背景:上一个版本的数据集制作方法尽管有效,但是数据集并不干净,例如出现很多广告等等,所以使用必应浏览器制作数据。注意,尽管必应浏览器不用FQ,但是是需要注册一些信息,不过不麻烦!
方法:首先还是先PO出作者的原文:https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/
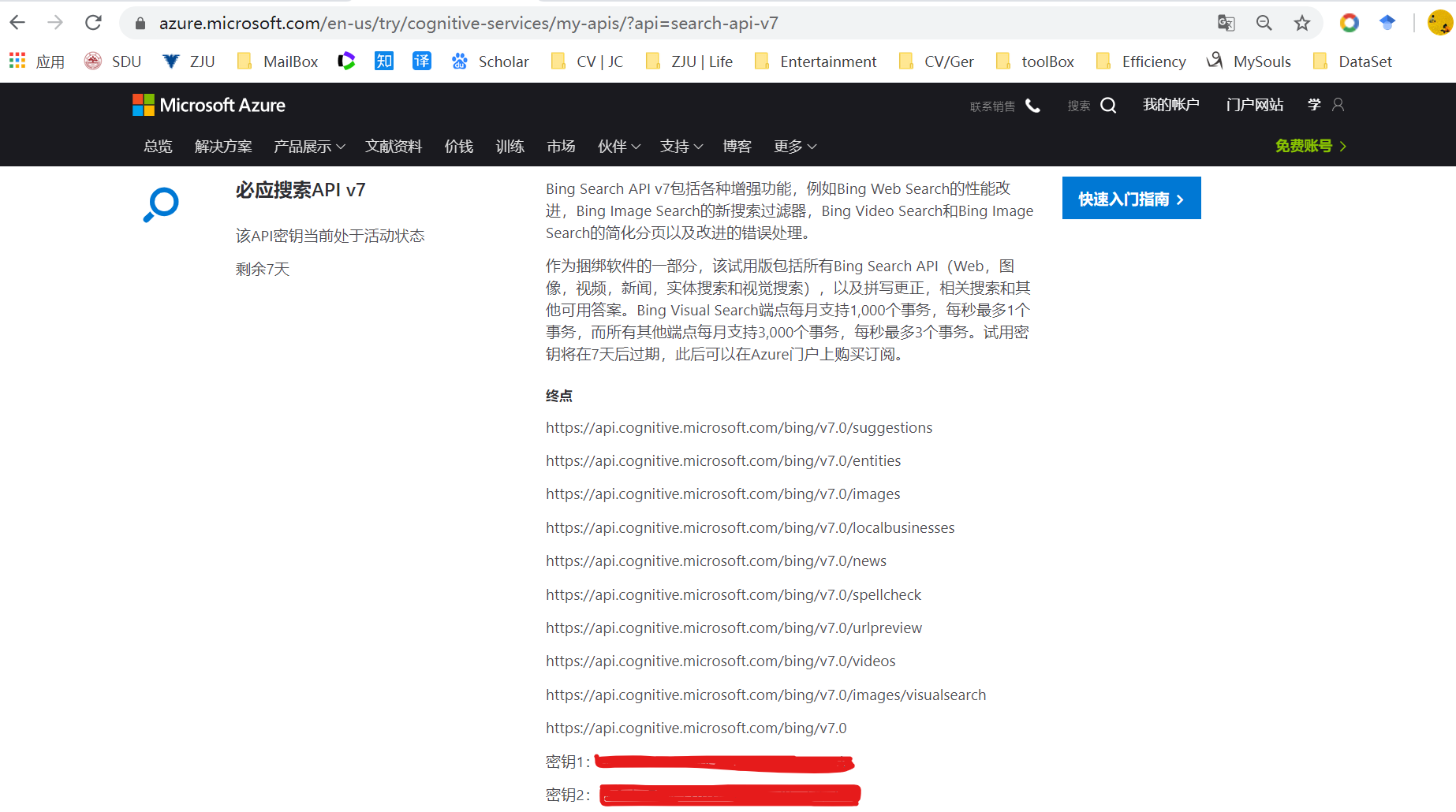
- 到微软的Bing Image Search API中注册账号,它是7天免费的:https://azure.microsoft.com/en-us/services/cognitive-services/bing-image-search-api/

- 成功以后,你可以看到如下页面,并记住你的密钥1和密钥2
- 建议阅读下面两个文档,尤其是第一个文档的.json文件格式,和第二个文档的count和offset的意义,它能帮助你在后面的代码阅读中更快地理解代码的意义。
- 下面,在你的虚拟环境中,安装requests包
-
$ pip install requests
- 新建一个“search_bing_api.py”文件,并将下面的代码复制到你这个文件中
-
# import the necessary packages from requests import exceptions import argparse import requests import cv2 import os # construct the argument parser and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-q", "--query", required=True, help="search query to search Bing Image API for") # 这个字段表示你想搜索什么 ap.add_argument("-o", "--output", required=True, help="path to output directory of images") args = vars(ap.parse_args()) args['output'] = os.path.join(args['output'], args['query']) if not os.path.exists(args['output']): os.makedirs(args['output']) # set your Microsoft Cognitive Services API key along with (1) the # maximum number of results for a given search and (2) the group size # for results (maximum of 50 per request) API_KEY = "YOUR_API_KEY_GOES_HERE" # 将刚刚的密钥1 或 密钥2 复制到这里 MAX_RESULTS = 250 GROUP_SIZE = 50 # 最大是150,它的意义可以查看上面的文档链接2 # set the endpoint API URL URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search" # when attempting to download images from the web both the Python # programming language and the requests library have a number of # exceptions that can be thrown so let's build a list of them now # so we can filter on them EXCEPTIONS = set([IOError, FileNotFoundError, exceptions.RequestException, exceptions.HTTPError, exceptions.ConnectionError, exceptions.Timeout]) # store the search term in a convenience variable then set the # headers and search parameters term = args["query"] headers = {"Ocp-Apim-Subscription-Key" : API_KEY} params = {"q": term, "offset": 0, "count": GROUP_SIZE} # make the search print("[INFO] searching Bing API for '{}'".format(term)) search = requests.get(URL, headers=headers, params=params) search.raise_for_status() # grab the results from the search, including the total number of # estimated results returned by the Bing API results = search.json() estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS) print("[INFO] {} total results for '{}'".format(estNumResults, term)) # initialize the total number of images downloaded thus far total = 0 # loop over the estimated number of results in `GROUP_SIZE` groups for offset in range(0, estNumResults, GROUP_SIZE): # update the search parameters using the current offset, then # make the request to fetch the results print("[INFO] making request for group {}-{} of {}...".format( offset, offset + GROUP_SIZE, estNumResults)) params["offset"] = offset search = requests.get(URL, headers=headers, params=params) search.raise_for_status() results = search.json() print("[INFO] saving images for group {}-{} of {}...".format( offset, offset + GROUP_SIZE, estNumResults)) # loop over the results for v in results["value"]: # try to download the image try: # make a request to download the image print("[INFO] fetching: {}".format(v["contentUrl"])) r = requests.get(v["contentUrl"], timeout=30) # build the path to the output image ext = v["contentUrl"][v["contentUrl"].rfind("."):] p = os.path.sep.join([args["output"], "{}{}".format( str(total).zfill(8), ext)]) # write the image to disk f = open(p, "wb") f.write(r.content) f.close() # catch any errors that would not unable us to download the # image except Exception as e: # check to see if our exception is in our list of # exceptions to check for if type(e) in EXCEPTIONS: print("[INFO] skipping: {}".format(v["contentUrl"])) continue # try to load the image from disk image = cv2.imread(p) # if the image is `None` then we could not properly load the # image from disk (so it should be ignored) if image is None: print("[INFO] deleting: {}".format(p)) os.remove(p) continue # update the counter total += 1
$ mkdir dataset
$ mkdir dataset/charmander $ python search_bing_api.py --query "charmander" --output dataset/charmander # 传入希望搜索的字段,以及输出目录 [INFO] searching Bing API for 'charmander' [INFO] 250 total results for 'charmander' [INFO] making request for group 0-50 of 250... [INFO] saving images for group 0-50 of 250... [INFO] fetching: https://fc06.deviantart.net/fs70/i/2012/355/8/2/0004_c___charmander_by_gaghiel1987-d5oqbts.png [INFO] fetching: https://th03.deviantart.net/fs71/PRE/f/2010/067/5/d/Charmander_by_Woodsman819.jpg [INFO] fetching: https://fc05.deviantart.net/fs70/f/2011/120/8/6/pokemon___charmander_by_lilnutta10-d2vr4ov.jpg ... [INFO] making request for group 50-100 of 250... [INFO] saving images for group 50-100 of 250... ... [INFO] fetching: https://38.media.tumblr.com/f0fdd67a86bc3eee31a5fd16a44c07af/tumblr_nbhf2vTtSH1qc9mvbo1_500.gif [INFO] deleting: dataset/charmander/00000174.gif ...
-