Sub excel连接数据库() Dim Con As New ADODB.Connection Dim strCon, strsql As String Dim rs As ADODB.Recordset '设置记录集 Dim i, t, path_ path_ = ThisWorkbook.path & "" t = Timer
连接字符串 strCon = "Provider=Microsoft.Ace.OLEDB.12.0;Extended Properties='Excel 12.0;imex=0';Data Source=F: ewv511.xlsx"
关联多个文件查询 ' strsql = "select a.id,a.firstname,b.lastname from [a1$] a left join [Excel 8.0;hdr=1;imex=1;Database=C:UsersAdministratorDesktopa2.xlsx].[a2$] b on a.id=b.id"
表名的表示方式 [] 中括号包起来,里面是sheet名称+$符号 ' strsql = "select a.id,a.firstname,b.lastname from [EDM-10$] a left join [a2$] b on a.id=b.id" 有些数字查出来后会变成 1900-01-10 12:00:00,看起来是个日期,处理方式就是*1,让它重新变回数字 strsql = "select a.内部订单号,a.R * 1 from [CNC-11$] a where a.内部订单号 <> '内部订单' "
各种函数的使用,还可以嵌套,但是要注意嵌套的先后顺序,比如这个distinct,要达到真正的效果,就得在最外层
' strsql = " select distinct(UCASE(trim(a.D))) as id from [G-10$] a where a.D <> '内部订单' "
结果集合并,就是一个累加行的过程 ' strsql = "" ' strsql = strsql + " select distinct(UCASE(trim(a.D))) as id from [EDM-10$] a where a.D <> '内部订单' " ' strsql = strsql + " union " ' strsql = strsql + " select distinct(UCASE(trim(a.D))) as id from [G-10$] a where a.D <> '内部订单' " Con.Open strCon Set rs = Con.Execute(strsql)
这个是查询所有sheet的名字 ' Set rs = Con.OpenSchema(20) 'adSchemaTables=20 ' Columns("A:A").NumberFormatLocal = "m""月""d""日"";@" For i = 0 To rs.Fields.Count - 1 Sheets("lcx").Cells(1, i + 1) = rs.Fields(i).Name Next i Sheets("lcx").Cells(2, 9).CopyFromRecordset rs rs.Close Con.Close Set rs = Nothing Set Con = Nothing Debug.Print "提取完毕" & "耗时" & Round(Timer - t, 4) & "秒" End Sub
需要引用的project有3个:
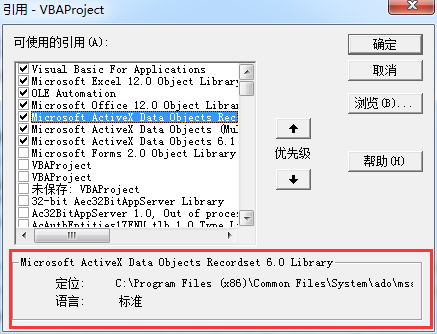
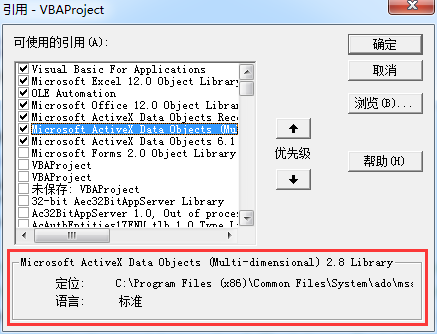

补充
Sub lcxreaddata() Dim fname As String, path As String, cnn As Object, rst As ADODB.Recordset, sql As String
使用createobject的方式,不需要引入相应的project,可以直接使用 Set cnn = CreateObject("ADODB.Connection") fname = "11.xlsx" path = "F: ewv5" & fname cnn.Open "Provider=Microsoft.Ace.OLEDB.12.0;Extended Properties='Excel 12.0;imex=0';Data Source=" & path
$符号后面可以加查询的范围 ' sql = "SELECT [Actual],[Upper Tol] FROM [Report$a13:f100] where Characteristic='" & cname & "'"
有特殊符号的字段,用中括号括起来就可以使用了,否则需要打开表替换字段名称,关闭的时候还要还原,是不是好傻的操作,都怪以前没有get到这个技能 ' sql = " SELECT [新模/修模],[实际产出(H)] FROM [CNC-11$a:r] where [实际产出(H)] <> 0 "
where后面的条件匹配要注意类型,字符串类型的字段用字符串匹配,数字类型的列用数字匹配,否则会报类型不匹配的错误,还有就是,如果两个表关联查询的时候,两个关联的字段的类型必须一致,否则也会报类型不匹配的错误 sql = " SELECT [新模/修模],[实际产出(H)] FROM [CNC-11$a:r] where trim([新模/修模]) <> '' " Set rst = cnn.Execute(sql) Sheets.Add For i = 0 To rst.Fields.Count - 1 Cells(1, i + 1) = rst.Fields(i).Name Next i Cells(2, 1).CopyFromRecordset rst cnn.Close Set rst = Nothing Set cnn = Nothing End Sub
'excel 8.0;hdr=no',此设置决定没有字段名,设置hdr=no时,默认标题字段为F1,F2…………
将EXCEL文件作为数据库连接,实际并不打开EXCEL,
Excel2003版本:cnn.Open "Provider=Microsoft.jet.OLEDB.4.0;Extended Properties=Excel 8.0;Data Source=" & ThisWorkbook.Path & "数据表.xls"
Excel2007版本:cnn.Open "Provider=Microsoft.ACE.OLEDB.12.0;Extended Properties=Excel 12.0;Data Source=" & ThisWorkbook.Path & "数据表.xlsx"
带参数的连接字符串:cnn.Open "provider=microsoft.jet.oledb.4.0;extended properties='excel 8.0;HDR=yes;IMEX=2';data source=" & ThisWorkbook.FullName
HDR=Yes 代表 Excel 档中的工作表第一行是标题栏,标题只能是一行,不能使多行,或者合并的单元格。
HDR=no 工作表第一行就是数据了,没有标题栏,不使用栏位,则栏位就以f代表,第一列列名就是:f1,第二列列名:f2
IMEX 汇入模式 0 只读 1 只写 2 可读写
当 IMEX=0 时为“汇出模式”,这个模式开启的 Excel 档案只能用来做“写入”用途。
当 IMEX=1 时为“汇入模式”,这个模式开启的 Excel 档案只能用来做“读取”用途。
当 IMEX=2 时为“连结模式”,这个模式开启的 Excel 档案可同时支援“读取”与“写入”用途。
Data Source 存储查询数据来源的工作薄名称,数据库路径为:数据表.xls 或本表:& ThisWorkbook.FullName
oledb也能将txt当数据库来查询
Sub 读count_个数求和后写入sum(fpath, fname, sumfile) Call CreateSchema(fpath, fname, "false", 6) Dim cn As Object, rs As Object Dim strsql As String Set cn = CreateObject("ADODB.Connection") cn.Open "Provider=Microsoft.ACE.OLEDB.12.0;Extended Properties='text;';Data Source=" & fpath strsql = " select f1,f2,f3,f4,f5,sum(f6) from [" & fname & "] group by f1,f2,f3,f4,f5 order by f1*1,f2*1,f3*1,f4*1,f5*1 " Set rs = cn.Execute(strsql) sumfile.Write "列1" & vbTab & "列2" & vbTab & "列3" & vbTab & NW & "个数" & vbTab & ML & "个数" & vbTab & "数量" sumfile.WriteLine rs.GetString(, , , vbCrLf) 这个一定要记得关,否则当txt数据量庞大的时候,比如我测试的时候,用的3个50万行数据的txt,一个一个按顺序读,如果不关,就会很卡,关了就会很顺畅 rs.Close cn.Close Set rs = Nothing Set Con = Nothing Call KillSchema(fpath) End Sub
Sub CreateSchema(fpath, fname, hdr, cc) Dim fso, MyFile, i Set fso = CreateObject("Scripting.FileSystemObject") Set MyFile = fso.CreateTextFile(fpath & "schema.ini", True) MyFile.WriteLine "[" & fname & "]" MyFile.WriteLine "COLNAMEHEADER = " & hdr MyFile.WriteLine "Format = TabDelimited" For i = 1 To cc MyFile.WriteLine "Col" & i & " = f" & i & " Char" Next MyFile.Close Set fso = Nothing End Sub Sub KillSchema(fpath) Kill fpath & "schema.ini" End Sub
如果是标准逗号隔开的txt文件,直接用下面的连接字符串就可以了,就不用写schema.ini文集了
cn.Open "Provider=Microsoft.ACE.OLEDB.12.0;Extended Properties='text;IMEX=1;HDR=NO;FMT=Delimited;';Data Source=" & ThisWorkbook.Path
schema.ini文件可以定义字段类型,分隔符符号等,在同目录下要建一个Schema.ini说明txt文件的数据格式,例:
[code=INIFile] [customers.txt] Format=TabDelimited ColNameHeader=True MaxScanRows=0 CharacterSet=ANSI characterset默认就是ansi,所以也可以不用指定
[orders.txt] Format=Delimited(;) ColNameHeader=True MaxScanRows=0 CharacterSet=ANSI [invoices.txt] Format=FixedLength ColNameHeader=False Col1=FieldName1 Integer Width 15 Col2=FieldName2 Date Width 15 Col3=FieldName3 Char Width 40 Col4=FieldName4 Float Width 20 CharacterSet=ANSI[/code]
再说一个查询结果写入txt的示例
Sub 读count_个数求和后写入sum(fpath, fname, sumfile) Call CreateSchema(fpath, fname, "false", 6) Dim cn As Object, rs As Object Dim strsql As String Set cn = CreateObject("ADODB.Connection") cn.Open "Provider=Microsoft.ACE.OLEDB.12.0;Extended Properties='text;';Data Source=" & fpath strsql = " select f1,f2,f3,f4,f5,sum(f6) from [" & fname & "] group by f1,f2,f3,f4,f5 order by f1*1,f2*1,f3*1,f4*1,f5*1 " Set rs = cn.Execute(strsql)
rs.getstring有多个参数,分别是:
rs.GetString(StringFormat,NumRows,ColumnDelimiter,RowDelimiter,NullExpr)
默认的换行符是 ,但是txt的换行符是 ,所以如果不设置一下RowDelimiter,打开txt就不会有换行的效果,word打开的话是有换行效果的,word里 是被识别的
表头用write不用writeline,是因为用writeline会多出一个空行,我估计是因为rs返回的字符串,首行前可能有换行符吧,具体的也没有去研究
sumfile.Write "列1" & vbTab & "列2" & vbTab & "列3" & vbTab & "列4" & vbTab & "列5" & vbTab & "列6" sumfile.WriteLine rs.GetString(, , , vbCrLf) rs.Close cn.Close Set rs = Nothing Set Con = Nothing Call KillSchema(fpath) End Sub
有很多方式读写数据,但是发现的最快的方式,就是sql,具体为什么,也没有去研究过
还有就是 Microsoft.jet.OLEDB.4.0; 和 Microsoft.ACE.OLEDB.12.0; 两种连接,我的电脑都是支持的,但是有个别电脑不支持jet4.0的,具体原因我也没有去研究过
这些我没有研究过的地方,如果有哪位大神知道的,还望能解答迷惑