分布式调用跟踪系统的设计和应用
>>为什么需要分布式调用跟踪系统
随着分布式服务架构的流行,特别是微服务等设计理念在系统中的应用,业务的调用链越来越复杂,

可以看到,随着服务的拆分,系统的模块变得越来越多,不同的模块可能由不同的团队维护,
一个请求可能会涉及到几十个服务的协同处理, 牵扯到多个团队的业务系统,那么如何快速准确的定位到线上故障?
同时,缺乏一个自上而下全局的调用id,如何有效的进行相关的数据分析工作?
对于大型网站系统,如淘宝、京东等电商网站,这些问题尤其突出。
一个典型的分布式系统请求调用过程:

比较成熟的解决方案是通过调用链的方式,把一次请求调用过程完整的串联起来,这样就实现了对请求调用路径的监控。
>>调用跟踪系统的业务场景
(1)故障快速定位
通过调用链跟踪,一次请求的逻辑轨迹可以用完整清晰的展示出来。
开发中可以在业务日志中添加调用链ID,可以通过调用链结合业务日志快速定位错误信息。
(2)各个调用环节的性能分析
在调用链的各个环节分别添加调用时延,可以分析系统的性能瓶颈,进行针对性的优化。
(3)各个调用环节的可用性,持久层依赖等
通过分析各个环节的平均时延,QPS等信息,可以找到系统的薄弱环节,对一些模块做调整,如数据冗余等。
(4)数据分析等
调用链是一条完整的业务日志,可以得到用户的行为路径,汇总分析应用在很多业务场景。
>>分布式调用跟踪系统的设计
(1)分布式调用跟踪系统的设计目标
低侵入性,应用透明:
作为非业务组件,应当尽可能少侵入或者无侵入其他业务系统,对于使用方透明,减少开发人员的负担
低损耗:
服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,
实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径
大范围部署,扩展性:
作为分布式系统的组件之一,一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性
(2)埋点和生成日志
埋点即系统在当前节点的上下文信息,可以分为客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。
埋点日志通常要包含以下内容:
TraceId、RPCId、调用的开始时间,调用类型,协议类型,调用方ip和端口,请求的服务名等信息;
调用耗时,调用结果,异常信息,消息报文等;
预留可扩展字段,为下一步扩展做准备;
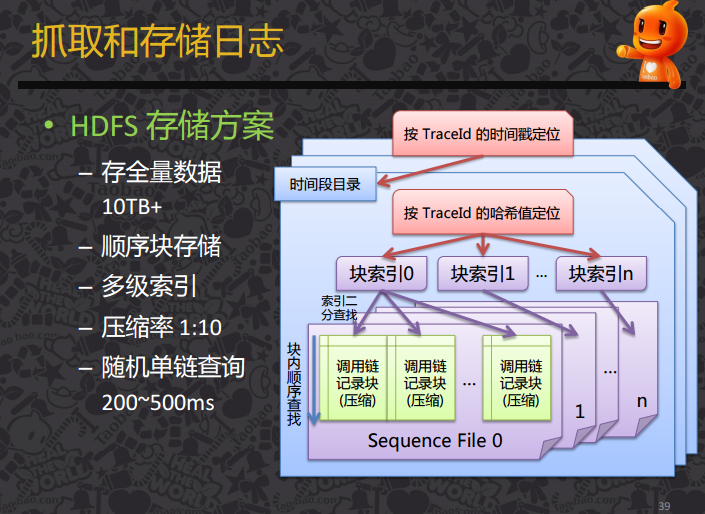
(3)抓取和存储日志
日志的采集和存储有许多开源的工具可以选择,
一般来说,会使用离线+实时的方式去存储日志,主要是分布式日志采集的方式。
典型的解决方案如Flume结合Kafka等MQ。
(4)分析和统计调用链数据
一条调用链的日志散落在调用经过的各个服务器上,
首先需要按 TraceId 汇总日志,然后按照RpcId 对调用链进行顺序整理。
调用链数据不要求百分之百准确,可以允许中间的部分日志丢失。
(5)计算和展示
汇总得到各个应用节点的调用链日志后,可以针对性的对各个业务线进行分析。
需要对具体日志进行整理,进一步储存在HBase或者关系型数据库中,可以进行可视化的查询。
>>调用跟踪系统的选型
大的互联网公司都有自己的分布式跟踪系统,
比如Google的Dapper,Twitter的zipkin,淘宝的鹰眼,新浪的Watchman,京东的Hydra等。
(1)Google的Drapper
Dapper是Google生产环境下的分布式跟踪系统,Dapper有三个设计目标:
低消耗:跟踪系统对在线服务的影响应该做到足够小。
应用级的透明:对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统显然是侵入性太强的。
延展性:Google至少在未来几年的服务和集群的规模,监控系统都应该能完全把控住。
Drapper的日志格式:
dapper用span来表示一个服务调用开始和结束的时间,也就是时间区间。
dapper记录了span的名称以及每个span的ID和父ID,如果一个span没有父ID被称之为root span。所有的span都挂在一个特定的trace上,共用一个traceID,这些ID用全局64位整数标示。

Drapper如何进行跟踪收集:

分为3个阶段:
①各个服务将span数据写到本机日志上;
②dapper守护进程进行拉取,将数据读到dapper收集器里;
③dapper收集器将结果写到bigtable中,一次跟踪被记录为一行。
(2)淘宝的鹰眼
关于淘宝的鹰眼系统,主要资料来自于内部分享,

鹰眼埋点和生成日志:

如何抓取和存储日志:
鹰眼的实现小结:

详情见:淘宝-分布式调用跟踪系统介绍
参考资料:
分布式追踪系统dapper