1.C语言实现WordCount
编写Mapper程序
//mapper #include <stdio.h> #include <string.h> #include <stdlib.h> #define BUF_SIZE 2048 #define DELIM " " #define SEPARATOR " " int main(int argc, char *argv[]){ char buffer[BUF_SIZE]; while(fgets(buffer, BUF_SIZE - 1, stdin)){ int len = strlen(buffer); if(buffer[len-1] == ' ') { buffer[len-1] = 0; } char *query = NULL; query = strtok(buffer,SEPARATOR); while(query){ printf("%s 1 ", query); query = strtok(NULL, " "); } } return 0; }
执行编译
gcc mapper.c -o wordcountmapper
编写reducer程序
#include <stdio.h> #include <string.h> #include <stdlib.h> #define BUFFER_SIZE 1024 #define DELIM " " int main(int argc, char *argv[]){ char strLastKey[BUFFER_SIZE]; char strLine[BUFFER_SIZE]; int count = 0; *strLastKey = '�'; *strLine = '�'; while( fgets(strLine, BUFFER_SIZE - 1, stdin) ){ char *strCurrKey = NULL; char *strCurrNum = NULL; strCurrKey = strtok(strLine, DELIM); strCurrNum = strtok(NULL, DELIM); /* necessary to check error but.... */ if( strLastKey[0] == '�'){ strcpy(strLastKey, strCurrKey); } if(strcmp(strCurrKey, strLastKey)) { printf("%s,%d ", strLastKey, count); count = atoi(strCurrNum); } else { count += atoi(strCurrNum); } strcpy(strLastKey, strCurrKey); } printf("%s,%d ", strLastKey, count); /* flush the count */ return 0; }
执行编译
gcc reduce.c -o wordcountreducer
本地测试:
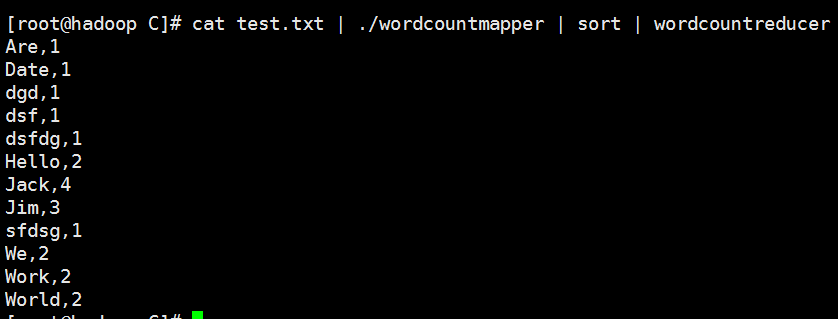
执行结果:
编写shell脚本执行
#!/bin/bash #Usage: #------------------------------------------------------ #Filename: start-stream-mr-job.sh #Revision: 1.0 #Date: 2018/08/14 #Author: Jim #Description: #Notes: #------------------------------------------------------ Usage="Usage: $0 [job_date_id]" #[ $# -lt 2 ] && echo "${Usage}" && exit -1 #define alias time and bring into effect alias dt='date +%Y-%m-%d" "%H:%M:%S' shopt -s expand_aliases export LANG=en_US.UTF-8 #判断日期是否有参数,如没有参数默认取当天,参数优先 if [ ! -n "$1" ];then job_date_id=`date -d "0 days ago" +%Y%m%d` else job_date_id=$1 fi #参数日期的前一天 before_job_date_id=`date -d "${job_date_id} 1 days ago" +%Y%m%d` #当前脚本路径 cd `dirname $0` scriptDir=`pwd` echo "`dt`:当前脚本路径:${scriptDir},参数日期:${job_date_id},前一天日期:${before_job_date_id}" hdfs dfs -rm -r /MIDDLE/input/* hdfs dfs -put test.txt /MIDDLE/input/ hdfs dfs -rm -r /MIDDLE/output hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.6.jar -D stream.recordreader.compression=gzip -D stream.non.zero.exit.is.failure=false -D mapreduce.job.priority=HIGH -D mapreduce.reduce.shuffle.parallelcopies=20 -D mapred.reduce.copy.backoff=60s -D mapreduce.task.io.sort.factor=64 -D mapreduce.task.io.sort.mb=256 -D mapreduce.map.memory.mb=2048 -D mapreduce.reduce.memory.mb=3072 -D mapreduce.map.java.opts=-Xmx1740m -D mapreduce.reduce.java.opts=-Xmx1740m -D mapreduce.job.reduces=1 -D mapreduce.output.fileoutputformat.compress=true -D mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec -jobconf mapred.job.queue.name=Q_app_social -input /MIDDLE/input/* -output /MIDDLE/output/ -file ./wordcountmapper -mapper "wordcountmapper" -file ./wordcountreducer -reducer "wordcountreducer"
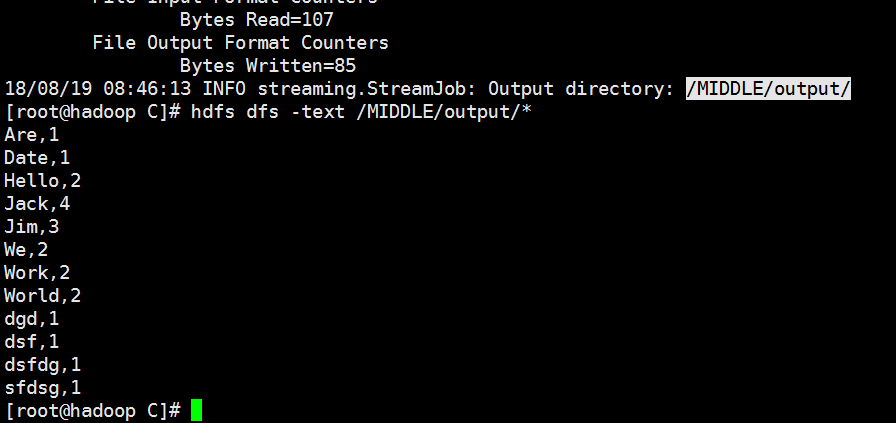
执行结果:
2.Python实现WordCount
3.Java实现WordCount
/** * */ package com.mr.demo; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.io.compress.GzipCodec; /** * @className WordCountMapReduce * @author Admin * @description: TODO * @date 2019年3月30日 上午11:04:31 */ public class WordCountMapReduce { /** * @param args * @throws IOException * @throws InterruptedException * @throws ClassNotFoundException */ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // TODO Auto-generated method stub //创建配置对象 Configuration conf = new Configuration(); //创建Job对象 Job job = Job.getInstance(conf, "wordcount"); job.setJarByClass(WordCountMapReduce.class); //设置mapper类 job.setMapperClass(WordCountMapper.class); //设置reduce类 job.setReducerClass(WordCountReduce.class); // 设置 map 输出的 key value job.setMapOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置reduce输出的 key value job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //设置压缩格式 FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); //提交job boolean b = job.waitForCompletion(true); if(!b){ System.out.println("wordcount task fail!"); } } //Map public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //输入得到每一行数据 String line = value.toString(); //分割每一行数据 String[] words = line.split(" "); //循环遍历输出 for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } } //Reduce public static class WordCountReduce extends Reducer<Text, IntWritable , Text, IntWritable> { protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { Integer count = 0; for (IntWritable value : values) { count += value.get(); } context.write(key, new IntWritable(count)); } } }
执行jar包:
#!/bin/bash #Usage: #------------------------------------------------------ #Filename: start-comm-job_pro.sh #Revision: 1.0 #Date: 2017/10/30 #Author: #Description: #Notes: #------------------------------------------------------ Usage="Usage: $0 [job_date_id]" #[ $# -lt 1 ] && echo "${Usage}" && exit -1 alias dt='date +%Y-%m-%d" "%H:%M:%S' shopt -s expand_aliases #切换到当前脚本路径 cd `dirname $0` #当前路径的目录 scriptDir=`pwd` #判断日期是否有参数,如没有参数默认取当天,参数优先 if [ ! -n "$1" ];then job_date_id=`date -d "0 days ago" +%Y%m%d` else job_date_id=$1 fi #参数日期前一天 before_1_job_date_id=`date -d "${job_date_id} 1 days ago" +%Y%m%d` echo "`dt`:当前参数路径:${scriptDir},参数日期:${job_date_id},前一天:${before_1_job_date_id}" hadoop jar WordCount-V1.0.1.jar com.mr.demo.WordCountMapReduce /input/* /output/