分库解决方案—实际操作
目录
- 流程图
- 数据库设计
- 测试数据说明
- 问题以及难点
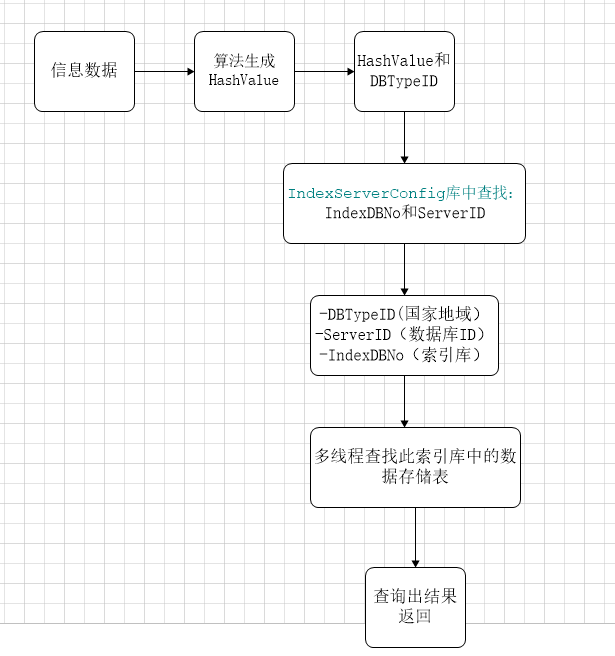
一、流程图

说明:
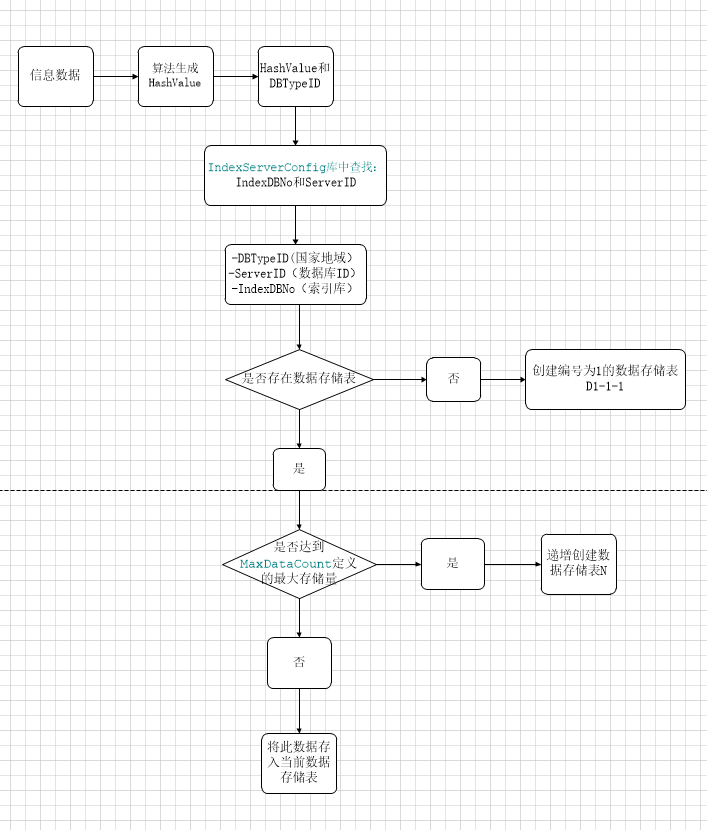
1、 信息数据汇总后,有处理程序处理,根据算法,分发到算法指定的数据库服务器上的索引库,直到存到对应索引库下面的数据存储表。
2、每个地域也就是国家,下面可以有多台数据服务器,但是此地域(国家)下面的索引库不能重复。因为这样方便后续数据查询。
3、当有数据到达索引库后,需要存储数据的情况下。默认情况下,索引库下没有存储表。此时程序会创建第一个存储表。当数据达到我们规定此存 储表的存储上限时,就会创建第二个存储表,后续的数据,就会存到第二个存储表中。以此类推。
二、数据库设计
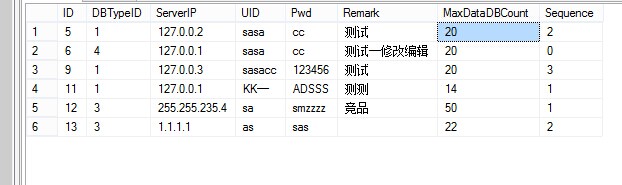
1、数据库服务器配置表:DBServer
[ID] : 主键
[DBTypeID]:数据库类型ID(例如:国内1=D1、国内2=D2、国外1=H1)
[ServerIP] :数据库服务器IP
[UID] :用户名
[Pwd]:密码
[Remark]:备注说明
[MaxDataDBCount] :最多可以创建多少个数据存储表
[Sequence]:排序
问题:
为什么要有 [MaxDataDBCount] 字段? —— 限制数据存储表的创建,因为每台服务器的性能不一样。要求也不一样。
为什么要有 [Sequence]字段? —— 调整数据库先后顺序,方便数据插入
[DBTypeID]与[ServerIP]的关系 —— 这里的数据库类型我们可以比作是区域,一个区域可以分布多台数据库。
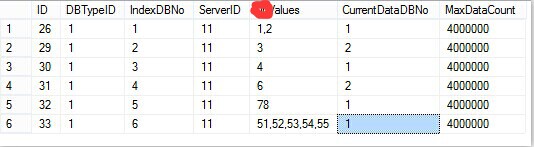
2、索引数据库配置表:IndexServerConfig
[ID]:主键
[DBTypeID]:数据库类型ID(例如:国内1=D1、国内2=D2、国外1=H1)
[IndexDBNo]:索引库编号
[ServerID]:当前索引库所在的数据库服务器ID
[HashValues]:数据根据算法生成的HashValues(0~255)
[CurrentDataDBNo]:当前索引库对应的数据存储表编号
[MaxDataCount]:对应的当前数据存储表的最大数据存储量
说明:
1、[HashValues]:就是我们根据数据特性和定义的相关算法生成的对应的值,此处的[HashValues]是这些值得集合。
2、 [IndexDBNo]与 [HashValues]的对应关系
例如:
IndexDBNo HashValues
1 0,1,2,3,4,5,6,7
2 11,12,13
5 221,222,223,224,225
3、如上流程图所示,每个地域国家[DBTypeID]可以对应多台数据库服务器,但是地域下面的索引 [IndexDBNo]与【HashValues】一一对应不能重复。
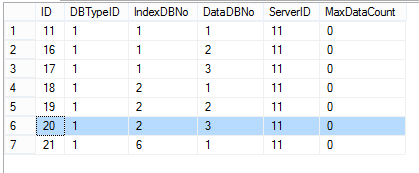
3、存储信息数据库配置:DataServerConfig
[ID]:主键
[DBTypeID]:数据库类型ID(例如:国内1=D1、国内2=D2、国外1=H1)
[DataDBNo]:数据存储表编号
[IndexDBNo]:索引库编号
[ServerID]:服务器编号
[MaxDataCount]:当前数据存储表自定义的最大存储量
三、测试流程
数据库服务器配置表:DBServer
索引数据库配置表:IndexServerConfig
存储信息数据库配置:DataServerConfig
一条信息数据过来后,通过算法转换成HashValue=2,此信息是国家地域编号 DBTypeID=1的数据。
根据 HashValue=2 和 DBTypeID=1 ,我们到 索引数据库配置表:IndexServerConfig中找到相关索引数据
我们看到上图中的第一条数据符合我们的标准,它所对应的数据库服务器编号IndexDBNo=1,ServerID=11
这样我们就可以根据 DBTypeID=1 和 ServerID=11 和 IndexDBNo=1。找到具体什么地域下的哪台数据库中的索引库下的数据存储表。
总结:
数据存储
数据查询:
四、问题难点——后续补充