比Redis更快:Berkeley DB面面观
比Redis更快:Berkeley DB面面观
Redis很火,最近大家用的多。从两年前开始,Memcached转向Redis逐渐成为潮流;
而Berkeley DB可能很多朋友还很陌生,首先,我们简单的介绍一下。
Berkeley DB介绍
- 历史悠久。Berkeley DB1991年发行第一版, 2006年被Oracle收购;
- Berkeley DB是一个嵌入式数据库系统,将其归类到内存数据库范畴没有问题;
-
使用Key-Value结构存储,本身不支持SQL,5.5版以后整合了SQLite,可使用sql进行查询;官方资料给出的评估是如果原生的bdb能让性能提升10倍,使用SqlLite之后,大概就只有2-3倍;sql的解析及底层的衔接耗时较多;
-
开源产品,使用的开源协议为: AFFERO GPL (AGPL)。这个协议对商用产品主要的约束是对与使用Berkeley DB的软件,发布软件包时需要付费;举个例子:如果微软的office要使用则必须付费;而腾讯的QQ后台服务器使用则无需付费;
Berkeley DB设计思想
简单、小巧、可靠、高性能。
DB库和应用运行在同一进程空间,接口为API形式,应用通过API存取DB;
应用范例
MySQL 5.1版之前的数据事务存储引擎使用的是Berkeley DB;(5.1版之后不再使用更多的可能是出于商业的原因,因为Berkeley DB被Oracle收购了)
Google Accounts选用的Berkeley DB作为存储引擎;
Berkeley DB VS Redis
除了速度,Berkeley DB的最大的优势是支持多索引(次级索引);支持多索引,使得从关系型DB中移植到内存DB更容易,可有效避免数据膨胀及自行处理索引之间的映射关系;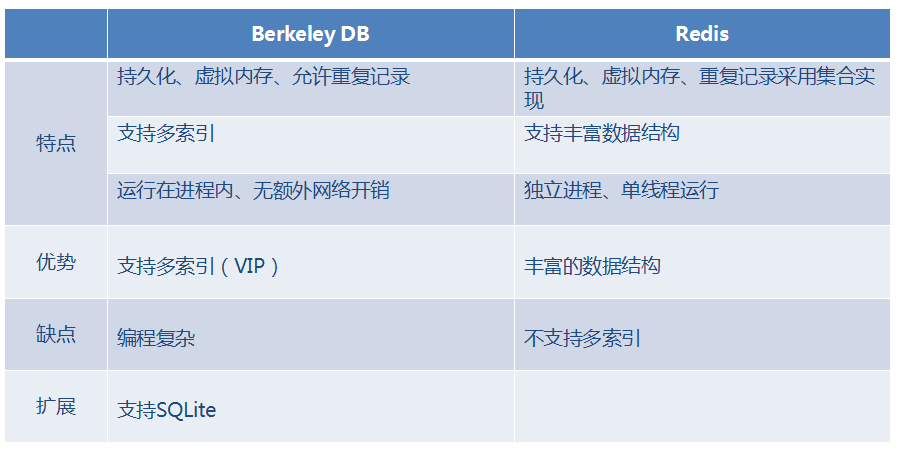
eg:一张学生信息表,以学号为主键(唯一性索引)建立了索引可以查询到指定的学生记录;如果再希望以姓名来查询,可以以姓名为键建立次级索引来查询;
在查询条件比较复杂的情况下,可组合建立多个次级索引来找到同一份数据;
想进一步了解次级索引如何使用,可参考这篇文章:《Berkeley DB多索引查询》
性能测试对比:Berkeley DB VS Redis
使用环境:
CPU:Intel Core 2 Duo P9xxx 2.0G
MEM:16G
OS:Red Hat Enterprise Linux Server release 6.3 (Santiago) x86_64同样是内存数据库,我们对比Berkeley DB和Redis的运行时间(单位:ms)
A表记录:506622条记录:每条记录:96个字节
B表记录:2478条记录;每条记录:10个字节;
C表记录:107221条记录;每条记录:82个字节;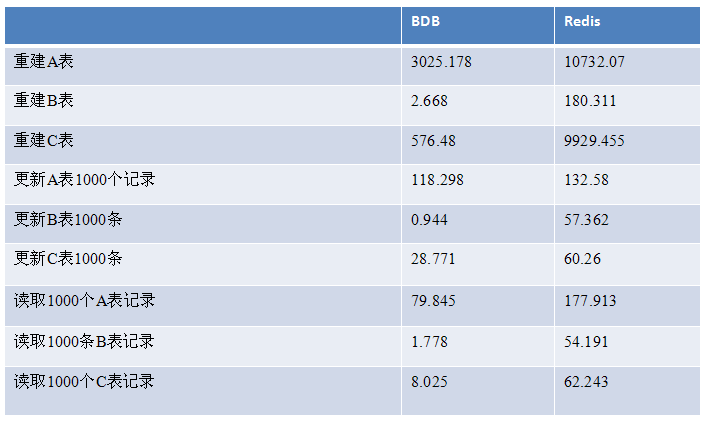
重建内存数据库 BDB用4s,Redis 20s;
更新内存数据库,BDB和Redis的实验结果都比较理想
查询记录时,BDB比Redis基本快一个数量级;
缓存、重建整个表操作,BDB性能明显优于Redis;这是因为BDB提供批量读取所有数据的接口,而Redis没有提供类似的接口;
性能对比测试:Berkeley DB VS Oracle
为了将数据从Oracle中移植出来,我们需要对比关系型数据库和Berkeley DB的查询效率:
首先,我们使用唯一性索引作为Berkeley DB的主键,并因此查询来和oracle对比;
数据规模:
实验数据;1112516条记录:
大小2.8G;以查询出最终结果为准:
SQL查询:
SELECT * FROM table_a
WHERE (DATE=to_date(:v, 'YYYYMMDD') AND A =:a AND B =:b AND c>=:c AND D>=:d) AND ( E=:e) AND (F=:F) AND (G=:g) AND H!='C' AND N='N'";
其中>= 、 !=操作无法编入索引,在索引查处数据后需应用再进行筛选过滤;
最终的查询结果为一条记录;
如果这篇文章让你对Berkeley DB产生了兴趣,如果你也想着效率那点事,想着将关系数据库转到nosql,试着上手吧。传送门:《Berkeley DB入门篇》。
Posted by: 大CC | 31OCT,2013