官方 HBase-MapReduce
1.查看 HBase 的 MapReduce 任务的执行
[lxl@hadoop102 hbase]$ bin/hbase mapredcp
2.环境变量的导入
(1)执行环境变量的导入(临时生效,在命令行执行下述操作)
$ export HBASE_HOME=/opt/module/hbase $ export HADOOP_HOME=/opt/module/hadoop-2.7.2 $ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
(2)永久生效:在/etc/profile 配置
export HBASE_HOME=/opt/module/hbase export HADOOP_HOME=/opt/module/hadoop-2.7.2
并在 hadoop-env.sh 中配置:(注意:在 for 循环之后配)
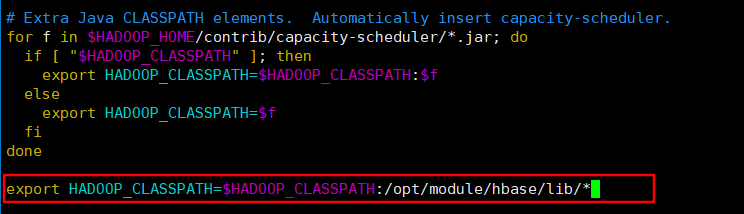
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*
分发:
[lxl@hadoop102 hadoop-2.7.2]$ xsync etc/hadoop/hadoop-env.sh
3.运行官方的 MapReduce 任务
-- 案例一:统计 Student 表中有多少行数据
[lxl@hadoop102 hbase]$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter student
-- 案例二:使用 MapReduce 将本地数据导入到 HBase
1)在本地创建一个 tsv 格式的文件:fruit.tsv
[lxl@hadoop102 hbase]$ vi fruit.tsv
1001 Apple Red 1002 Pear Yellow 1003 Pineapple Yellow
2)创建 HBase 表
hbase(main):001:0> create 'fruit','info'
3)在 HDFS 中创建 input_fruit 文件夹并上传 fruit.tsv 文件
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put fruit.tsv /
4)执行 MapReduce 到 HBase 的 fruit 表中
[lxl@hadoop102 hbase]$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit hdfs://hadoop102:9000/fruit.tsv
5)使用 scan 命令查看导入后的结果
hbase(main):004:0> scan "fruit" ROW COLUMN+CELL 1001 column=info:color, timestamp=1560441335521, value=Red 1001 column=info:name, timestamp=1560441335521, value=Apple 1002 column=info:color, timestamp=1560441335521, value=Yellow 1002 column=info:name, timestamp=1560441335521, value=Pear 1003 column=info:color, timestamp=1560441335521, value=Yellow 1003 column=info:name, timestamp=1560441335521, value=Pineapple