,该申请已成为可能Hadoop,我当然会将其放入案例研究中(带有署名:)。
5.3. Meet the Hadoop Zoo

HDFS或Hadoop分布式文件系统为程序员提供了无限的存储空间(实现了程序员梦dream以求的梦想)。
但是,这是HDFS的其他优点。
•水平可伸缩性。
成千上万的服务器保存PB的数据。
当您需要更多存储空间时,无需切换到更昂贵的解决方案,而是添加服务器。
•商品硬件。
HDFS在设计时考虑了相对便宜的商品硬件。
HDFS
是自我修复和复制。
•容错能力。
Hadoop动物园的每个成员都知道如何处理硬件故障。
如果你
拥有一万台服务器,那么平均每天您将看到一台服务器发生故障。
HDFS可以预见
默认情况下,在不同的数据节点服务器上将数据复制3次。
因此,如果一个数据节点
如果失败,则可以使用其他两个在另一个位置还原第三个。
HDFS的实现以GFS(Google分布式文件系统)为模型,因此您可以阅读第一个关于此的论文,可以在这里找到:http://labs.google.com/papers/gfs.html
Hadoop, the little elephant
Hadoop organizes your computations using its MapReduce part. It reads the data, usually from its storage, the Hadoop Distributed File System (HDFS), in an optimal way. However, it can read the data from other places too, including mounted local file systems, the web, and databases. It divides the computations between different computers (servers, or nodes). It is also fault-tolerant.
如果您的某些节点发生故障,则Hadoop知道如何通过重新分配该节点来继续进行计算。
对另一个节点的工作不完整,并在无法完成其任务的节点之后进行清理。
它也是
知道如何在一个地方组合计算结果
HBase, the database for Big Data
“三十根辐条共享车轮的轮毂,正是它的空旷空间”-陶德庆(翻译
由冯嘉富和简(英语)撰写[http://terebess.hu/english/tao/gia.html]
HBase虽然不是动物,但功能非常强大。
当前由字母H表示
基本谱号。
如果您认为这不是很好,那您是对的,HBase的人们正在考虑改变
徽标。
HBase是用于大数据的数据库,最多可包含数百万列和数十亿行。
HBase的另一个功能是它是键值数据库,而不是关系数据库。
我们将进入
稍后,这两种数据库方法的优缺点,但是现在让我们仅注意键值数据库
被认为更适合大数据。
为什么?
因为它们不存储空值!
这给了他们
“稀疏”的称谓,正如我们在上面看到的,陶德钦说,出于这个原因,它们很有用。
ZooKeeper
每个动物园都有一个动物园管理员,Hadoop动物园也不例外。
当所有Hadoop动物都想
一起做某事,是ZooKeeper帮助他们完成任务。
他们都认识他,听从并服从
他的命令。
因此,ZooKeeper是用于维护配置信息的集中式服务,
命名,提供分布式同步和提供组服务。
ZooKeeper也是容错的。
在您的开发环境中,您可以将Zookeeper放在一个
节点,但是在生产环境中,您通常在奇数个服务器上运行它,例如3或5。
Hive - data warehousing
Hive: "I am Hive, I let you in and out of the HDFS cages, and you can talk SQL to me!" Hive is a way for you to get all the honey, and to leave all the work to the bees. You can do a lot of data analysis with Hadoop, but you will also have to write MapReduce tasks. Hive takes that task upon itself. Hive defines a simple SQL-like query language, called QL, that enables users familiar with SQL to query the data. At the same time, if your Hive program does almost what you need, but not quite, you can call on your MapReduce skill. Hive allows you to write custom mappers and reducers to extend the QL capabilities.
Pig - Big Data manipulation Pig:
"I am Pig, I let you move HDFS cages around, and I speak Pig Latin." Pig is called pig not because it eats a lot, although you can imagine a pig pushing around and consuming big volumes of information. Rather, it is called pig because it speaks Pig Latin. Others who also speak this language are the kids (the programmers) who visit the Hadoop zoo. So what is Pig Latin that Apache Pig speaks? As a rough analogy, if Hive is the SQL of Big Data, then Pig Latin is the language of the stored procedures of Big Data. It allows you to manipulate large volumes of information, analyze them, and create new derivative data sets. Internally it creates a sequence of MapReduce jobs, and thus you, the programmer-kid, can use this simple language to solve pretty sophisticated large-scale problems
5.4. Hadoop alternatives
Large data storage alternatives
Large database alternatives
离HBase最近的是卡桑德拉。虽然HBase是谷歌大表的近克隆,卡桑德拉声称
成为"大桌子/发电机混合"。可以说,虽然卡桑德拉的"写-永不失败"强调。
HBase 是大多数用例中更强大的数据库。HBase 更多
卡桑德拉在使用中普遍存在,面临一场艰苦的战斗,但可能正是你需要的。
Hypertable 是另一个接近谷歌大表的功能数据库,它声称运行速度是谷歌的10倍。
比HBase。HBase 和超可桌面支持者和作者之间正在展开讨论。
不想在它采取一边,留下比较的读者。和卡桑德拉一样,超桌面的用的更少了。
用户比HBase,在这里,读者需要评估超表的速度,他的应用程序,以及
并权衡其他因素。
MongoDB(来自"humongous")是一个可扩展的、高性能的、开源的、面向文档的数据库。MongoDB 以C++编写,具有面向文档的存储、任何属性的完整索引、复制和高可用性、丰富的基于文档的查询,并且它适用于 MapReduce。如果您专门处理文档而不是任意数据,则值得一看。
其他可能考虑的开源和商业数据库包括具有 SQL 支持和可视化的 Vertica、OLTP 的 Cloudran 和 Spire。
最后,在开始开发项目之前,您需要比较备选方案。下面是此类比较的示例。请记住,这只是一个可能的观点,您的项目和您的观点的细节将有所不同。因此,下表主要是为了鼓励读者针对自己的需要做类似的评价。
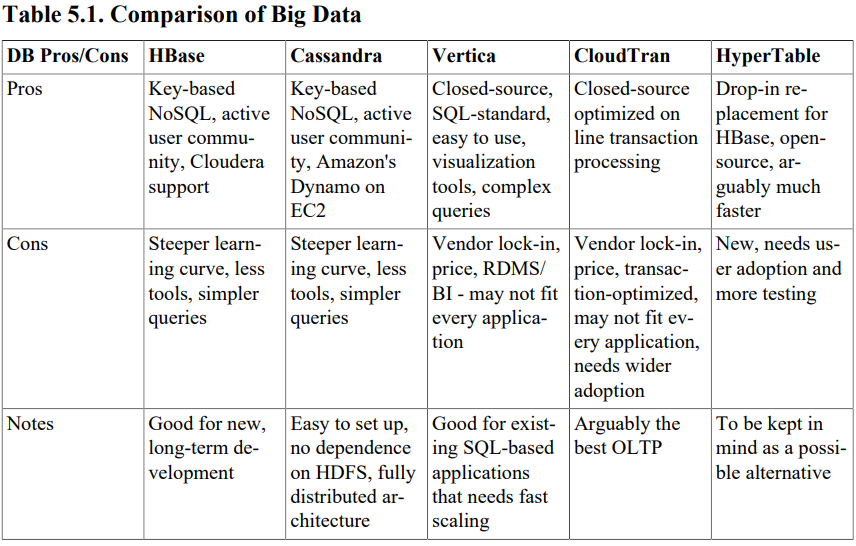
5.5. Alternatives for distributed massive computations
5.6. Arguments for Hadoop
We have given the pro arguments for the Hadoop alternatives, but now we can put in a word for the little elephant and its zoo. It boasts wide adoption, has an active community, and has been in production use in many large companies. I think that before embarking on an exciting journey of building large distributed systems, the reader will do well to view the presentation by Jeff Dean, a Google Fellow, on the "Design, Lessons, and Advice from Building Large Distributed Systems" found on SlideShare [http:// www.slideshare.net/xlight/google-designs-lessons-and-advice-from-building-large-distributed-systems] Google has built multiple applications on GFS, MapReduce, and Big Table, which are all implemented as open-source projects in the Hadoop zoo. According to Jeff, the plan is to continue with 1,000,000 to 10,000,000 machines spread at 100s to 1000s of locations around the world, and as arguments go, that is pretty big.