使用urllib库数据挖掘
第一个爬虫程序
import re from urllib import request #直接使用request中的方法 #import urllib.request #需使用urllib.request.方法 url=r"http://www.baidu.com/" #'r'去除转义字符 #2.1.数据挖掘 #发送请求,获取响应信息,request自动创建请求对象,不方便使用,信息以二进制输出 response1=request.urlopen(url).read().decode() #解码 #创建自定义请求 req=request.Request(url) response2=request.urlopen(req).read().decode() #解码 #2.2.数据清洗 pat=r"<title>(.*?)</title>" #正则表达式 data1=re.findall(pat,response1) #返回一个列表 data2=re.findall(pat,response2) #返回一个列表 print(data1) #['百度一下,你就知道'] print(data2) #['百度一下,你就知道']
自动创建请求对象:只封装了url信息,自动生成其他信息
自定义请求对象:可以自定义其他信息,对抗反扒机制
通过方法request.Request()创建自定义请求对象,再用request.urlopen()打开对象
伪装浏览器
反爬虫机制1:判断用户是否是浏览器访问
是否是浏览器通过请求包头的User-Agent进行判断,下面是谷歌浏览器的User-Agent
#伪装浏览器爬虫 import re from urllib import request #直接使用request中的方法 url=r"http://www.baidu.com/" #'r'去除转义字符 #通过字典构造请求头信息 header={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36" }#['百度一下,你就知道'] 谷歌浏览器 #创建自定义请求 req=request.Request(url,headers=header) #传入url和请求头 response=request.urlopen(req).read().decode() #解码 #2.2.数据清洗 pat=r"<title>(.*?)</title>" #正则表达式 data=re.findall(pat,response) #返回一个列表 print(data) #['百度一下,你就知道']
反爬虫机制2:判断用户是否一直使用同一个浏览器进行重复访问
添加多个UserAgent进行访问:
#伪装浏览器 import re #正则表达式 from urllib import request #直接使用request中的方法 import random #随机模块 url=r"http://www.baidu.com/" #'r'去除转义字符 #通过字典构造请求头信息 agent1={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36" }#['百度一下,你就知道'] 谷歌浏览器 agent2={ "User-Agent":"Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36" }#['百度一下'] 手机浏览器 agent3={ "User-Agent":"Mozilla/5.0 (Linux; U; Android 8.0.0; zh-CN; MHA-AL00 Build/HUAWEIMHA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 UCBrowser/11.6.4.950 UWS/2.11.1.50 Mobile Safari/537.36 AliApp(DingTalk/4.5.8) com.alibaba.android.rimet/10380049 Channel/227200 language/zh-CN" }#['百度一下'] 手机浏览器 agentList=[agent1,agent2,agent3] agent=random.choice(agentList) print(agent) #创建自定义请求 req=request.Request(url,headers=agent) #传入url和请求头 response=request.urlopen(req).read().decode() #解码 #2.2.数据清洗 pat=r"<title>(.*?)</title>" #正则表达式 data=re.findall(pat,response) #返回一个列表 print(data)
自定义Opener
我们之前一直都在使用的urlopen(),他是一个特殊的opener(也就是模块帮我们构建好的)。
但是基本的urlopen()方法不支持代理、cookie等其他的HTTP/HTTPS高级功能。所以要支持这些功能:
通过request.build_opener()方法创建自定义opener对象;使用自定义的opener对象,调用open()方法发送请求;
如果程序里的所有请求都使用自定义的opener,可以使用request.install_opener()将自定义的opener对象定义为全局opener,表示之后调用的urlopen,都将使用这个自定义的opener。
构建自定义的opener需传入处理器对象,通过request.HTTPHandler()、request.ProxyHandler()等方法创建。
代理:使用其他的ip进行访问服务器
cookie:客户信息
HTTP/HTTPS:网络传输协议(明文/加密)
#创建自定义opener from urllib import request #构建HTTP处理器对象(专门处理HTTP请求的对象) http_header=request.HTTPHandler() #创建自定义opener opener=request.build_opener(http_header) #创建自定义请求对象 req=request.Request("http://www.baidu.com/") #发送请求,获取响应,使用一次 # response=opener.open(req).read().decode() # print(response) #把自定义的opener设置为全局,这样用urlopen发送的请求默认使用自定义的opener request.install_opener(opener) response2=request.urlopen(req).read().decode() print(response2)
使用代理IP
反爬虫机制3:判断请求来源的ip地址
使用代理ip进行访问
#代理ip from urllib import request import random #多个代理ip proxylist=[ {"http":"182.111.64.7:41766"}, #key:协议 value:ip+port {"http":"182.111.64.7:41766"}, {"http":"101.248.64.82:80"}, ] proxy=random.choice(proxylist) #构建代理处理器对象 proxyHandler=request.ProxyHandler(proxy) #创建自定义opener opener=request.build_opener(proxyHandler) #创建请求对象 req=request.Request("http://www.baidu.com") #发生请求,返回相应 response=opener.open(req).read().decode() print(response)
处理get请求
请求信息包含在url里面。
#2.11.处理get请求
#在百度上搜索"北京" from urllib import request import urllib #https://www.baidu.com/s?wd=%E5%8C%97%E4%BA%AC #url编码 wd={"wd":"北京"} url="http://www.baidu.com/s?" #构造url编码 wdd=urllib.parse.urlencode(wd) url=url+wdd req=request.Request(url) response=request.urlopen(req).read().decode() print(response)
处理post请求
请求信息不在url里面,而是在From Data(表单数据)中。
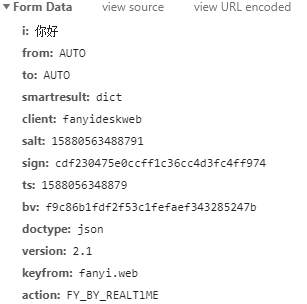
代码请看有道翻译爬虫实现
响应
响应分很多种,但我们无需知道响应是什么类型,我们只需要响应中是否能够提取到我们所需的信息。
异常处理
为了防止出现异常时程序死掉,就需要进行异常处理
from urllib import request list1=[ "http://www.baidu.com", "http://www.baidu.com", "http://www.wdnmd.com", "http://www.baidu.com", "http://www.baidu.com", ] i=0 for url in list1: i=i+1 try: request.urlopen(url) except Exception as e: print("第",i,"次请求失败",e) continue print("第",i,"次请求完成")
cookie模拟登录
cookie(存储再用户本地终端上的数据),是某些网站为了辨别用户身份,进行session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息。
from urllib import request url="http://www.baidu.com" #这cookie也太长了吧! header={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36", "Cookie":"BAIDUID=B75AA8C5F67A4BA4496FDAD7D121A9AE:FG=1; BIDUPSID=B75AA8C5F67A4BA4496FDAD7D121A9AE; PSTM=1561710602; BDUSS=khaRENTZWhWS0I3b1lQRDVmS3FJfnQ0ZGdPa0ZNckRNWi1oSmdJO DhYOVR2WFZlSVFBQUFBJCQAAAAAAAAAAAEAAADVDV8 YwbrIqNCkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFMwTl5TME5eZ ; H_WISE_SIDS=139912_142696_144498_143879_144884_141875_139043_ 141744_144419_144135_144470_144482_131247_137745_138883_ 141941_127969_144338_140593_144249_140350_144608_143923_ 131423_144277_114553_142207_144899_107313_139909_144954_ 143478_144966_142426_142911_140311_143549_144238_143862_ 110085; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; yjs_js_security_passport=cc7193919e4c28b6fad4dae83d92a4bd694e9d90_1588053148_js; delPer=0; PSINO=6; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; H_PS_PSSID=1461_21090_31254_31424_31341_30905_30824_26350_31163_31475_22158; PHPSESSID=0hmqvu0d6o9tneinc0l1asnj91; Hm_lvt_4010fd5075fcfe46a16ec4cb65e02f04=1588059785; Hm_lpvt_4010fd5075fcfe46a16ec4cb65e02f04=1588059785" }#谷歌浏览器 req=request.Request(url,headers=header) response=request.urlopen(req) print(response.read().decode())