
一.概述
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
了解:
MongoDB索引使用B树数据结构(确切说是B-Tree, Mysql是B+Tree)
二.索引类型
MongDB的索引分为以下几种类型:单键索引、复合索引、多键索引、地理空间索引、全文本索引和哈希索引。
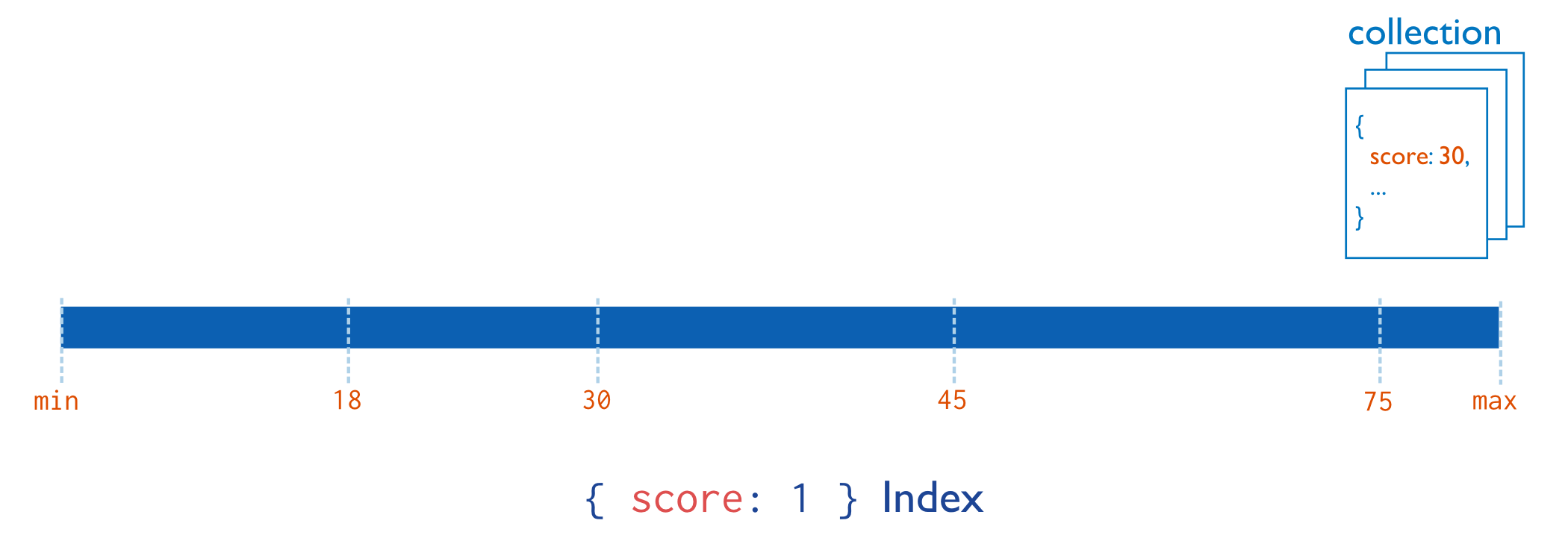
2.1 单键索引/单字段索引(Single Field Indexes)
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引,单键索引是最常见的索引,如MongoDB默认创建的_id的索引就是单键索引。
其存储结构如下图:
2.2复合索引
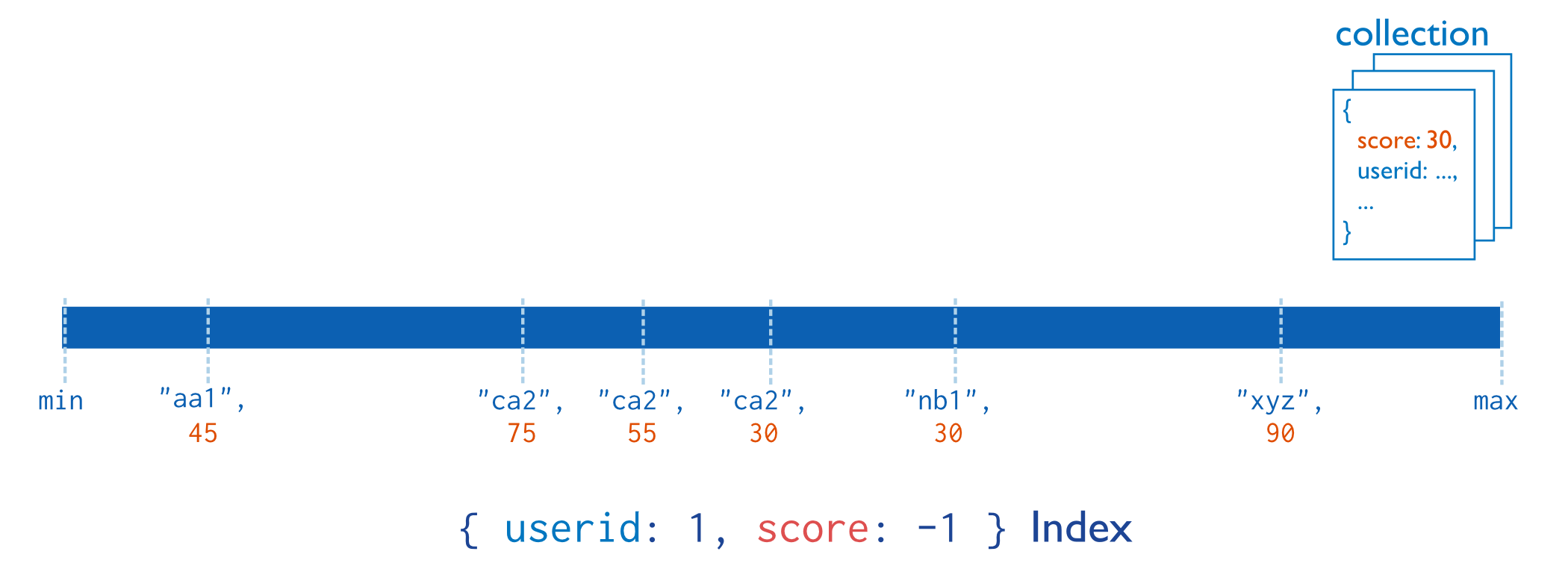
MongoDB还支持多个字段的用户定义类型,即复合索引(Compound Index)。
复合索引中列出的字段顺序具有重要的意义,列如,如果复合索引由{userid:1 score:-1}组成,则索引首先按userid正序排序,然后在每个userid的值内,再按score倒序排序。
其存储结构如下图:
2.3.多键索引(Multikey Index)
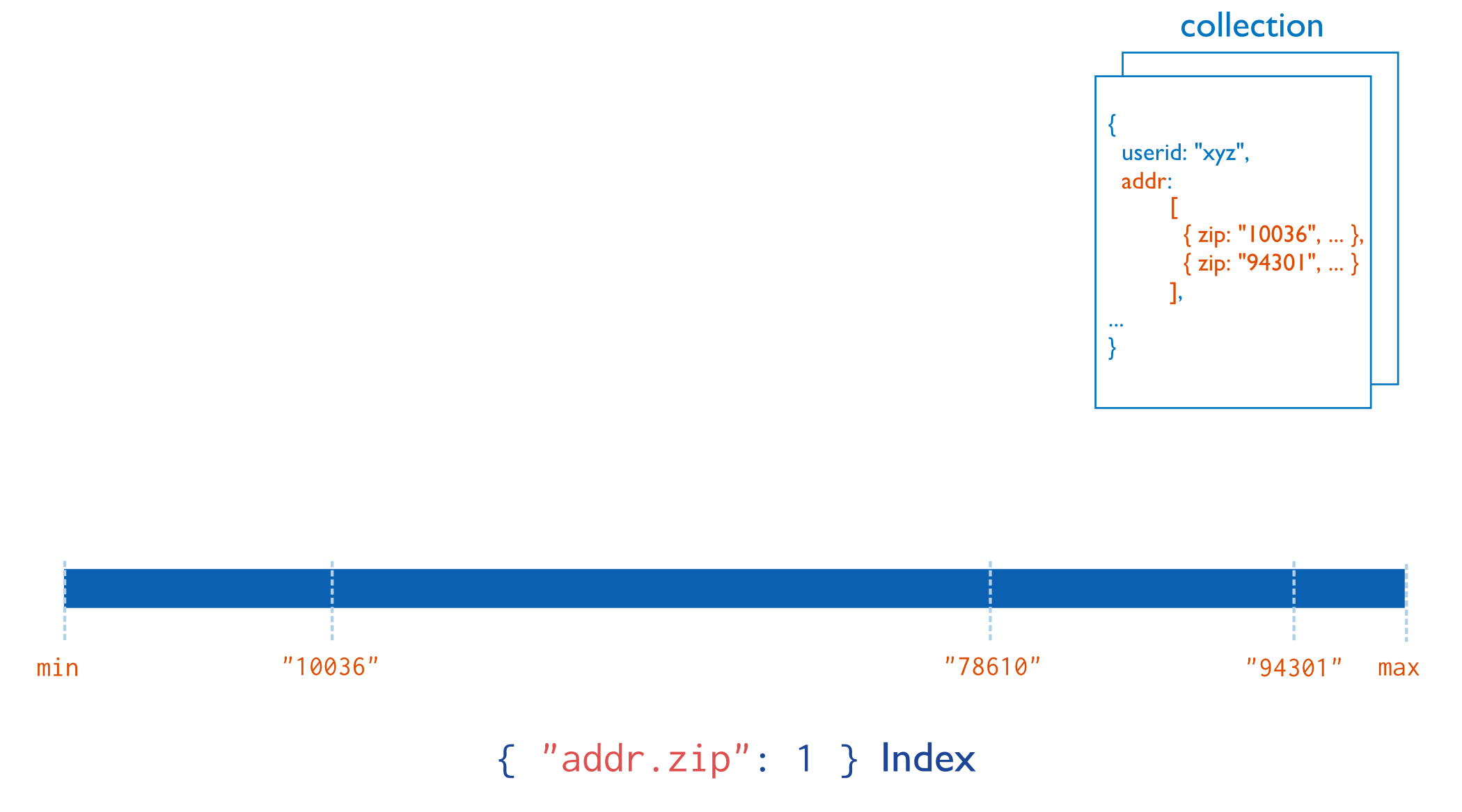
如果要索引数组类型的字段,MongoDB可以在数组每个元素上创建索引。这种多键索引可以有效的支持数组元素查询。多键索引建立在具体的值(比如字符串、数字)或内嵌文档的数组上。
多键索引结构如下:
2.4 地理空间索引(Geospatial Indexes and Queries)
MongoDB支持两种类型的地理空间索引。其中最常用的是 2dsphere 索引(用于地球表面类型的地图)和 2d 索引(用于平面地图和时间连续的数据)。
(1)2dsphere:
2dsphere允许使用GeoJSON格式(http://www.geojson.org)指定点、线和多边形。
2dsphere 支持 Point、MultiPoint、LineString、MultiLineString、Polygon、MultiPolygon、Geometry Collection
(2) 2d:
2d 索引用于扁平化表面,而不是球体表面,否则极点附近会出现大量的扭曲变形。
文档中使用包含两个元素的数组表示 2d 索引字段,不是 GeoJSON 的格式。
2d 索引只能对点进行索引。可以保存一个由点组成的数组,但是它只会被保存为由点组成的数组,不会被当成线。特别是对 $within 查询来说,数组中的某个点在查询范围内,该文档就会被找出。
2.5 全文索引(Text Indexes)
全文索引用于在文档中搜索文本,我们也可以使用正则表达式来查询字符串,但是当文本块比较大的时候,正则表达式搜索会非常慢,而且无法处理语言理解的问题(如 entry 和 entries 应该算是匹配的)。使用全文索引可以非常快地进行文本搜索,就如同内置了多种语言分词机制的支持一样。创建索引的开销都比较大,全文索引的开销更大。创建索引时,需后台或离线创建。
2.6哈希索引(Hashed Index)
哈希索引可以支持相等查询,但是哈希索引不支持范围查询。您可能无法创建一个带有哈希索引键的复合索引或者对哈希索引施加唯一性的限制。但是,您可以在同一个键上同时创建一个哈希索引和一个递增/递减(例如,非哈希)的索引,这样MongoDB对于范围查询就会自动使用非哈希的索引。
三.索引管理
3.1索引的查看
返回一个集合中所有索引的数组
语法:
db.comment.getIndexes()
提示:该语法的运行时MongoDB 3.0+
实例:查看comment集合中的所有索引情况

3.2 索引的创建
MongoDB使用 createIndex() 方法来创建索引。
注意: 注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
语法:
db.comment.createIndex(keys, options)
keys:语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
options: 可选,包含一组控制索引创建的选项的文档,有关详细信息,请参见选项详情列表。
options可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
3.2.1 单字段索引实例:对userid字段按升序建立索引 ,语法如下:
db.comment.ensureIndex( { "userid" : 1 } )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
可以查看索引如下:
db.comment.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "test.comment" }, { "v" : 2, "key" : { "userid" : 1 }, "name" : "userid_1", "ns" : "test.comment" } ]
索引名字为:userid_1
compass查看:
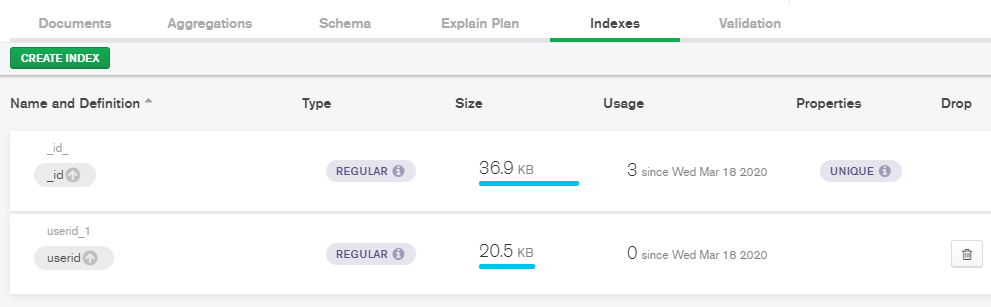
3.2.2 复合索引:对userid和nickname同时建立复合索引:
db.comment.ensureIndex( { userid : 1,nickname:-1 } )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
compass查看:
3.3 索引移除
说明:可以移除指定的索引,也可以移除所有的索引
语法:
db.comment.dropIndex(Index)
Index:指定要删除的索引,可以通过索引名称或者索引规范文档指定索引。若要删除文本索引,请指定索引名称。
案列1,单个索引的移除: 删除comment集合中userid字段的升序索引:
db.comment.dropIndex({userid:1}) 或者 db.comment.dropIndex("userid_1")
compass查看:

案列2,所有索引的移除:
语法:
db.comment.dropIndexes()
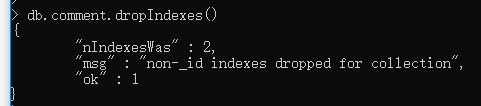
提示:_id字段的索引是无法删除的,只能删除非 _id字段的索引。
3.4 索引的使用
3.4.1 执行计划
分析查询性能,通常使用执行计划来查看查询的情况,如查询耗费的时间,是否基于索引查询等。
通常,我们想知道,建立的索引是否生效,效果如何,都需要通过执行计划查看。
语法如下:
db.comment.find(query,options).explain(options)
案列1 查询userid等于1003的索引使用情况
db.comment.find({userid:1003}).explain()
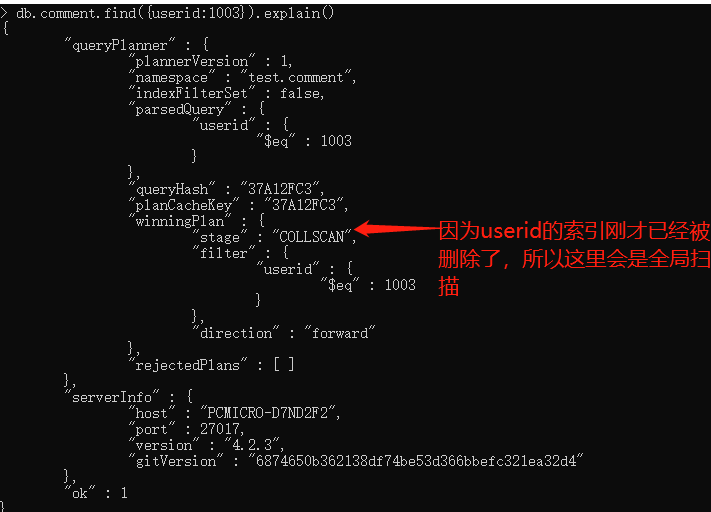
案列2 对userid升序创建索引之后查询userid等于1003的索引使用情况
db.comment.createIndex({userid:1}) //创建索引
db.comment.find({userid:1003}).explain()//再次查询索引使用情况
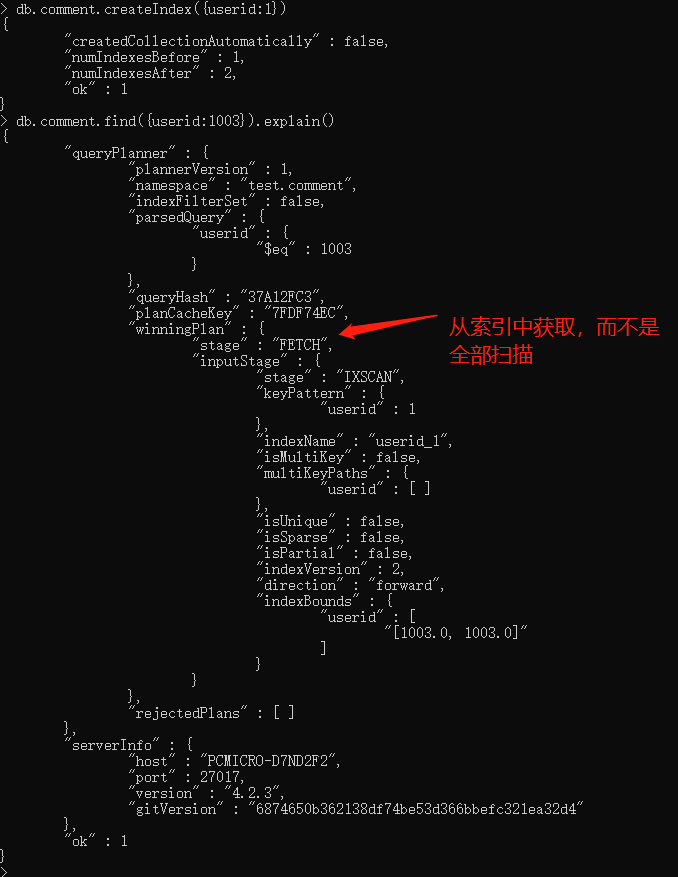
3.4.2 涵盖的查询
官方的MongoDB的文档中说明,覆盖查询是以下的查询:
-
所有的查询字段是索引的一部分
-
所有的查询返回字段在同一个索引中
因为所有出现在查询中的字段是索引的一部分, MongoDB 无需在整个数据文档中检索匹配查询条件和返回使用相同索引的查询结果。
因为索引存在于RAM中,从索引中获取数据比通过扫描文档读取数据要快得多。案列1 首先前面我们对userid这个字段创建了索引的,所以我们根据索引查询,且只需要查询userid字段,使用投影查询,语法如下:
db.comment.find({userid:1002},{userid:1,_id:0})

compass查看:
