Latch是什么
Latch是SQL Server引擎保证内存中的结构的一致性的轻量同步机制。比如索引,数据页和内部结构(比如非叶级索引页)。SQL Server使用Buffer Latch保护缓冲池中的页,用I/O Latch保护还未加载到缓冲池的页,用Non-Buffer Latch保护内存中的内部结构。
- Buffer Latch:当工作线程访问缓冲池中的某个页之前,必须要先获得此页的Latch。主要用于保护用户对象和系统对象的页。等待类型表现为PAGELATCH_*
- I/O Latch:当工作线程请求访问的页未在缓冲池中时,就会发一个异步I/O从存储系统将对应的页加载到缓冲池中。这个过程会获取相应页上 I/O Latch,避免其它线程使用不兼容的Latch加载同一页到缓冲池中。等待类型表现为PAGEIOLATCH_*
- Non-Buffer Latch:保护缓冲池页之外的内部内存结构时使用。等待类型表现为LATCH_XX。
Latch只在相应页或者内部结构被操作期间持有,而不像锁那样在整个事务中持有。比如,使用WITH NOLOCK查询某表。查询过程中不会在表的任何层级上获取共享锁,但是在数据页可以读取前,需要获取这些的页的Latch。
Latch的模式
Latch跟锁一样,是SQL Server引擎并发控制的一部分。在高并发环境下的Latch争用的情况无可避免。SQL Server使用模式兼容性强制互不兼容的两个Latch请求线程中的一个等待另一个完成操作并释放目标资源上的Latch后,才能访问此目标资源。
Latch有5种模式:
- KP – Keep Latch 保证引用的结构不能被破坏
- SH – Shared Latch, 读数据页的时候需要
- UP – Update Latch 更改数据页的时候需要
- EX – Exclusive Latch 独占模式,主要用于写数据页的时候需要
- DT – Destroy Latch 在破坏引用的数据结构时所需要
Latch模式兼容性,Y表示兼容,N表示不兼容:
| KP | SH | UP | EX | DT |
| Y | Y | Y | Y | N |
| Y | Y | Y | N | N |
| Y | Y | N | N | N |
| Y | N | N | N | N |
| N | N | N | N | N |
- 影响Latch争用的因素
|
因素
|
明说 |
|
使用过多的逻辑CPU
|
任何多核的系统都会出现Latch争用。Latch争用超过可接受程度的系统,多数使用16个或者以上的核心数。 |
|
架构设计和访问模式
|
B树深度,索引的大小、页密度和设计,数据操作的访问模式都可能会导致过多的Latch争用
|
|
应用层的并发度过高
|
多数Latch争用都会伴有应用层的高并发请求。
|
|
数据库逻辑文件的布局
|
逻辑文件布局影响着分配单元结构(如PFS,GAM,SGAM,IAM等)的布局,从而影响Latch争用程度。最著名的例子就是:频繁创建和删除时临表,导致tempdb的PFS页争用
|
|
I/O子系统性能
|
大量的PAGEIOLATCH等待就说明SQL Server在等待I/O子系统。
|
诊断Latch争用
诊断的主要方法和工具包括:
- 观察性能监视器的CPU利用率和SQL Server等待时间,判断两者是否具有关联性。
- 通过DMV获取引起Latch争用的具体类型和资源。
- 诊断某些Non-Buffer Latch争用,可能还需要获取SQL Server进程的内存转储文件并结合Window调试工具一起分析。
Latch争用是一种正常的活动,只有当为获取目标资源的Latch而产生的争用和等待时间影响了系统吞吐量时,才认为是有害的。为了确定一个合理的争用程度,需要结合性能、系统吞吐理、IO和CPU资源一起分析。
通过等待时间衡量Latch争用对应用性能的影响程度
1.页平均Latch等待时间增长与系统吞吐理增长一致。
如果页平均Latch等待时间增长与系统吞吐理增长一致,特别是Buffer Latch等待时间增长的超过了存储系统的响应时间,就应该使用sys.dm_os_waiting_tasks检查当前的等待任务。还需要结合系统活动和负载特征观察。诊断的一般过程:
- 使用“Query sys.dm_os_waiting_tasks Ordered by Session ID”脚本或者“Calculate Waits Over a Time Period”脚本观察当前的等待任务和平均Latch等待时间情况。
- 使用“QueryBufferDescriptorsToDetermineObjectsCausingLatch”脚本确定争用发生的位置(索引和表)。
- 使用性能计数器观察MSSQL%InstanceName%Wait StatisticsPage Latch WaitsAverage Wait Time或者查询sys.dm_os_wait_stats观察页平均Latch等待时间。
2.业务高峰期Latch等待时间占总等待时间百分比。
如果Latch等待时间比率随着应用负载增长而直线增长,可能Latch争用会影响性能,需要优化。通过等待统计性能计数观察Page和Non-Page Latch等待情况。然后将之与CPURAMIONetwork吞吐量等相关的计数器比较。例如使用Transactions/sect和Batch Requests/sec衡量资源利用情况。
sys.dm_os_wait_stats没有包含所有等待类型的等待时间,这是因为它记录是的自上次实例启动(或清空)以后的等待数据。也可以通过dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')手动清空它。在业务高峰前取一次sys.dm_os_wait_stats数据,在业务高峰时取一次,然后计算差异。
3. 系统吞吐理没有增长(甚至下降),同时应用负载加重,SQL Server可用的CPU增加。
在高并发和多CPU系统中,对类似自增聚集索引的并发插入,会导致一种像现:CPU数量增加,而系统吞吐量下降,同时Latch页等待会增加。
4. 应用负载增长时CPU利用率却没有增长。
当CPU利用率没有随着应用并发负载增长而增长,说明SQL Server在等待某种资源(Latch争用的表现)。
查询当前的Latch
下面的查询可以查看当前实时的等待信息。wait_type为PAGELATCH_* 和PAGEIOLATCH_*的即为Buffer Latch的等待。
SELECT wt.session_id, wt.wait_type , er.last_wait_type AS last_wait_type , wt.wait_duration_ms , wt.blocking_session_id, wt.blocking_exec_context_id, resource_description FROM sys.dm_os_waiting_tasks wt JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id WHERE es.is_user_process = 1 AND wt.wait_type <> 'SLEEP_TASK' ORDER BY wt.wait_duration_ms desc
查询返回列的说明:
|
列
|
说明
|
|
Session_id
|
task所属的session id
|
|
Wait_type
|
当前的等待类型 |
|
Last_wait_type
|
上次发生等待时的等待类型 |
|
Wait_duration_ms
|
此等待类型的等待时间总和(毫秒) |
| Blocking_session_id |
当前被阻塞的session id
|
|
Blocking_exec_context_id
|
当前task的ID |
|
Resource_description
|
具体等待的资源 |
下面的查询返回Non-Buffer Latch的信息
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc
返回列的说明:
| 列 |
说明
|
|
Latch_class
|
Latch类型
|
|
Waiting_requests_count
|
当前Latch类型发生的等待次数
|
|
Wait_time_ms
|
当前Latch类型发生等待的时间总和
|
|
Max_wait_time_ms
|
当前Latch类型发生等待最长时间
|
Latch争用的常见场景
尾页的数据插入争用
在聚集索引表上,如果聚集索引的首列(leading key)是一个有序增长的列(如自增列和Datetime),则可能导致Latch争用。
这种场景中表除了在归档时很少执行删除和更新操作;通常表很大,行较窄。
插入一条数据到索引中的步骤:
1. 检索B树,定位到新行将要被存储的页
2. 在此页上加上排他Latch(PAGELATCH_EX),避免其它操作同时修改此页。然后在所有非叶级页中加上共享Latch(PAGELATCH_SH).
有时也会在非叶页获取排他Latch,如页拆分时直接受到影响的非叶页。
3. 向日志文件写一条记录,表示此行已经被修改
4. 向页中写中新行并标记为脏页
5. 释放所有Latch.
如果表的索引是基于有序增长的键,则新行都会被插入到B树的最后一页,直到这页存满。高并发负载下,就会导致聚集和非聚集索引B树中最右页被争用。通常这种并发争用发生在以插入操作为主且页密度较大的索引上。通过sys.dm_db_index_operational_stats的可以观察到页Lath争用和B树中非叶级页Latch争用的情况。
举个例子:
线程A和线程B同时向尾页(比如1999页)插入新行。逻辑上,两者都可以同时获取尾页中对应行的行级排他锁。但是,为维护内存完整性一次只可以有一个线程获取到页上排他Latch。假设A获取EX Latch,则B就需要等待。则B就会在 sys.dm_os_waiting_tasks表现出等待类型为PAGELATCH_EX的等待。
具有非聚集索引的小表上进行随机插入导致的Latch争用
将表当做临时队列结构使用,通常会出现这种场景。在满足下面的条件时,就可能出现Latch争用(包括EX和SH):
- 高并发的INSERT,DELETE,UPDATE和SELECT操作
- 页密度较大,行较窄
- 表的行数较少,所以B树也较浅,索引深度在2~3级。
较浅的B树上执行大量随机的INSERT极可能导致页拆分。执行页拆分时,需要在B树所有层级上获取SH Latch和在数据发生修改的所有页上获取EX Latch。在非常高并发的INSERT和DELETE情况,还极可能导致B树ROOT页发生拆分。ROOT页拆分会导致Non-Buffer Latch:ACCESS_METHODS_HBOT_VIRTUAL_ROOT。
可以通过下面的脚本观察表的索引深度:


select o.name as [table], i.name as [index], indexProperty(object_id(o.name), i.name, 'indexDepth') + indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level i.[rows] as [rows], i.origFillFactor as [fillFactor], case (indexProperty(object_id(o.name), i.name, 'isClustered')) when 1 then 'clustered' when 0 then 'nonclustered' else 'statistic' end as type from sysIndexes i join sysObjects o on o.id = i.id where o.type = 'u' and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics order by o.name
PFS页的Latch争用
这属于分配瓶颈的一种情况。PFS记录着数据页的空间使用情况。PFS页上使用1个字节(Byte)表示一个页的使用情况。一个PFS页可以表示8088个数据页,所以每8088个数据页就会有一个PFS页。一个数据文件的第二个页就是PFS页(PageID=2)。
当需要分配空间给新对象或者数据操作,SQL Server会在PFS页上获取SH Latch查看目标区区是否有可用的页。如果有,则会在PFS上获取 UP Latch,并更新对应页的空间使用信息。类似的过程也会发生在SAM,GSAM页上。在多CPU的系统上,文件组中只有很少的数据文件,过多的PFS页请求,则可能导致Latch争用。边种场景在Tempdb中会相对较常见些。
当在Tempdb的PFS或者SGAM页上出现较多PATHLATCH_UP等待时,可以采取下面的方法消除Latch争用:
- 增加Tempdb的数据文件个数,个数=CPU的核心数
- 启用跟踪标记TF 1118
Tempdb中的表值函数导致的Latch争用
这个发生的原因跟PFS的Latch争用一样。每次调用多语句的表值函数总要创建和删除表变量,当在一个查询的多次引用多语句的表值函数时就可能会生很多的表变量创建和删除操作,从而导致Latch争用。
解决不同模式下的Latch争用
使用已有的列将数据分布到所有的索引键区间
在银行ATM系统场景中考虑使用ATM_ID将对交易表的INSERT操作分布到所有键值区间。因为一个用户同一时间只能在使用一台ATM。这样就将销售系统的场景中,可以考虑使用Checkout_ID列或者Store_ID列。这种方式需要使用唯一复合索引。这个复合索引的首键通常使用被选定的标识列或者某些列经过Hash的计算列,然后再结合其它列共同组成。使用Hash计算列会较优,因为标识列的唯一值会太多,造成键值区间过多,也会让表数据的物理结构变差。虽然Hash计算列的索引键值区间较少,但对于分散INSERT负载减少Latch争用而言,已经足够了。比如销售系统中,可以使用Store_ID对CPU核数取模做为Hash值。
这种方式会加大索引碎片,降低范围扫描的性能。可能还需要修改应用架构,例如语句的WHERE需要根据新的索引结构进行调整。
示例:在一个32核心的系统中的交易表
原表结构:
create table table1 ( TransactionID bigint not null, UserID int not null, SomeInt int not null ) go alter table table1 add constraint pk_table1 primary key clustered (TransactionID, UserID) go 方式1.:使用UserID做为索引首键,将INSERT操作分布到所有数据页上。需要注意的是:索引修改后,所有SELECT的WHERE等式中需要同时指定UserID和TransactionID。 create table table1 ( TransactionID bigint not null, UserID int not null, SomeInt int not null ) go alter table table1 add constraint pk_table1 primary key clustered (UserID, TransactionID) go 方式2:使用TransactionID对CPU核数取模做为索引首键,将INSERT操作较均匀分布到表上。 create table table1 ( TransactionID bigint not null, UserID int not null, SomeInt int not null ) go -- Consider using bulk loading techniques to speed it up ALTER TABLE table1 ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL alter table table1 add constraint pk_table1 primary key clustered (HashValue, TransactionID, UserID) go
使用GUID列做为索引首键
这个我本人非常不认同,所以也不想分析了,只是为了维护完整性加在这里。并发负载和Latch争用严重到需要GUID这种极端的方式来分散负载时,分表、分区或者使用NoSQL类产品才是更好的方法。
使用计算列对表进行Hash分区
表分区能减少Latch争用。使用计算列对表进行Hash分区,一般的步骤:
- 新建或者使用现有的文件组承载各分区
- 如果使用新文件组,需要考虑IO子系统的优化和文件组中数据文件的合理布局。如果INSERT负载占比较高,则文件组的数据文件个数建议为物理CPU核心数的1/4(或者1/2,或者相等,视情况而定)。
- 使用CREATE PARTITION FUNCTION将表分成N个分区。N值等于上一步的数据文件的个数。
- 使用CREATE PARTITION SCHEME绑定分区函数到文件组,然后再添加一个smallint或者tinyint类型的Hash列,再计算出合适的Hash分布值(例如HashBytes值取模 或者取Binary_Checksum值)。
示例代码:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer -- so for below this is aligned to 16 core system CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15) CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] ) -- Add the computed column to the existing table (this is an OFFLINE operation) -- Consider using bulk loading techniques to speed it up ALTER TABLE [dbo].[latch_contention_table] ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL --Create the index on the new partitioning scheme CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID] ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue]) ON ps_hash16(HashValue)
分区后,逻辑上INSERT仍然集中到表尾部,但是Hash分区将INSERT分散到各分区的B树的尾部。所以能减少Latch争用。如图:

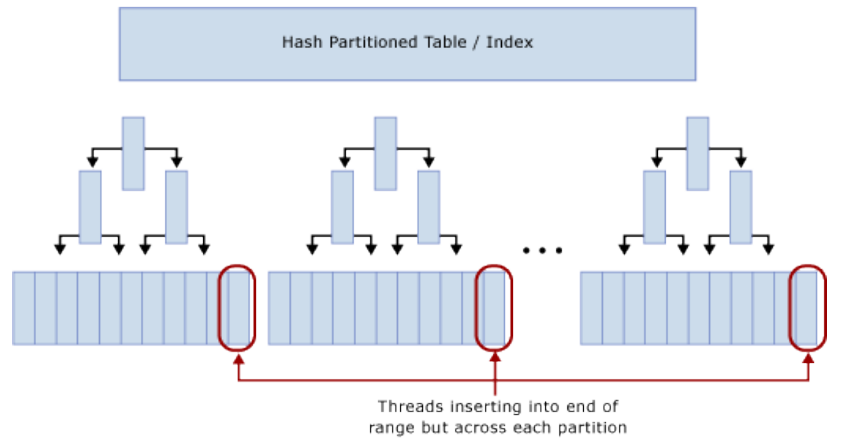
使用Hash分区消除INSERT的Latch争用,需要权衡的事项:
- 通常SELECT语句的查询谓词部分需要修改,使其包含Hash分区列。这会导致查询计划的分区消除不可用。
- 某些其它查询(如基于范围查询的报表)也不能使用分区消除。
- 当分区表与另一个表JOIN时,如果使用分区消除,则另一个表需要在同样的键上实现Hash分区并且Hash键需要包括在JOIN条件里。
- Hash分区会使滑动窗口归档和分区归档功能不可用。
总结
1. 本文以SQLCAT的Latch Contention白皮书为基础,结合Paul Randal关于Latch的博文,以及本人的经验而成。
2. Buffer Latch Contention较容易定位和处理。Non-Buffer Latch 是较为棘手的,因为太少关于此类型Latch的说明资料,造成有时定位到类型,也不知道它是什么意思,无从下手。
附加代码: