如果RabbitMQ集群中只有一个Broker节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有的消息都设置为持久化,并且对应的队列也可以将durable属性设置为true,但是这样仍然无法避免由于缓存的问题:因为在消息发送后和被写入磁盘并执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过publisher confirm机制能够确保客户端知道哪些消息已经存入磁盘,尽管如此,一般不希望遇到单点故障导致服务不可用。
如果RabbitMQ集群是由多个Broker节点组成的,那么从服务的整体性可用性上来讲,该集群对于单点故障是由弹性的,但是也要注意:尽管交换器和绑定关系能够在单点故障问题上幸免于难,但是队列和其上的存储的消息却不行,这是因为队列进程及其内容仅仅维持在单个节点上,所以一个节点的失效表现为其对应的队列不可用。
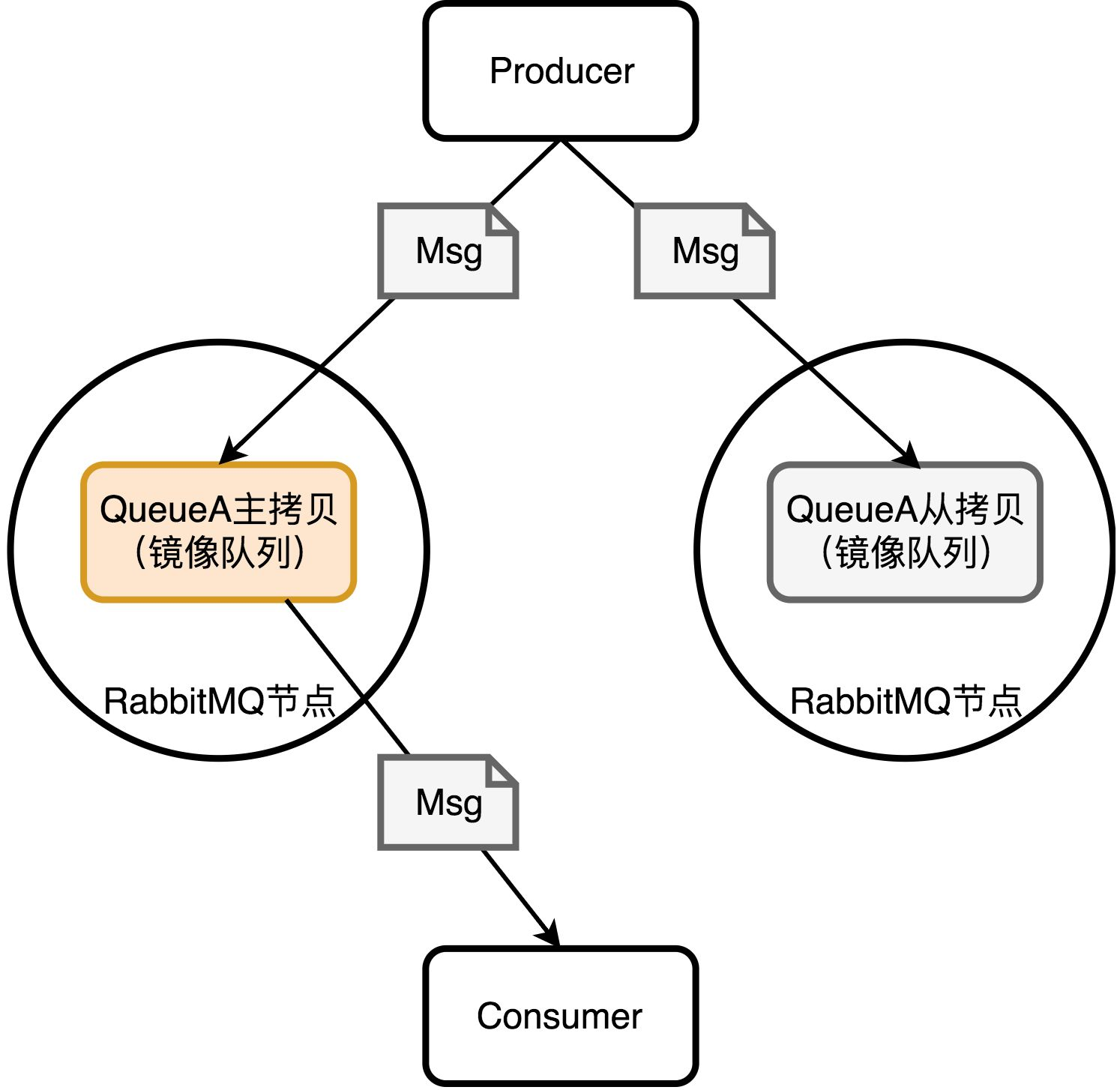
引入镜像队列机制,可以将队列镜像到集群中的其他Broker节点之上,如果集群中的一个节点失效了,队列能够自动的切换到镜像中的另一个节点上以保证服务的可用性。在通常的用法中,针对每一个配置镜像的队列都包含一个主节点(master)和若干个从节点(slave)。
slave会准确的按照master的执行命令的顺序进行动作,故slave与master上维护的状态应该是相同的。如果master由于某种原因失效,那么“资历最老”的slave会被提升为新的master。根据slave加入的时间排序,时间最长的slave即为“资历最老”。发送到镜像队列的所有消息会被同时发往master和所有的slave上,如果此时master挂掉了,消息还会在slave上,这样slave提升为master的时候消息也不会丢失。除发送消息(Basic.publish)外的所有动作都只会向master发送,然后再由master将命令执行的结果广播给各个slave。
如果消费者与slave建立连接并进行订阅消费,其实质上都是从master上获取消息,只不过看似是从slave上消费而已。比如消费者与slave建立了TCP连接之后执行一个Basic.Get操作,那么首先是由slave将Basic.Get请求发往master,再由master准备好数据返回给slave,最后由slave投递给消费者。这里可能有疑问?大多数的读写压力都落到了master上,那么这样是否负载做不到有效的均衡?或者说是否可以像MySQL一样能够实现master写而slave读呢?注意这里的master和slave是针对队列而言的,而队列可以均匀的散落在集群的各个Broker节点以达到负载均衡的目的,因为真正的负载还是针对实际的物理机器而言的,而不是内存中驻留的队列进程。
注意要点:
RabbitMQ的镜像队列同时支持publisher confirm和事务两种机制。在事务机制中,只有当前事务在全部的镜像中执行之后,客户端才会收到Tx.Commit-Ok的消息。同样的,在publisher confirm机制中,生产者进行当前消息确认的前提是该消息被全部进行所接收了。
不同于普通的非镜像队列,镜像队列的backing_queue比较特殊,其实现并非是rabbit_variable_queue,它内部包裹了普通backing_queue进行本地消息的持久化处理,在此基础上增加了将消息和ack复制到所有镜像的功能。镜像队列的结构可以参考下图:

可以看出:master的backing_queue采用的是rabbit_mirror_queue_master,而slave的backing_queue实现是rabbit_mirror_queue_slave。
所有对rabbit_mirror_queue_master的操作都会通过组播GM(Guaranteed Multicast)的方式同步到各个slave中。GM负责消息的广播,rabbit_mirror_queue_slave负责回调处理,而master上的回调处理是由coordinator负责完成的,master对消息进行处理的同时将消息的处理通过GM广播给所有的slave,slave的GM收到消息后,通过回调交由rabbit_mirror_queue_slave进行实际的处理。
GM模块实现的是一种可靠的组播通信协议,该协议能够保证组播消息的原子性,即保证组中活着的节点要么收到消息要么都收不到,它的实现大致为:将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上;当有节点失效时,相邻的节点会接管以保证本次广播的消息复制到所有节点。在master和slave上的这些GM形成一个组,这个组的信息会记录在Mnesia中,不同的镜像形成不同的组。操作命令从master对应的GM发出后,顺着链表传送到所有的节点。由于所有的节点组成了一个循环链表,master对应的GM最终会收到自己发出的操作命令,这个时候master就知道该操作命令都同步到了所有的slave上。

注意:每当一个节点加入或者重新加入到这个镜像链路中时,之前队列保存的内容会被全部清空。
当slave挂掉以后,除了与slave相连的客户端全部断开,没有其他影响。当master挂掉之后,会有以下连锁反应:
(1)与master连接的客户端连接全部断开;
(2)选举最老的slave作为新的master,因为最老的slave与旧的master之间的同步状态应该是最好的。如果此时所有的slave处于未同步状态,则未同步的消息会丢失;
(3)新的master重新入队所有unack消息,因为新的slave无法区分这些unack的消息是否已经到达客户端,或者是ack信息丢失在老的master链路上,再或者是丢失在老的master组播ack消息到所有slave的链路上,所以出于消息可靠性的考虑,重新入队所有的unack消息,不过此时客户端可能会有重复消息;
(4)如果客户端连着slave,并且Basic.Consume消费时指定了x-cancel-on-ha-failover参数,那么断开之时客户端会收到一个Consumer Cancellation Notification的通知,消费者客户端中会调用Consumer接口的handleCancel方法。如果未指定x-cancel-on-ha-failover参数,那么消费者将无法感知master宕机;
x-cancel-on-ha-failover参数的使用示例如下:
Channel channel = ...; Consumer consumer = ...; Map<String,Object> args = new HashMap<String,Object>(); args.put("x-cancel-on-ha-failover",true); channel.basicConsume("my-queue",false,args,consumer);
镜像队列的配置主要是通过Policy来完成的,主要详细介绍rabbitmqctl set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition} 命令中的definition部分,对应镜像队列的配置来说,definition中包含3个部分:ha-mode、ha-params和ha-sync-mode。
❤ ha-mode:指明镜像队列的模式,有效值为all、exactly、nodes。默认为all。all表示在集群中所有的节点上进行镜像;exactly表示在指定个数的节点上进行镜像,节点个数由ha-params指定;nodes表示在指定节点上进行镜像,节点名称通过ha-params指定,节点的名称通常类似于rabbit@hostname,可以通过rabbitmqctl cluster_status命令查看到。
❤ ha-params:不同的ha-modee配置中需要用到的参数;
❤ ha-sync-mode:队列中消息的同步方式,有效值为automatic何manual;
ha-mode参数对排他队列并不生效,因为排他队列是连接独占的,当连接断开时队列会自动删除,所以实际上这个参数对排他队列没有任何意义。
将新节点加入到已存在的镜像队列中时,默认情况下ha-sync-mode取值为manual,镜像队列中的消息不会主动同步到新的slave中,除非显示的调用同步命令。当调用同步命令后,队列开始阻塞,无法对其进行其他操作,直到同步完成。当ha-sync-mode设置为automatic时,新加入的slave会默认同步已知的镜像队列。由于同步过程的限制,所以不建议对生成环境中正在使用的队列进行操作。使用rabbitmqctl list_queues {name} slave_pids synchronised_slave_pids命令可以查看哪些slaves已经同步完成。通过手动方式同步一个队列的命令为rabbitmqctl sync_queue {name} ,同样取消某个队列的同步操作:rabbitmqctl cancel_sync_queue {name}。
当所有slave都出现未同步状态,并且ha-promote-on-shutdown设置为when-synced(默认)时,如果master因为主动原因停掉,比如通过rabbitmqctl stop命令或者优雅关闭操作系统,那么slave不会接管master,也就是此时镜像队列不可用;但是如果master因为被动原因停掉,比如Erlang虚拟机或者操作系统崩溃,那么slave会接管master。这个配置项隐含的价值取向是保证消息可靠不丢失,同时放弃了可用性。如果ha-promote-on-shutdown设置为always,那么不论master以何种原因停止,slave都会接管master,优先保证可用性,不过消息可能会丢失。
镜像队列中最后一个停止的节点会是master,启动顺序必须是master先启动。如果slave先启动,它会有30秒的等待时间,等待master的启动,然后加入的=到集群中。如果30秒内master没有启动,slave会自动停止。当所有节点因故(断电)同时离线时,每个节点都认为自己不是最后停止的节点,要恢复镜像队列,可以尝试在30秒内启动所有节点。
参考:《RabbitMQ实战指南》 朱忠华 编著;