int8_t中的INT8_MIN表示成什么
这是一个计算机组成原理中的知识,但又不能按照学校教的方式去理解它。这个问题和原码补码有关,在此之前请先遗忘掉曾经学过的口诀
- 负数补码等于原码余位取反后加一
- 原码补码中第一位是符号位
好,下面看一幅图

在纯正的二进制世界中,1111 1111代表255,0000 0000代表0。那么问题来了,在计算机世界中,没有负号可以用来表示负数,因此一群聪明的人想出了一个办法,牺牲1bit来表示数据的正负,那么对于8bit的int8_t来说,它就只剩下7bit能用来表示它的数据了
在C++中,采用补码来记录数据,因此0111 1111代表127,那么1000 0000代表什么呢,它的首位代表了它是一位负数
为了求出这个值我们需要用到一个叫做模的概念,对于int8_t来说,它的模等于1 0000 0000也就是256,对于负数来说,计算公式如下
// 模 - abs(X) = 常规二进制表示
让我们带入看一下,模位256,1000 0000的常规二进制是128
// 256 - abs(X) = 128
// 解得abs(X) = 128
由于1000 0000的首位是1,代表是一个负数,因此X为-128。这也说明了为什么INT8_MAX + 1 = INT8_MIN
所以现在我们的数轴看起来是这样

在VS中观察内存结构也是一样的结果,C++使用补码储存数据
std::int8_t data = -128;
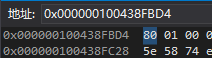
16进制中存放的是0x80,转化为二进制就是1000 0000,按照我们之前的说法那就是-128。以此类推,-127中存放的将会是1000 0001,126中存放的将会是0111 1110
最后来一道测验题检测你是否真的掌握了
int8_t data = -127;
std::cout << (int32_t)(*(uint8_t*)(&data)) << std::endl; // 129
因为int8_t其实被定义为char,所以为了输出十进制的数据还需要再转换成int
内存泄漏是什么,会引发什么后果
有的人可能会说,这段代码就是内存泄漏,在程序结束后并没有手动回收内存
int main()
{
int* data = new int(100);
}
其实这并不是标准的答案,因为在程序运行结束后,现代的操作系统会自动回收分配给此进程的内存。也就是说我们没有delete的内存会被操作系统收走,并不会出现“这4B内存已消失在浩瀚的海洋中”的情况。那么内存泄漏具体是指什么情况呢
int main()
{
for (int i = 0; i < 1000000; i++)
{
{
int* data = new int(100);
}
}
}
我在一个单独的作用域中给指针分配了4B的内存,而再它作用域结束后没有回收这块内存,如此循环1000000次。那么在程序运行的过程中,我们不断的去申请内存而不释放,那么可想而知,在整个程序运行期间我们将占用1000000 * 4B的内存空间。但如果我们
int* data = new int(100);
delete data;
那么无论循环多少次,我们都只会占用4B的内存
最后,程序运行结束,占用的1000000 * 4B空间被操作系统回收(操作系统帮我们擦屁股)。那么,如果程序是跑在服务器上的,7x24小时不间断的跑,操作系统根本就等不到程序结束时来做收尾工作。那么内存泄露的就会越来越多,到极端情况将会沾满所有内存,导致程序无法再运行下去
operator new和placement new的区别是什么
new operator:就是我们日常使用中的new,它会申请一块内存并调用构造函数来初始化
operator new:申请一块内存,它的功能和malloc类似
placement new:已经有一片内存,去调用到构造函数。是operator new的子集(后文细说)
那么我们可以把一次new操作可以看作是operator new + placement new,来看看我们调用一次new会发生什么事情
class TestClass
{
public:
int data;
TestClass() : data(0) { std::cout << "default create" << std::endl; }
TestClass(int _data) : data(_data) { std::cout << "param create" << std::endl; }
~TestClass() { std::cout << "destroy" << std::endl; }
};
控制台会输出一次param create和一次destroy
int main()
{
// TestClass* pClass = new TestClass(20);
void* p = operator new(sizeof(TestClass)); // malloc
TestClass* pClass = static_cast<TestClass*>(p);
pClass->TestClass::TestClass(20);
// delete pClass;
pClass->TestClass::~TestClass();
operator delete(pClass); // free
}
以上实例调用的是默认的operator new,是c++帮我们写好的,如果我们想客制化一个呢
class TestClass
{
public:
// Codes...
void* operator new(std::size_t size)
{
std::cout << "operator new" << std::endl;
// 底层是malloc
return ::operator new(size);
}
void operator delete(void* p)
{
std::cout << "operator delete" << std::endl;
// 底层是free
::operator delete(p);
}
};
int main()
{
// 输出operator new | param create | destroy | operator delete
TestClass* p1 = new TestClass(20);
delete p1;
// 只申请内存并不初始化
// 输出operator new
void* p2 = TestClass::operator new(sizeof(TestClass));
// 无输出 不会调用到类的析构函数并且调用到全局的operator delete
delete p2;
}
注意,delete一个自定义类型和delete默认类型(包括void)的指针的区别是,前者会调用到析构函数,再调用operator delete;后者则会直接调用operator delete,所以delete一个void*很有可能会导致析构不完全
重载一个operator new时需要注意以下几点
-
必须返回一个
void*类型的指针 -
第一个函数参数必须为
std::size_t类型,代表需要申请的内存的大小;后续的参数可以自定义void* operator new(std::size_t size, std::string str) { std::cout << "operator new with" << str << std::endl; // 底层是malloc return ::operator new(size); } TestClass* p = new("Jelly") TestClass(20);而且我们发现调用
new operator并不需要传入类型的大小,因为它是隐式传入sizeof(T)的
上文中我们提到了placement new是已有一个内存,然后去调用构造函数;还提到了operator new的后续参数可以自定义。那么我们对operator new实现一个传入void*指针的重载,这不就正好是placement new吗
// 依旧是这个测试类
class TestClass
{
public:
int data;
TestClass();
TestClass(int _data);
void* operator new(std::size_t size);
void operator delete(void* p);
~TestClass();
};
因为TestClass中重载了operator new和operator delete,并没有实现所谓的placement new,所以我们只能显式的调用全局的方法
// c++对placement new的实现可以看作是指针的转发 并不会去申请内存空间
inline void* operator new(std::size_t, void* p) { return p; }
int main()
{
// 调用全局的operator new在堆上分配内存
void* mem = operator new(sizeof(TestClass));
// 调用全局中的placement new
TestClass* p = ::new(mem) TestClass(20);
// 输出param create | destroy | operator delete
delete p;
}
那么这个时候肯定会有人突发奇想,既然我们可以指定对象构建的地址了,那我们也一定可以在使用placement new在栈上创建对象
struct MyStruct
{
char c;
MyStruct(char _c) : c(_c) {}
~MyStruct() { std::cout << "destroy" << std::endl; }
};
int main()
{
// 栈上变量data的内存中中储存的数据为2c 01 00 00 转换为十进制就是300
int data = 300;
MyStruct* p1 = new(&data) MyStruct('A');
// 此时经过初始化 data所在的内存上的数据已经被更改 p1的指向和&data是完全一致的
// 而因为MyStruct只占一个字节,也就是8bit,使用在内存中只需要两位就可以表示 所以为41 01 00 00
// 因为构建MyStruct的缘故 内存中的前两位被更改 后面的数据不变 所以输出321
std::cout << data << std::endl;
// 需要手动调用析构函数
p1->MyStruct::~MyStruct();
// 内存上的数据为41
MyStruct* p2 = new MyStruct('A');
delete p2;
}
十进制数300的十六进制表示为12C
十进制数321的十六进制表示为141
字符A的在ASCII码表中对应十进制数65,对应16进制数为41
int(0)在内存中的表示为00 00 00 00,为什么有8位?因为int占4个字节,也就是32bit,而在地址中数据以16进制的格式储存,存一个16进制的数需要4bit(0.5B),4bit * 8位刚好等于32bit
内存中的数据存储是反着来的,得从后往前读,比如内存中2c 01 00 00代表的是十六进制的00 00 01 2c
当我们试图在类中重载placement new时可以这么写
class TestClass
{
public:
// Codes...
void* operator new(std::size_t size, void* p, int _data)
{
// 对传入的指针执行一次构造
static_cast<TestClass*>(p)->::TestClass::TestClass(_data);
return p;
}
};
int main()
{
void* mem = operator new(sizeof(TestClass));
void* p = TestClass::operator new(sizeof(TestClass), mem, 43);
delete static_cast<TestClass*>(p);
}
如果我们使用new operator时仍然这么干,那么会出现多次构造函数的调用
int main()
{
void* mem = operator new(sizeof(TestClass));
// 默认构造产生的对象会覆盖掉placement new中有参构造的
TestClass* p = new(mem, 10) TestClass;
// 输出0
std::cout << p->data << std::endl;
delete p;
}
所以当我们重载placement new时,一定要注意其实现,根据实现判断和new operator搭配时会出现的状况
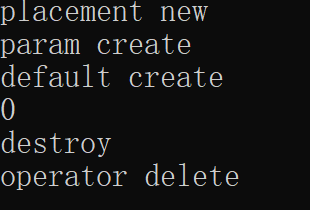
本问题正确答案是:placement new是operator new的子集,因为它是重载的一部分实现。operator new的代码本质上是申请内存空间,而placement new本质上是拿一个传递进来的指针来调用构造函数
以后有人问new的底层是什么时,不要再简单的回答是malloc了。new operator中的第一个操作是operator new,operator new的底层才是malloc
delete,delete[]
delete[]如何获取到要删除的元素个数
当delete一个指针时,只需要通过指针调用到对应的析构函数(底层是如何调用到的?),然后执行operator delete(底层是free)来释放内存
当delete[]一个指针时,对于具有非平凡析构函数的类型而言,需要逐个遍历数组中的元素,然后执行析构函数。最后调用到operator delete[](底层是free)。在new[]时期调用底层的malloc时,malloc除了n * sizeof(T)外,还会额外申请一小块空间(分布在我们申请的内存的头尾),用于记录内存大小等信息。当free回收时,它会根据这段信息正确的释放应该释放的内存。但当new[]或delete[],由于需要一个循环来调用元素的构造/析构函数,而此时作为new[]/delete[]它们和malloc/free显然是两个层级的事情,因此new[]也需要多申请一点空间来存放大小信息,以供delete[]逐个调用析构函数使用
new[]的时候会有一个overhead,维护了一个额外的信息(如元素个数n),具体实现由编译器自行决定。即malloc记录了一次大小,new也记录了一次大小
struct Data
{
int* p;
Data() : p(new int[20]{}) {}
~Data() { delete[] p; }
};
// 在64位系统上 编译器实际上会分配sizeof(Data) * 10 + 8大小的内存
Data* pData = new Data[10];
// 10
std::cout << *(std::size_t*)((char*)pData - sizeof(std::size_t*)) << std::endl;
delete[] pData;
所以new[]返回的指针和delete[]操作的不是同一个指针,delete[]时指针会往前移,获取到数组元素个数,然后逐个调用析构函数,最后operator delete[]传入偏移后的指针释放整块内存
对于POD,内置类型等具有平凡析构函数的类型来说,编译器并不需要为它们分配一块空间来记录个数,因为不需要调用到析构函数,直接回收内存即可,所以
int* pInt = new int[50];
// 对于内置类型而言不需要记录个数信息 此操作越界
std::cout << *(std::size_t*)((char*)pInt - sizeof(std::size_t*)) << std::endl;
delete[] pInt;
面试问题:通过new的POD直接free会怎样
首先new操作一般是需要搭配delete使用的,但是对于POD类型而言,它并没有析构函数,而简单的来讲delete是由调用析构函数和free组成的,所以通过new的POD直接free释放内存并不会引发异常
拓展:如果是通过new[]创建的POD数组,然后free指针释放会怎么样
struct POD
{
int data;
};
int main()
{
POD* p = new POD[1000000]{};
system("pause");
delete[] p;
system("pause");
}
正常的写法是这样,打开我们的Visual Studio便可以看到进程的内存占用状况,在delete[]之后内存占用下降了
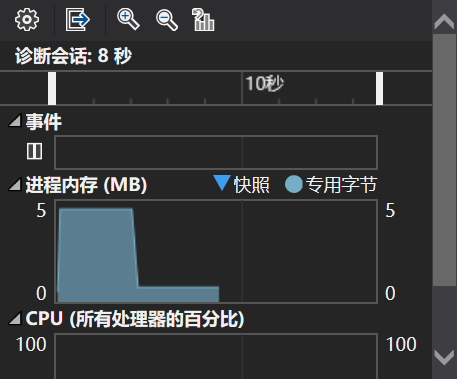
// 这样也是没问题的 new[] 底层的malloc会申请记录内存大小的一片空间
POD* p = new POD[1000000]{};
system("pause");
free(p);
system("pause");
但是如果是对非平凡析构函数的类/结构体来说
struct POD
{
int data;
// 这种写法也属于是平凡析构函数
// ~POD() = default;
// 非平凡析构函数
~POD() {}
};
int main()
{
POD* p = new POD[1000000]{};
system("pause");
// 虽然释放了申请的所有内存 但是并没有调用到析构函数
free((char*)p - sizeof(std::size_t));
system("pause");
}
new[]与delete搭配使用一定会导致内存问题吗
首先new和delete[]搭配是一定会出问题的,因为delete[]中指针会前移,所以会发生越界
然后回归正题,首先分两种测试案例,分别为普通的类以及POD
struct POD
{
int data[1000000];
};
int main()
{
// 大约申请了25MB的内存
POD* p = new POD[5];
// 大约释放了25MB的内存
delete p;
}
对于POD而言,并不需要调用到析构函数,同时new[]也没有申请额外的空间,所以没有出现错误。但是对于普通类而言
class NormalClass
{
int data;
public:
NormalClass() : data(10) {}
~NormalClass() { std::cout << "Destroy" << std::endl; }
};
int main()
{
NormalClass* pArr = new NormalClass[10000];
delete pArr;
}
控制台输出一次Destroy后程序崩溃。这段代码只析构了数组的第一位成员,那么为什么会崩溃呢
为了让程序不崩溃,我们可以写出这样的代码试图补救一下
NormalClass* pArr = new NormalClass[10000];
// 仍然只会调用首元素的析构函数 但是现在程序不会崩溃了!
delete (NormalClass*)((char*)pArr - sizeof(std::size_t*));
所以,请务必配套使用new和delete,new[]和delete[]
为什么C++不使用delete统一代替delete[]
假设新版本的C++中delete使用了delete[]的方法,将delete隐式转换为delete[1]处理
MyClass* p = new MyClass();
// 编译器转换为
MyClass* p = new MyClass[1];
这样做虽然统一了用法,但是违背了zero overhead的原则,那么对于non-POD类型而言,由于编译器采取了隐式转换成数组的形式,那么就需要在new时期就多分配一块内存来记录对象的个数(尽管它永远都是1)。那么也肯定会有人为了节省sizeof(std::size_t)个字节,采用malloc+ placement new的方式来创建对象(这种行为其实和现如今的new是完全一致的)
如何初始化堆上刚申请的内存
因为POD和内置类型并没有构造函数,所以可以使用初始化列表来进行归零操作,这里以内置类型举例
std::size_t size = 10;
// 不进行初始化 输出不确定的值
int* pArr = new int[size];
std::copy_n(pArr, size, std::ostream_iterator<int>(std::cout, " "));
// 使用统一初始化 全部初始化为0
int* pArr = new int[size]{};
// 使用C风格的初始化
int* pArr = new int[size];
// 全部初始化为-1
std::memset(pArr, 255, sizeof(int) * size);
// 使用STL算法库中的API进行初始化
int* pArr = new int[size];
// 全部初始化为10
std::fill_n(pArr, size, 10);
这里有人可能看不懂了,为什么C风格的初始化会得到结果-1。首先我们需要知道255的十六进制表示为FF,那么请看初始化前后的内存对比图


你可以把std::menset看作是填充内存(size * sizeof(int)) = 40次,每次填一个FF,即1字节,而内存中的FF FF FF FF将被int类型的数据解释为-1
如果填充的是256,那么代表内存中的数是00 00 00 00 ...,即数组中的每个元素都是0
如果i填充的是10,那么代表内存中的数是0a 0a 0a 0a 0a...,即数组中的每个元素都是168430090(注意内存中存放的顺序是逆向的,在一个
int单元内应该从右往左读)
C++中栈和堆上的数组最大容量是多少
引用SOF上的一个回答
[is-there-a-max-array-length-limit-in-c](
如何以不同的方式解析一段地址上的数据
对指针类型进行强转然后用不同的类型去解析该数据
// 内存中的数据为 4a 65 6c 6c 79
// J e l l y
const char* name = "Jelly";
// 指针指向首元素的地址
std::cout << *name << std::endl;
// 4a 65 6c 6c 79
const int* pInt = reinterpret_cast<const int*>(name);
// 6c 6c 65 4a => 1819043146
std::cout << *pInt << std::endl;
如何new一个对象,new一个对象的数组,new一个对象的指针数组
基础不牢 地动山摇
数组
问下列代码会输出什么
class TreeNode
{
public:
int data;
TreeNode() { cout << "无参构造" << endl; }
TreeNode(int _data) : data(_data) { cout << "有参构造" << endl; }
~TreeNode() { cout << "销毁" << endl; }
};
int main()
{
TreeNode nodes[5];
return 0;
}
公布答案
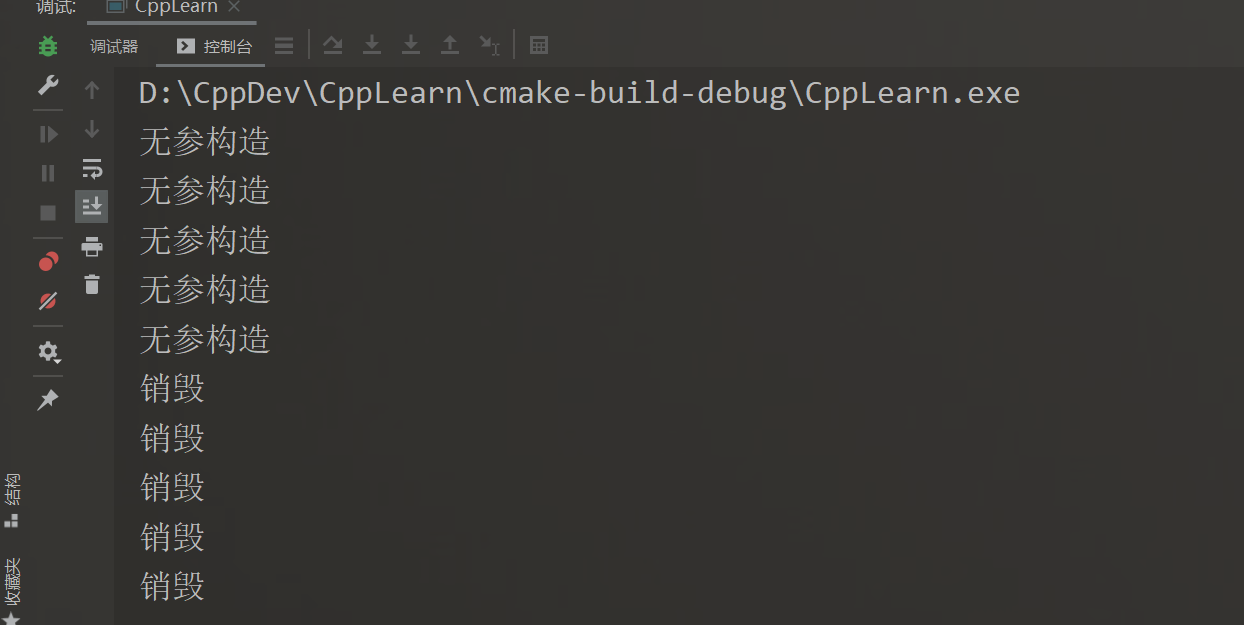
再来看这种
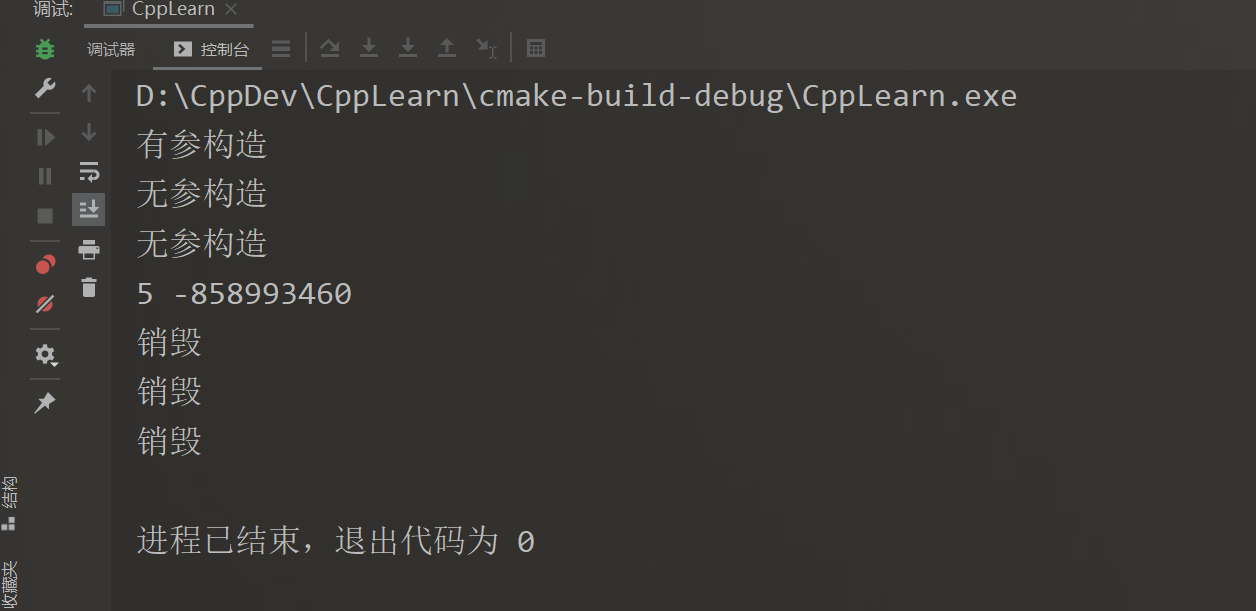
TreeNode nodes[3] { TreeNode(5) };
cout << nodes[0].data << ends;
cout << nodes[1].data << endl;
nodes数组的构造方式为:显式调用拷贝构造函数,然后隐式调用两次默认构造函数。也就是说如果默认构造函数是显式的(explicit),那么上述花括号构造不能通过编译
指针数组 - 记录指针的数组
再问,保持类不变,下列代码会输出什么
// 在栈上创建了一个指针数组 因为没有初始化 所以数组中的每个元素都是野指针
TreeNode* pNodes[20];
答案是没有输出,上述声明了一个指针数组。指针数组就是一个存了n个指针的数组
下方代码示范指针数组的初始化
// 将20个元素都初始化为空指针
TreeNode* pNodes[20] {};
// 访问空指针 非法 程序异常
cout << pNodes[0]->data << endl;
下方代码构建了指针数组的第一个元素,然后将剩下的19个元素置为nullptr
TreeNode element(10);
TreeNode* pNodes[20] { &element };
// 输出10
cout << pNodes[0]->data << endl;
下面演示一下在栈上的指针数组,且每一项指针都指向堆上的资源
// 两个函数等价 都被编译器解释为二级指针类型
void TestPassPP(TreeNode** t) {}
void TestPassPA(TreeNode* t[]) {}
TreeNode* pNodes[5];
for (auto& node : pNodes)
node = new TreeNode(10);
// 输出10
cout << pNodes[0]->data;
// 测试函数参数传递
TestPassPP(pNodes);
TestPassPA(pNodes);
// 释放资源
for (auto& node : pNodes)
delete node;
个人觉得这种写法虽然能通过编译,但是并无实际用途,甚至可以说是一种错误的写法,比如下方代码
TreeNode** Create1DPointerArrayOnStack()
{
TreeNode* pNodes[5];
for (auto& node : pNodes)
node = new TreeNode(10);
// 退化成二级指针 外界无法知道这个指针数组里头有多少个元素
return pNodes;
}
TreeNode** p = Create1DPointerArrayOnStack();
// 仍然能访问
cout << p[0]->data << ends;
// 栈指针偏移 数据丢失
cout << p[0]->data << endl;
// 此时已经无法找到对应的指针可以delete
虽然指针数组中的指针指向的是在堆上的资源,但是函数返回的是一个二级指针(数组指针),且该这个数组本身是在栈上的,自然而然地程序也会出错
现在再演示如何在堆上创建指针数组(数组本身在堆上),因为new操作返回的是指针,所以需要一个数组指针来承接
// 数组指针p2pNode 指向一个指针数组
TreeNode** p2pNodes = new TreeNode*[5];
for (int i = 0; i < 5; i++)
p2pNodes[i] = new TreeNode(10);
// 输出10
cout << p2pNodes[3]->data << endl;
// 销毁
for (int i = 0; i < 5; i++)
delete p2pNodes[i];
delete[] p2pNodes;
用法示例
TreeNode** Create1DPointerArrayOnHeap(int size, int value)
{
TreeNode** p2pNodes = new TreeNode*[size];
for (int i = 0; i < size; i++)
p2pNodes[i] = new TreeNode(value);
return p2pNodes;
}
TreeNode** p = Create1DPointerArrayOnHeap(5, 10);
// 输出10
cout << p[2]->data << endl;
// 手动销毁
for (int i = 0; i < 5; i++)
delete p[i];
delete[] p;
众所周知,一个二级指针可以表示一个1维的指针数组,也可以表示一个2维的普通数组,请看下方代码,注意,因为无参构造函数中没有初始化数据,所以输出的将会是不确定的int值
TreeNode** p2pNodes2D = new TreeNode*[5];
// 拓展到第二维度 含有10个元素
for (int i = 0; i < 5; i++)
p2pNodes2D[i] = new TreeNode[10];
// 访问第0行第0列的元素 利用指针访问 可通过++操作遍历列元素
cout << p2pNodes2D[0]->data << ends;
// 访问第0行第1列的元素
cout << p2pNodes2D[0][1].data << endl;
// 销毁
for (int i = 0; i < 5; i++)
delete[] p2pNodes2D[i];
delete[] p2pNodes2D;
下面介绍另外一种创建二维普通数组的方法,这种需要提前确定第2维度的大小(本例中是10)。测试输出的仍然是不确定的int值
// 已知第二维 类型为TreeNode (*)[10]TreeNode (*pNodes2D)[10] = new TreeNode[5][10];// 访问第1行第0列的元素cout << pNodes2D[1]->data << ends;// 访问第2行数组的第3列的元素cout << pNodes2D[2][3].data << endl;// 销毁delete[] pNodes2D;
pNodes2D的类型是TreeNode (*)[10],该类型不能退化为二级指针类型
// 都需要显式指定第二维度为10
void TestPassPA(TreeNode (*t)[10]) {}
void TestPassAA(TreeNode t[][10]) {}
using TreeNodeArrayPointer2D = TreeNode[10];
TreeNodeArrayPointer2D* CreateTest()
{
TreeNode (*pNodes2D)[10] = new TreeNode[5][10];
TestPassPA(pNodes2D);
TestPassAA(pNodes2D);
// 省略外部调用的delete[]操作
return pNodes2D;
}
结论
- 一维指针数组可以退化为二级指针
- 二维数组指针不能正常转换为二级指针
- 二级指针无法正常转换为以上两种类型
拓展:上文中p2pNodes2D中的每个元素都是TreeNode类型,且在构建的时候使用的是无参构造函数,若要使用有参构造,那么需要使用到列表初始化
p2pNodes2D[i] = new TreeNode[10] {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
这种写法是比较麻烦的,又或者说我想创建一个二维的数组指针应该怎么写呢?
// 5 * 6 的二维指针数组
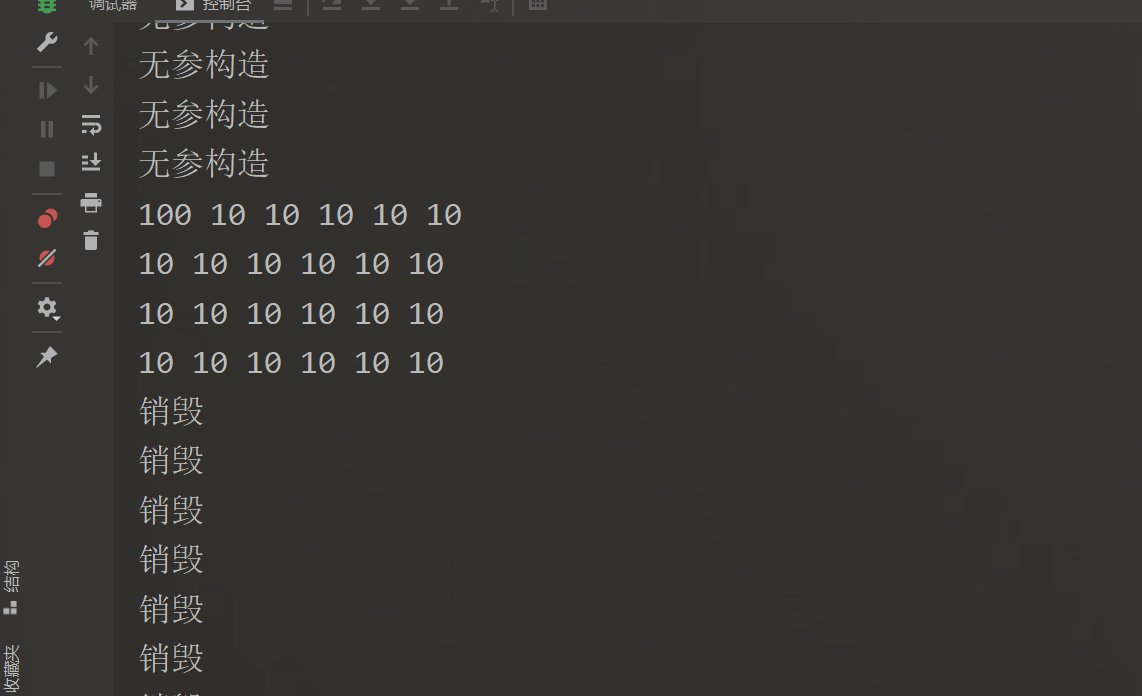
TreeNode*** p2pNodes2DParamInit = new TreeNode**[5];
for (int i = 0; i < 5; i++)
{
p2pNodes2DParamInit[i] = new TreeNode*[6];
for (int j = 0; j < 6; j++)
p2pNodes2DParamInit[i][j] = new TreeNode(j);
}
// 输出5
cout << p2pNodes2DParamInit[4][5]->data << endl;
// 销毁
for (int i = 0; i < 5; i++)
{
for (int j = 0; j < 6; j++)
delete p2pNodes2DParamInit[i][j];
delete[] p2pNodes2DParamInit[i];
}
delete[] p2pNodes2DParamInit;
数组指针 - 指向数组的指针
问:下列代码会输出什么
TreeNode* pNode = new TreeNode[20];
// delete[] pNode;
答案是会输出20次无参构造,没有输出销毁,因为delete[]被注释掉了
如果是这样呢
TreeNode* pNode = new TreeNode[20];
delete pNode;
会输出20次无参构造,一次销毁,然后程序报错。所以说明new[]和delete[]要搭配使用
那么这个数组中存的是什么类型呢
auto node = pNode[5];
存的是TreeNode类型,并且下列代码会输出一个不确定的值,因为没有初始化(C#中则会默认初始化为0,C++中不会)
cout << pNode[5].data << endl;
// 头元素调用有参构造函数 其他元素隐式调用无参构造函数
TreeNode* pNode = new TreeNode[20] {10};
// 输出数组的头元素 输出10
cout << pNode->data;
delete[] pNode;
上文中创建了在堆上的数组,下文演示在栈上的数组指针
// 创建一个数组以供赋值
TreeNode arr[20];
TreeNode* pArr = arr;
pArr[0].data = 100;
// 两者都是输出100
cout << pArr->data << endl;
cout << pArr[0].data << endl;
// 输出不确定的值 因为在++操作后指针指向的是第1个元素 它的data没有被初始化
cout << (++pArr)->data << endl;
再来看看在栈上的指向二维数组的指针
TreeNode arr2D[10][20];
TreeNode (*p)[20] = arr2D;
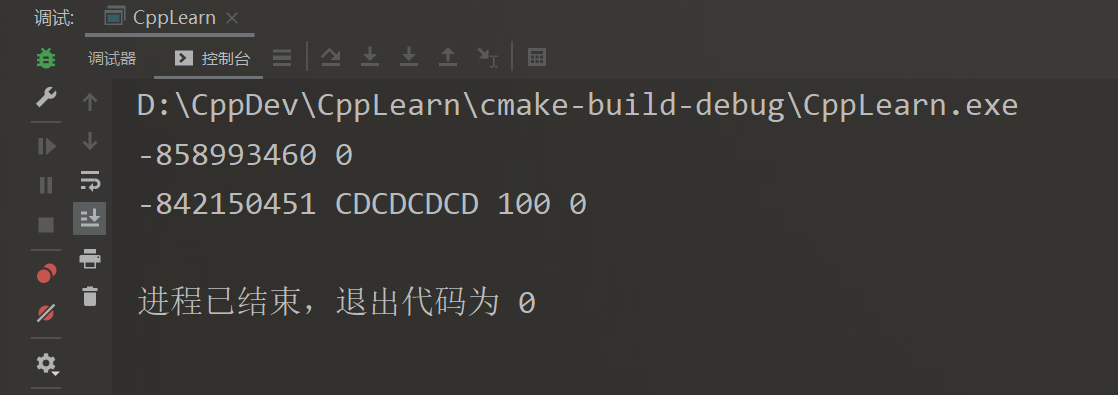
来看看内置类型的初始化
int intArr[20];
cout << intArr[5] << ends;
int intArrInit[20] {};
cout << intArrInit[5] << endl;
int* p2IntArr = new int[20];
cout << p2IntArr[5] << ends;
int** p2pIntArr = new int*[20];
cout << p2IntArr[5] << ends;
int* pIntArrInit = new int[20] {10, 100};
cout << pIntArrInit[1] << ends;
cout << pIntArrInit[5] << endl;
小测验
TreeNode* pArr[5]; // 一个数组 存的是指针
TreeNode* pArrInitNull[5] {}; // 一个数组 存的是指针 且指针都初始化为nullptr
TreeNode (*p2Arr)[5]; // 一个指针 指向一个第二维度大小为5的存放TreeNode的二维数组
TreeNode* (*p2pArr)[10]; // 一个指针 指向一个第二维度大小为10的存放TreeNode*的二维数组
TreeNode* nodesOnHeap = new TreeNode[20]; // 指向一个堆上的数组的数组指针
TreeNode** pNodesOnHeap = new TreeNode*[20]; // 指向一个堆上的指针数组的数组指针
TreeNode nodes2DArray[10][20]; // 二维数组
TreeNode* pArr1D = nodes2DArray[0]; // 指向一维数组的指针
TreeNode (*pArr2DLimit)[20] = nodes2DArray; // 指向二维数组且第二个维度为20的指针
TreeNode** pArr2DUnLimit = nodes2DArray; // 编译不通过 李在赣神魔?
TreeNode* pNodes2DArray[10][20]; // 二维指针数组
TreeNode** pArr1D = pNodes2DArray[0]; // 数组指针 指向的是存放指针的一维数组
TreeNode* (*pArr2DLimit)[20] = pNodes2DArray; // TreeNode* (*)[20] 类型的指针
using PointerTreeNode20 = TreeNode*[20];
PointerTreeNode20* simpleWay = pNodes2DArray; // C++11
题外话
参数传递数组
void GetArraySize(int (&arr)[10]) { cout << sizeof(arr) << endl; }
int a[10];
// 输出40
putValues(a);
使用vector构建二维数组
class TestClass
{
public:
int data = 10;
TestClass() { cout << "无参构造" << endl; }
TestClass(const TestClass& copy) { cout << "拷贝构造函数" << endl; }
~TestClass() { cout << "销毁" << endl; }
};
// 会额外产生1 + 3个临时对象
vector<vector<TestClass>> vec(2, vector<TestClass>(3, TestClass()));
// 调用了1次无参构造和3 + 2 * 3次拷贝构造
// 调用了10次销毁
使用vector和share_ptr构建二维指针数组
vector<vector<shared_ptr<TestClass>>> array2D(4, vector<shared_ptr<TestClass>>(6, make_shared<TestClass>()));
cout << array2D[0][0]->data << endl;
array2D[0][0]->data = 100;
cout << array2D[0][0]->data << endl;
cout << array2D[0][1]->data << endl;

所以以上的构建方式是错误的,整个数组中存放的都是指向同一份资源的指针,正确的创建方式是
// 24次构造和24次销毁
vector<vector<shared_ptr<TestClass>>> vec2D(4, vector<shared_ptr<TestClass>>(6));
for (auto& vec1D : vec2D)
for (auto& ptr : vec1D)
ptr = make_shared<TestClass>();
vec2D[0][0]->data = 100;
for (const auto& vec1D : vec2D)
{
for (const auto& ptr : vec1D)
cout << ptr->data << ends;
cout << endl;
}
引用的底层实现是什么,引用的大小是什么
引用的底层是指针常量,且必须被初始化。所以引用的大小和指针的大小一致,在32位系统下是4,在64位系统下是8
如何通过指针修改const变量中的值
要通过volatile告知编译器不要对变量进行优化(常量折叠),使每次访问都会从内存中取值
const volatile int a = 5;
int* p = (int*)&a;
*p = 100;
std::cout << a << std::endl;
c++里的常量折叠(或者常量替换)是将
const常量放在符号表中,给其分配内存,但实际读取时类似宏替换。编译器直接进行替换优化。
成员指针和成员函数指针(待更新)
成员指针
struct A
{
char data1;
int64_t data2;
int32_t data3;
};
成员指针是一个很特殊的存在,它既不是值也不是指针,它记录的数据是该数据在类内的offset。常见的用法是通过结合实例对象访问类成员
int main()
{
char A::* p1 = &A::data1;
int64_t A::* p2 = &A::data2;
int A::* p3 = &A::data3;
A a;
// 通过成员指针访问类成员
a.*p2 = 100;
std::cout << a.data2 << std::endl; // 100
}
说到记录offset,在32位和64位的调试环境下,它占用的大小都是4B。因此在本例简单的环境中,我们可以用uint32_t,long,或者int来解析它(具体应该使用哪种方式我也不清楚)
// 可以用此强转来验证类的内存对齐 32位环境下
std::cout << *(std::uint32_t*)(&p1) << std::endl; // 0
std::cout << *(std::uint32_t*)(&p2) << std::endl; // 8
std::cout << *(std::uint32_t*)(&p3) << std::endl; // 16
来看一下复杂一点的情况,其实也很简单,关键就是字节对齐
// 32位环境下测试
struct A
{
char data1;
int64_t data2;
int32_t data3;
};
// 带有虚函数的派生类
struct VirA : public A
{
double data4;
bool data5;
virtual void func() {}
};
int main()
{
char A::* p1 = &A::data1;
int64_t A::* p2 = &A::data2;
int A::* p3 = &A::data3;
double VirA::* p4 = &VirA::data4;
bool VirA::* p5 = &VirA::data5;
std::cout << *(std::uint32_t*)(&p1) << std::endl; // 0
std::cout << *(std::uint32_t*)(&p2) << std::endl; // 8
std::cout << *(std::uint32_t*)(&p3) << std::endl; // 16
std::cout << *(std::uint32_t*)(&p4) << std::endl; // 32
std::cout << *(std::uint32_t*)(&p5) << std::endl; // 40
}
int main()
{
// 在派生类中的偏移 虚表指针位于首位
char VirA::* p1 = &VirA::data1;
int64_t VirA::* p2 = &VirA::data2;
int VirA::* p3 = &VirA::data3;
double VirA::* p4 = &VirA::data4;
bool VirA::* p5 = &VirA::data5;
std::cout << *(std::uint32_t*)(&p1) << std::endl; // 8
std::cout << *(std::uint32_t*)(&p2) << std::endl; // 16
std::cout << *(std::uint32_t*)(&p3) << std::endl; // 24
std::cout << *(std::uint32_t*)(&p4) << std::endl; // 32
std::cout << *(std::uint32_t*)(&p5) << std::endl; // 40
}
成员函数指针
这是一个耳熟能详的词
struct A
{
void func1(int, std::string) {}
double func2(bool) { return 1.0; }
};
int main()
{
void (A::* p1)(int, std::string) = &A::func1;
double(A::* p2)(bool) = &A::func2;
A a;
// 通过成员函数指针调用成员函数
(a.*p1)(10, "123");
}
成员函数指针的大小往往普通函数指针更大,因为它维护了更多的信息(待更新)
一句话系列
通过指针访问数组元素
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8};
// 1
std::cout << *arr;
// 2
std::cout << *(arr + 1);
// 2
std::cout << *(int*)((char*)arr + 4);