一、前述
Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架。
二 、搭建流程
1.集群规划
Nimbus Supervisor Zookeeper
node01 1
node02 1 1
node03 1 1
node04 1 1
2.配置
node01作为nimbus。
vim conf/storm.yaml
storm.zookeeper.servers: - "node02" - "node03" - "node04" storm.local.dir: "/tmp/storm" nimbus.host: "node01" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
PS:supervisor.slots.ports 相当于启动4个worker进程
配置一定要顶格写!!!!!!!
3.创建log文件
在storm目录中创建logs目录
mkdir logs启动ZooKeeper集群
4.启动服务
node1上启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
tail -f logs/nimbus.log
./bin/storm ui >> ./logs/ui.out 2>&1 &
tail -f logs/ui.log
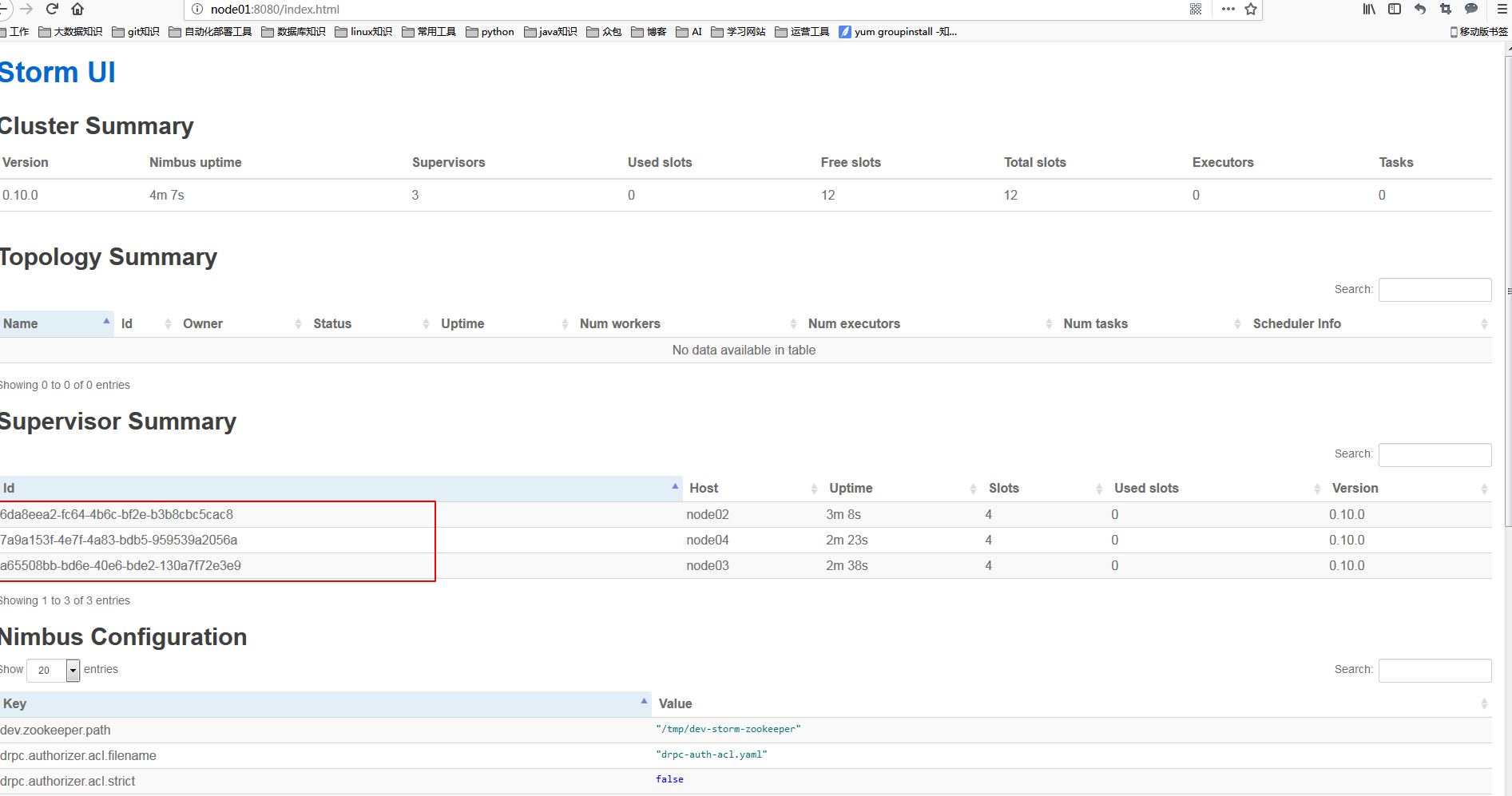
节点node02和node03,node04启动supervisor,按照配置,每启动一个supervisor就有了4个slots
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
tail -f logs/supervisor.log
(当然node1也可以启动supervisor)
http://node1:8080/
提交任务到Storm集群当中运行:
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test
环境变量可以配置也可以不配置
export STORM_HOME=/opt/sxt/storm
export PATH=$PATH:$STORM_HOME/bin