一、Spark简介
Spark是一个快速且通用的集群计算平台。
二、特点:
1、Spark 快速
扩充了Mapreduce计算模型
Spark是基于内存的计算
2、Spark 通用
Spark的设计容纳了其他分布式系统的拥有的功能。
批处理、迭代式计算、交互查询和流处理等。
3、Spark 高度开放
Python、Java、Scala、SQL的API和丰富的内置库
Spark和其他的大数据工具整合的很好,包括Hadoop和Kafka
三、Spark的组件
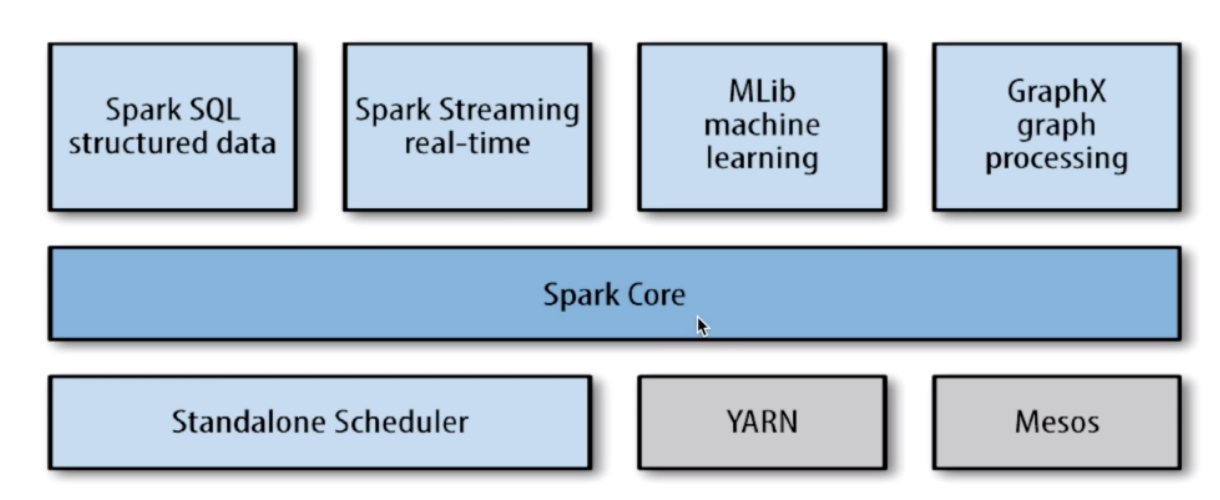
1、Spark Core
包含Spark的基本功能,包含任务调度、内存管理、容错机制等
内部定义了RDDs(弹性分布式数据集)
提供了很多API来创建和操作这些RDDs
应用场景,为为其他组件提供底层的服务
2、Spark SQL
是Spark处理结构化数据的库,就像Hive SQL、Mysql一样。
应用场景,在企业中用来做报表统计
3、Spark Sreaming
是实时数据流处理组件,类似Storm
Spark Streaming提供了API来操作实时数据流
应用场景,企业中用来从Kafka接收数据做实时统计
4、Mlib
一个包含机器学习功能的包,Machine learning lib
包含分类、聚类、回归等,还包括模型评估和数据导入
Mlib提供的上面的方法,都支持集群上的横向扩展
应用场景,机器学习
5、GraphX
是处理图的库(例如,社交网络图),并进行图的并行计算
像Spark Streaming、Spark SQL一样,它继承了RDD API
它提供了各种图的操作,和常用的图算法,例如PangeRank算法
应用场景,图计算
6、Cluster Managers
集群管理,Spark自带一个集群管理是单独调度器
常见的集群管理:Hadoop YARN,Apache Mesos
紧密集成的优点:
1、Spark底层优化,基于Spark底层的组件,也得到了相应的优化
2、紧密集成,节省了各个组件组合使用时的部署、测试等时间
3、向Spark新增组件时,可立即享用新组件的功能
四、Spark和Hadoop的比较
1、Hadoop
离线处理
对时效性要求不高
Hadoop中间数据存储在硬盘上
2、Spark
时效性较高的场景
Spark中间数据存储在内存中
五、Spark的安装
1、下载地址: http://spark.apache.org/downloads.html
2、Spark目录:
bin:包含用来和Spark进行交互的可执行文件,如Spark Shell
core、streaming、python...,包含主要组件的源代码
examples包含一些单机Spark job,可以研究和运行这些例子
3、Shell
Spark的Shell是你能够处理分布在集群上的数据
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成
快速使迭代式计算,实施查询、分析一般能够在shells中完成
Spark提供了Python shell和Scala shell
./bin/spark-shell
六、Spark开发环境搭建
1、Scala的安装
地址: https://www.scala-lang.org/download/
2、IntelliJ IDEA CE
地址:https://www.jetbrains.com/idea/
安装plugin: Spark 和 Scala
七、第一个Spark项目
1、配置Spark的无密登陆:
终端命令 ssh-keygen 生成密钥,这个密钥的生成和github配置ssh生成的密钥一样的,如果github生成过的话,直接用github那个id_rsa.pub就可以。
步骤是: 1、ssh-keygen
2、cd ~/.ssh/
3、touch authorized_keys
4、cat id_rsa.pub > authorized_keys
5、chown 600 authorized_keys
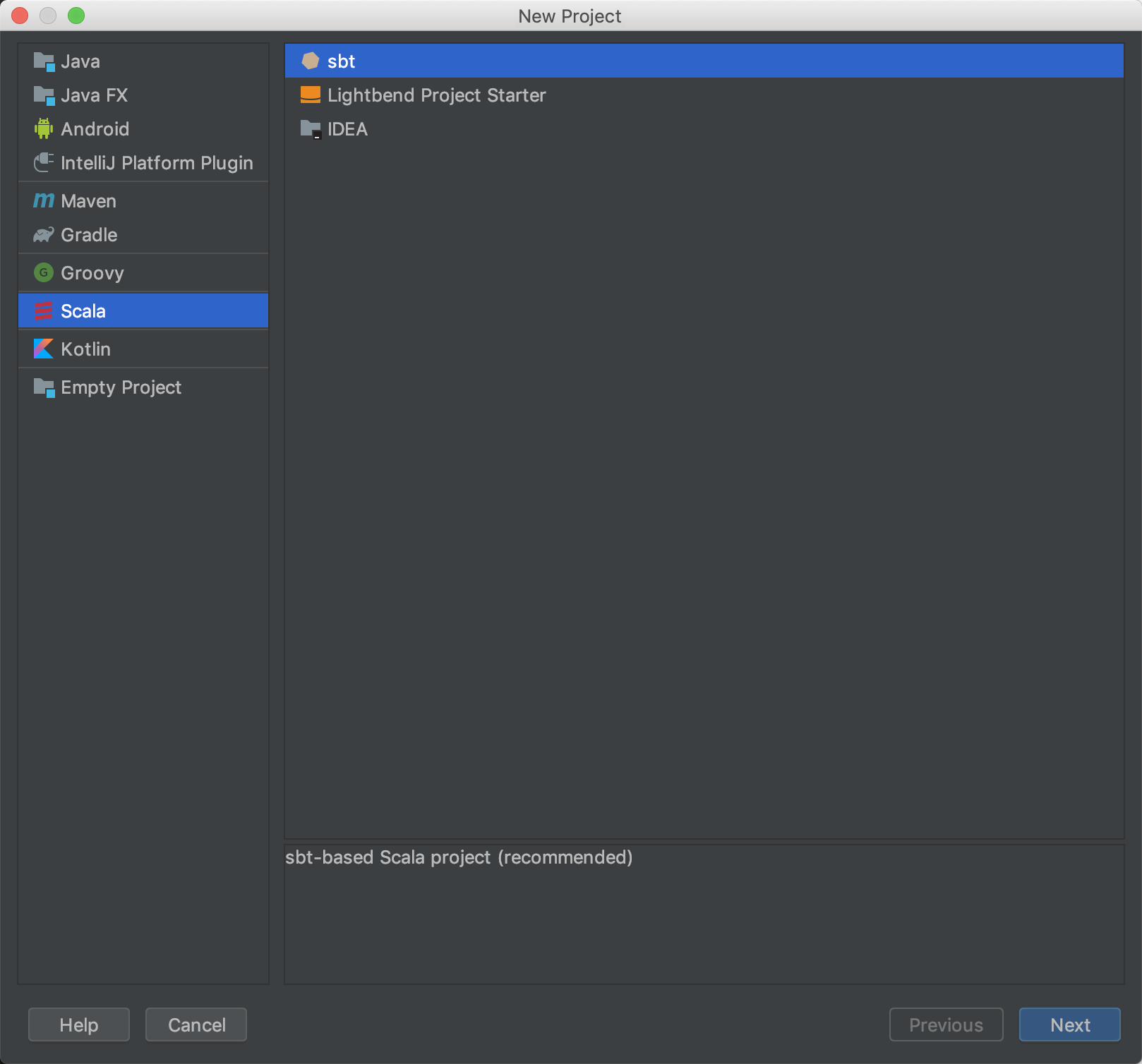
2、创建项目
Spark 和 Scala安装完成之后
New -> Project -> Scala -> sbt -> Next -> Finish
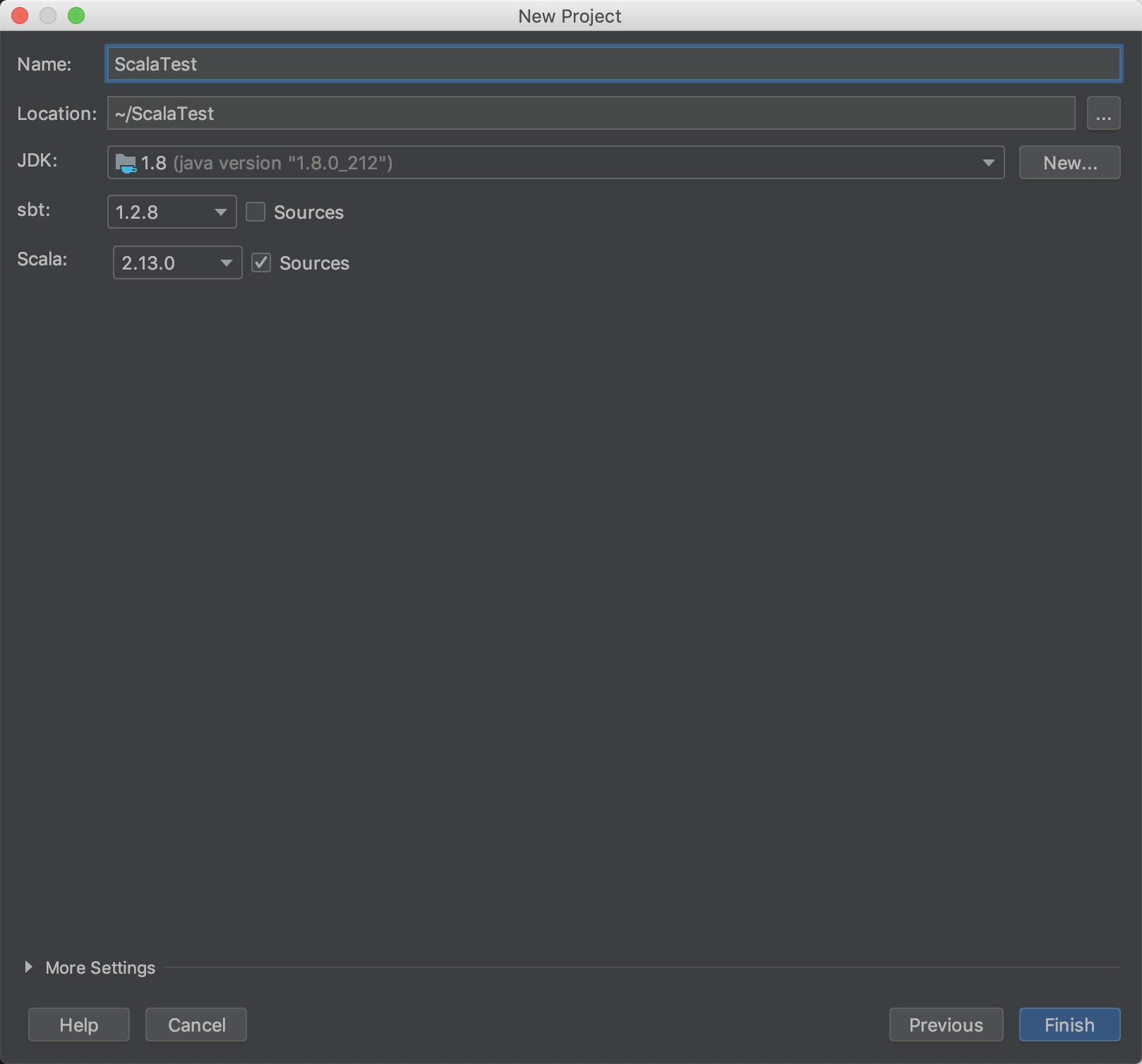

build.sbt 中配置项目依赖 ,注意 Scala和Spark的版本一定要对应上 不然会出版本问题
这是我用的配置:
name := "Scala-Test" version := "0.1" scalaVersion := "2.12.8" libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "2.4.3")