深度优先遍历算法是经典的图论算法,深度优先遍历算法的搜索逻辑跟它名字一样,只要有可能,就尽量深入搜索,知道找到答案,或者尝试了所有可能后确定没有解。
- 什么是深度优先遍历
- 二叉树
- 怎么获取最多元宝
什么是深度优先遍历
沿着一个目的不断的检索,直到把所有的问题都解决,再去检索下一个目的。
检索问题的本质就是试探问题的所有可能性,按照特定的规律和顺序,不断地去搜索答案,直到找到问题的解。若把所有可能都走一遍,也没找到解,就说明这个问题没有解。
二叉树
二叉树是一种特殊的数据结构。常见的数据结构包含数组、链表、图、队列、散列表与树。
二叉树的每一个节点都有两个分支,称为“左子树” 与 “右子树”。二叉树的每一层最多有(2^n - 1)个节点
二叉树的类型
- 空二叉树: 有零个节点
- 满二叉树: 每一个节点都有零个或者两个子节点
- 完全二叉树: 除了最后一层,每一层的节点都是满的,并且最后一层的节点全部从左排序
- 完美二叉树: 每一层的节点都是满的
- 平衡二叉树: 每个节点的两个子树的深度相差不超过1
二叉树的相关术语
| 术语 | 解释 |
|---|---|
| 度 | 节点的度为节点的子树个数 |
| 叶子节点 | 度为零的节点 |
| 分支节点 | 度不为零的节点 |
| 孩子节点 | 节点下的两个子节点 |
| 双亲节点 | 节点上一层的源头节点 |
| 兄弟节点 | 拥有同一个双亲节点的节点 |
| 根 | 二叉树的源头节点 |
| 深度 | 二叉树中节点的层的数量 |
二叉树的节点代码
因为每一个节点都与两个子节点相连,所以只需要拥有根节点就能找到二叉树任意节点。
class Node():
def __init__(self, x):
# 节点值
self.val = x
# 左侧节点
self.left = None
# 右侧节点
self.right = None
二叉树的遍历顺序
L、R、D分别代表左子树、右子树和根
- DLR(先序):先遍历根,再遍历左子树,最后遍历右子树
- LDR(中序):先遍历左子树,再遍历根,最后遍历右子树
- LRD(后序):先遍历左子树,再遍历右子树,最后遍历根
如图:
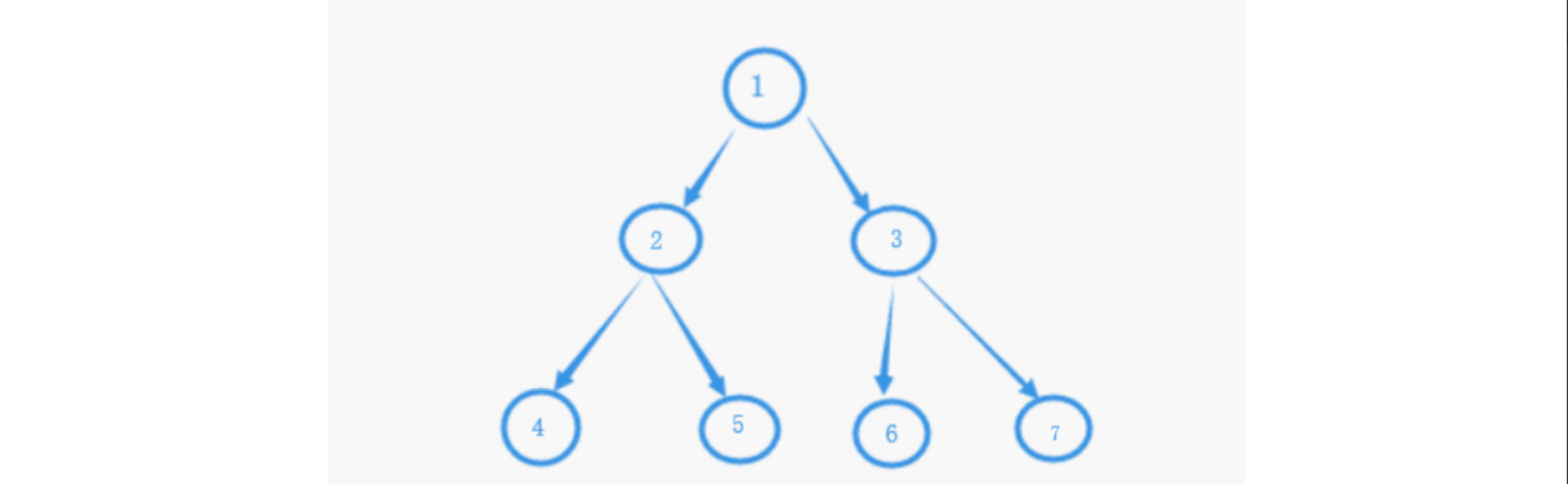
节点的访问顺序
- DLR(先序): 1-2-4-5-3-6-7
- LDR(中序): 4-2-5-1-6-3-7
- LRD(后序): 4-5-2-6-7-3-1
深度遍历与广度遍历
从先序,中序,后序年里都属于深度优先遍历。在深度优先遍历中,从根节点出发直奔最远的节点。而在广度优先遍历中,首先访问离根节点最近的节点,按层递进。以上图为例,顺序为:1-2-3-4-5-6-7.
怎么获取最多元宝
在游戏中,通过副本的矿场可以获取元宝,如下图所示,该副本的矿场以二叉树的结构坐落,除了第一座矿场,每一座矿场与另一座‘源头’连接。一旦闯入两栋相接的矿场,就会陷入绝境,从头开始。那怎么选择路线才能获取最多的元宝呢?(其中,圈内数据代表元宝的数量)

解题思路
首先,分析条件,两座相连的矿场被挖掘时会触发陷阱,将二叉树分层,若挖掘了第一层就不能挖掘第二层,所以有了不同的方案。
在每一个节点,都会有连个选择:挖与不挖。如果挖了这个节点,其子节点就不能挖了。
分析会发现:
- 每一个节点挖的值都是:左侧子节点的不挖值 + 右侧子节点的不挖值 + 节点的财富值。
- 每一个节点不挖的值都是:左侧子节点的最大值 + 右侧子节点的最大值
若在代码中定义节点,则可以
class Node():
'''二叉树节点的定义'''
def __init__(self, val):
# 财富值
self.val = val
# 左侧子节点
self.left = None
# 右侧子节点
self.right = None
那么,任何一个节点(用root表示)的挖值(rob_val)与不挖值(skip_val) 则可以
rob_val = root.val + root.left.skip_val +root.right.skip_val
skip_val = max(root.left.rob_val, root.left.skip_val) + max(root.right.rob_val, root.right.skip_val)
图中可以看出,可以将1,4,5,6节点挖出,或者2,3
class ThreeNode():
def __init__(self, val):
self.val = val
self.left = None
self.right = None
def rob(self, root):
a = self.helper(root)
return max(a[0], a[1])
def helper(self, root):
if root == None:
return [0, 0]
left = self.helper(root.left)
right = self.helper(root.right)
rob_val = root.val + left[1] +right[1]
skip_val = max(left[0], left[1]) + max(right[0], right[1])
return [rob_val, skip_val]
node1 = ThreeNode(3)
node2 = ThreeNode(4)
node3 = ThreeNode(5)
node4 = ThreeNode(1)
node5 = ThreeNode(3)
node6 = ThreeNode(1)
print('挖取1,4,5,6:',node2.rob(node4) + node2.rob(node5) + node3.rob(node6) + node2.rob(node1))
print('挖取2,3:', node1.rob(node2) + node1.rob(node3))
现在则需要解决:如可得到子节点的挖值与不挖值?利用递归深度优先遍历二叉树得