自定义输出数据的格式、输出路径、输出文件名
输出格式OutputFormat
1、OutputFormat 抽象类
2、FileOutputFormat 文件输出格式
3、TextOutputFormat 文本格式的文件输出格式
4、SequenceFileOutputFormat 普通序列文件输出格式
5、SequenceFileAsBinaryOutputFormat 二进制序列文件输出格式
6、FilterOutputFormat 过滤器输出格式
7、DBOutputFormat 数据库输出格式
8、MultipleOutputs 多种输出格式
自定义
1、定义一个类继承FileOutputFormat类重写getRecordWriter()方法
2、定义一个类继承RecordWriter类write和close
代码
下面我们以wordcount为例:
数据准备
1.txt
hadoop mapreduce
hive hadoop
oracle
java hadoop hbase
2.txt
spark
hadoop
spark hive mangoDB nginx
tomcat jboss apache
weblogic oracle
java C C++
自定义输出格式代码
import java.io.IOException;
import java.io.PrintWriter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CustomFileOutPutFormat extends FileOutputFormat<Text, IntWritable> {
@Override
public RecordWriter<Text, IntWritable> getRecordWriter(
TaskAttemptContext job) throws IOException, InterruptedException {
// TODO Auto-generated method stub
// 得到文件输出的目录
Path fileDir = FileOutputFormat.getOutputPath(job);
// 指定输出的文件名,这里我们为文件取名为1.txt
//如果有父级目录另作处理
Path fileName = new Path(fileDir.toString()+"/1.txt");
System.out.println(fileName.getName());
Configuration conf = job.getConfiguration();
FSDataOutputStream file = fileName.getFileSystem(conf).create(fileName);
return new CustomRecordWrite(file);
}
}
class CustomRecordWrite extends RecordWriter<Text, IntWritable> {
private PrintWriter write = null;
public CustomRecordWrite(FSDataOutputStream file) {
this.write = new PrintWriter(file);
}
@Override
public void write(Text key, IntWritable value) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
write.println("Word: " + key.toString() + "\t" + "Counts: " + value);
}
@Override
public void close(TaskAttemptContext context) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
write.close();
}
}
wordcount代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool {
@Override
public int run(String[] arg0) throws Exception {
// TODO Auto-generated method stub
Configuration conf = getConf();
Job job = new Job(conf, "worldcount");
job.setJarByClass(WordCount.class);
FileInputFormat.addInputPath(job, new Path("/value/*.txt"));
FileOutputFormat.setOutputPath(job, new Path("/wordcount/out"));
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
// 默认为TextOutputFormat,
//这里我们设置自定义的输出格式
job.setOutputFormatClass(CustomFileOutPutFormat.class);
job.submit();
return job.isSuccessful() ? 0 : 1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new WordCount(), null);
}
}
class WordCountMap extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value,
Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
System.out.println(word.toString());
context.write(word, one);
}
}
}
class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
运行结果
文件名
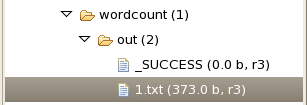
文件数据
Word: C Counts: 1
Word: C++ Counts: 1
Word: apache Counts: 1
Word: hadoop Counts: 4
Word: hbase Counts: 1
Word: hive Counts: 2
Word: java Counts: 2
Word: jboss Counts: 1
Word: mangoDB Counts: 1
Word: mapreduce Counts: 1
Word: nginx Counts: 1
Word: oracle Counts: 2
Word: spark Counts: 2
Word: tomcat Counts: 1
Word: weblogic Counts: 1