第1章 采集数据
1.1 框架流程
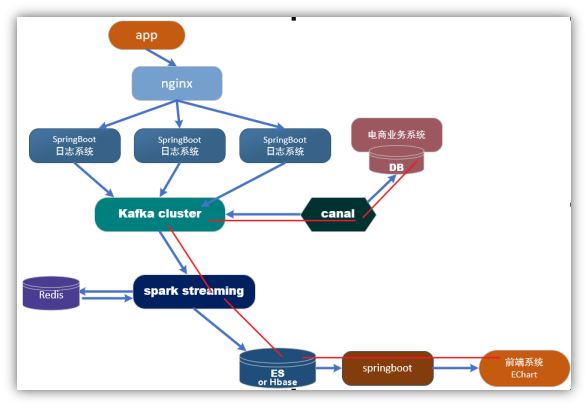
1.2 Canal 入门
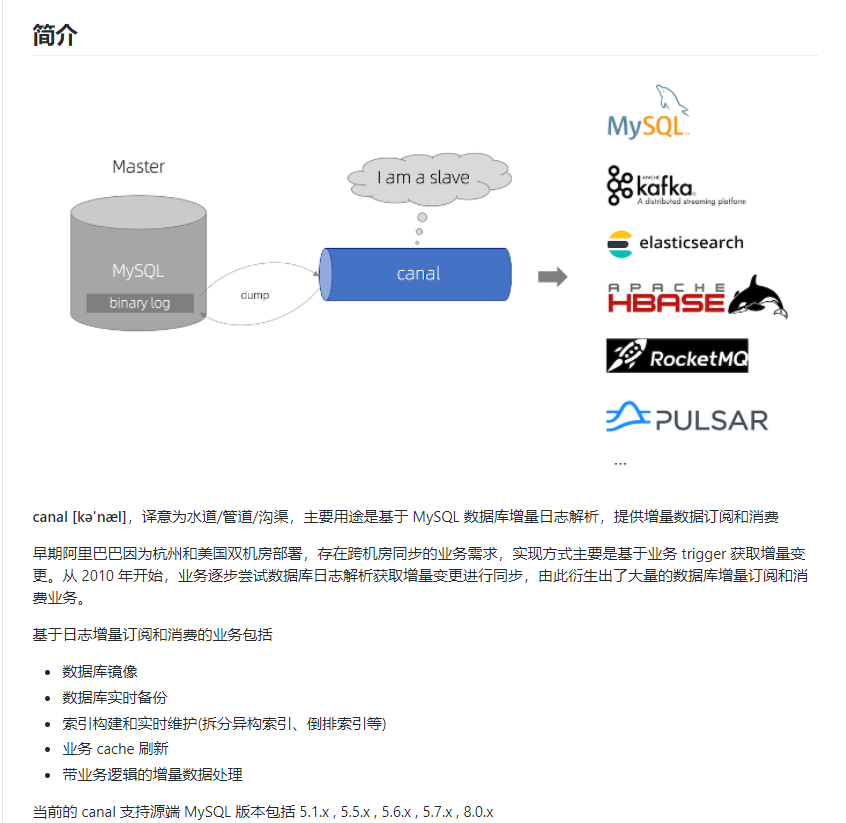
1.2.1 什么是 Canal
由于Canal没有官网,所以可以认为它托管在github上的项目就是官网,所以地址是:https://github.com/alibaba/canal
1.2.2 使用场景
1)原始场景: 阿里Otter中间件的一部分,Otter是阿里用于进行异地数据库之间的同步框架,Canal是其中一部分。
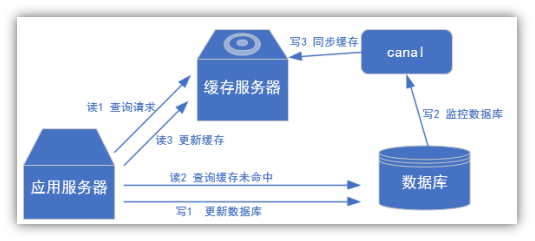
2) 常见场景1:更新缓存
3)场景2:抓取业务数据新增变化表,用于制作拉链表。
4)场景3:抓取业务表的新增变化数据,用于制作实时统计。
1.2.3 Canal的工作原理
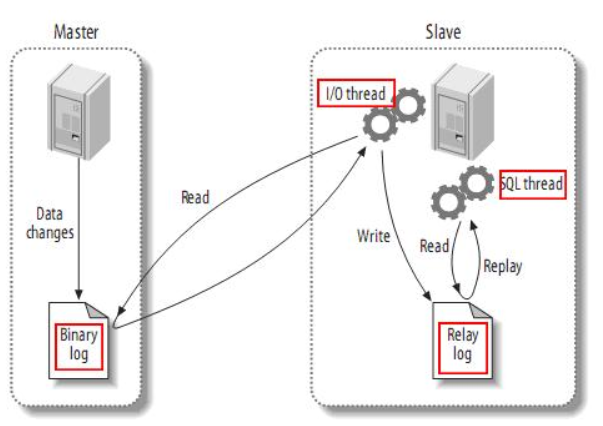
复制过程分成三步:
1)Master主库将改变记录写到二进制日志(binary log)中;
2)Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
3)Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
Canal的工作原理很简单,就是把自己伪装成Slave,假装从Master复制数据:
1)canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2)MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
3)canal 解析 binary log 对象(原始为 byte 流)
1.2.4 MySQL的Binlog
1.2.4.1 什么是Binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
1)MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
2)自然就是数据恢复了,通过使用MySQLBinlog工具来使恢复数据。
二进制日志包括两类文件:
1)二进制日志索引文件(文件名后缀为.index):用于记录所有的二进制文件
2)二进制日志文件(文件名后缀为.00000*):记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
1.2.4.2 Binlog的开启
在MySQL的配置文件(Linux: /etc/my.cnf , Windows: my.ini)下,修改配置在[mysqld] 区块设置/添加
#Binlog日志的开启
log_bin=mysql-bin
这个表示binlog日志的前缀是mysql-bin,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成。每次mysql重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号
1.2.4.3 Binlog的分类设置
MySQL Binlog的格式,那就是有三种,分别是statement、mixed、row
在配置文件中选择配置binlog_format属性
#选择Binlog的格式 binlog_format=row #保证server-id是唯一的 server-id=1
区别:
1)statement
语句级,binlog会记录每次一执行写操作的语句,相对row模式节省空间,但是可能产生不一致性,比如:update tt set create_date=now(),如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点:节省空间
缺点:有可能造成数据不一致。
2)row
行级,binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
3)mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题,在某些情况下譬如:当函数中包含 UUID() 时,包含 AUTO_INCREMENT 字段的表被更新时,执行 INSERT DELAYED 语句时,用 UDF 时,会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,
另外statement和mixed对于需要对binlog的监控的情况都不方便
1.3 MySQL的准备
1.3.1 导入模拟业务数据库
1.3.2 赋权限
1)进入mysql客户端
mysql -uroot -proot123
2)更改mysql密码策略
set global validate_password_length=4;
set global validate_password_policy=0;
3)在mysql中执行如下语句,创建canal用户,密码为canal:
grant select, replication slave, replication client on *.* to 'canal'@'%' identified by 'canal';

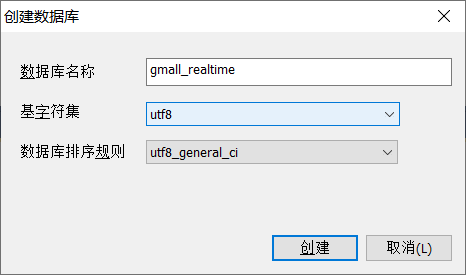
4)创建gmall_realtime数据库
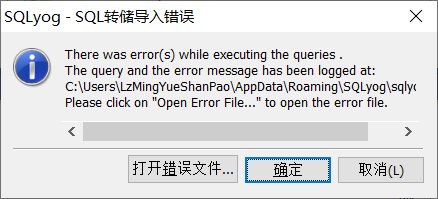
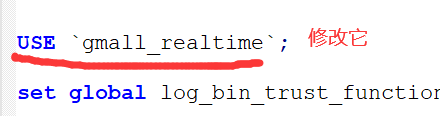
5)运行gmall.sql文件(下载链接是下方的网盘地址,请自行下载),执行过程中若出现如下错误,则打开该sql文件,修改库名为gmall_realtime
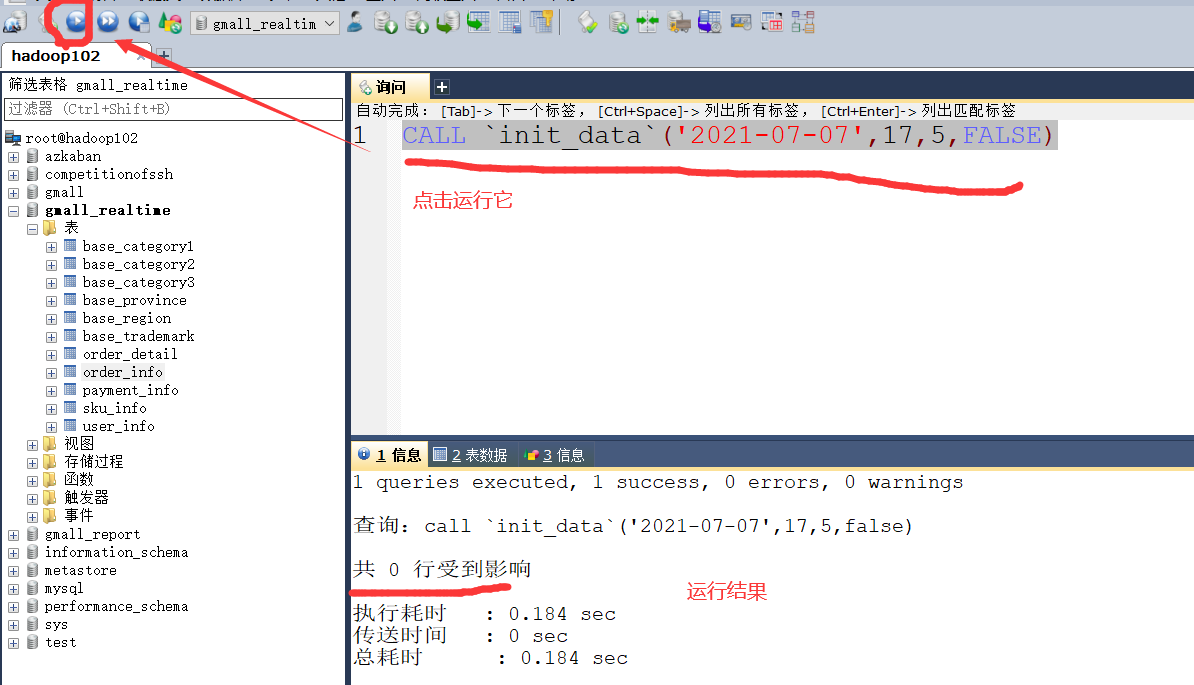
6)存储过程,模拟数据(运行sql脚本时已经创建,直接使用即可)
#CALL `init_data`(造数据的日期, 生成的订单数, 生成的用户数, 是否覆盖写) call `init_data`('2021-07-07',17,5,false)
1.3.3 修改/etc/my.cnf文件
sudo vim /etc/my.cnf
#Binlog日志的开启 log_bin=mysql-bin #选择Binlog的格式 binlog_format=row #保证server-id是唯一的 server-id=1 #只记录哪些库的写操作 binlog-do-db=gmall_realtime
1.3.4 重启MySql并查看状态
sudo systemctl restart mysqld
sudo systemctl status mysqld

1.4 Canal 安装
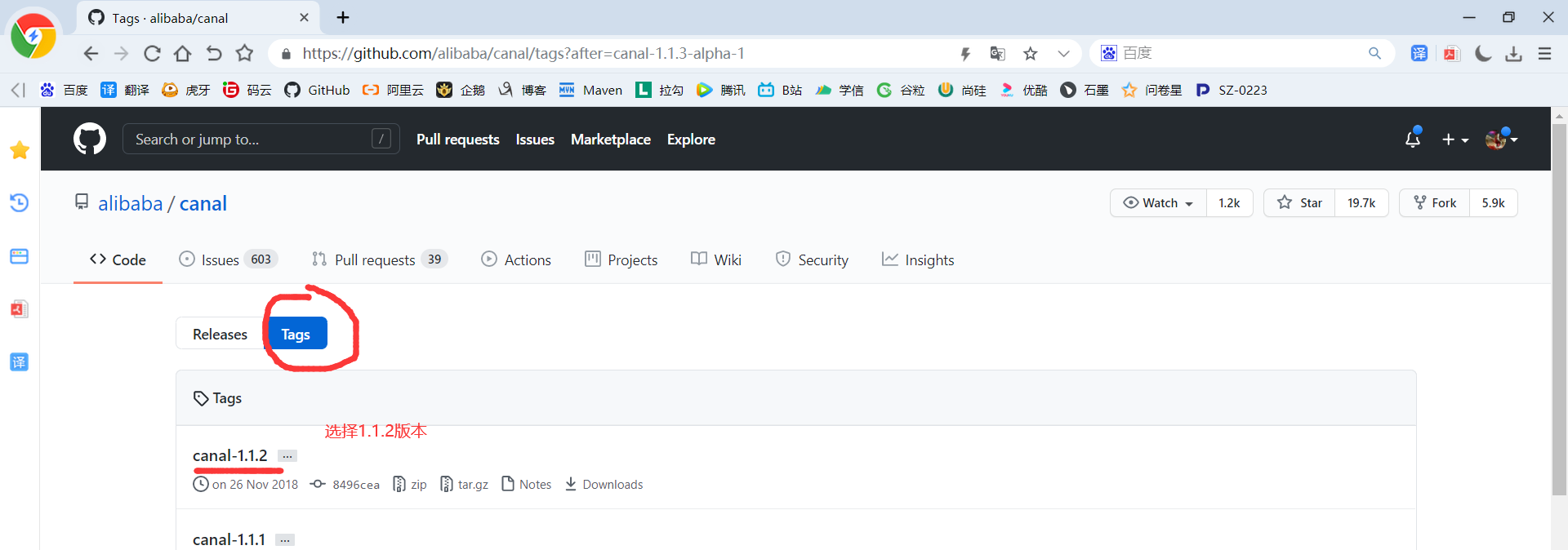
1.4.1 Canal的下载(我们下载1.1.2版本的即可)

1)伪官网下载地址:https://github.com/alibaba/canal/releases ,找到1.1.2版本,下载它
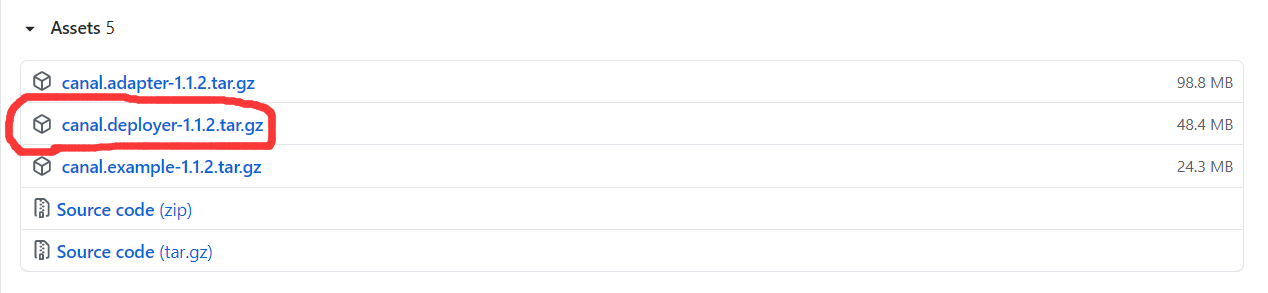
2)我已经下载下来了,网盘链接下载地址:https://pan.baidu.com/s/1p6vh6FOe-0wd4U8tyuKslQ 提取码:fzbq
3)下载完成后将其上传至hadoop104机器中的/opt/software/
4)在/opt/module/目录下创建canal目录
mkdir /opt/module/canal
5)解压
tar -zxvf /opt/software/canal.deployer-1.1.2.tar.gz -C /opt/module/canal/
1.4.2 修改canal的配置
1)修改canal.properties
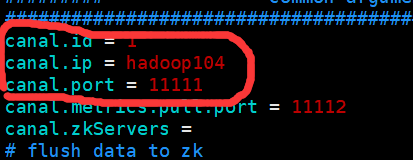
vim /opt/module/canal/conf/canal.properties
#我的canal安装在hadoop104
canal.ip = hadoop104
#这个文件是canal的基本通用配置,主要关心一下端口号,不改的话默认就是11111
canal.port = 11111
2)修改instance.properties(该文件的作用主要是针对要追踪的MySQL的实例配置)
vim /opt/module/canal/conf/example/instance.properties
#slaveId不能与mysql中的server-id重复
canal.instance.mysql.slaveId=2
#mysql的地址和端口号,我的mysql安装在hadoop102,你的安装在哪就写哪
canal.instance.master.address=hadoop102:3306
#从binlog的哪个文件的哪个位置开始同步 需要在主机上执行show master status查看最新的位置,你运行的结果是啥你就写啥,不要照抄我的
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=88546
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8

1.4.3 启动canal
/opt/module/canal/bin/startup.sh
1.4.4 停止canal
/opt/module/canal/bin/stop
1.5 数据监控模块---抓取订单数据
1.5.1 创建gmall_canalclient模块

1.5.2 pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>gmall_sparkstream</artifactId> <groupId>com.yuange</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>gmall_canalclient</artifactId> <dependencies> <dependency> <groupId>com.yuange</groupId> <artifactId>gmall_common</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.2</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version> </dependency> </dependencies> </project>
1.5.3 通用监视类
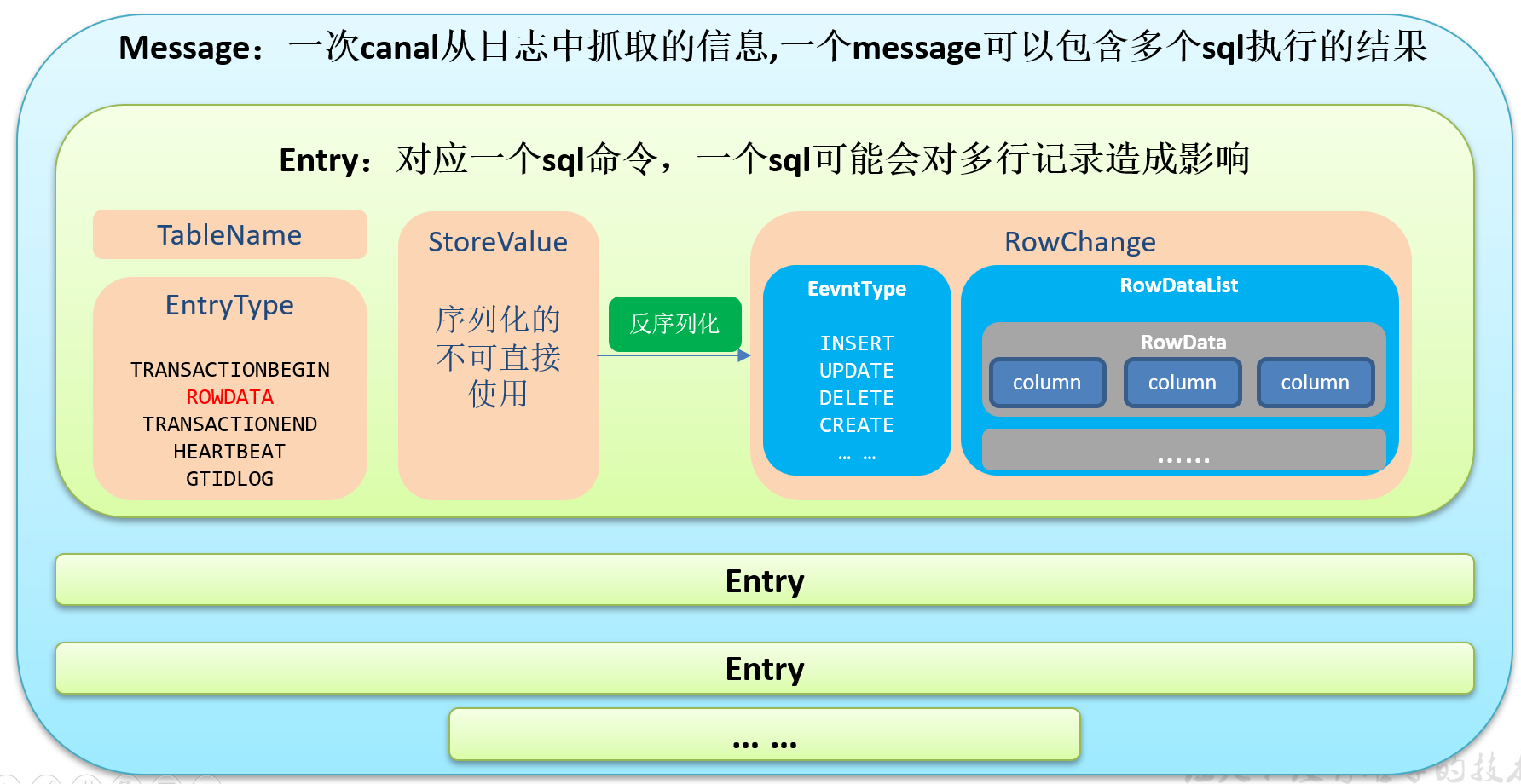
1)Canal封装的数据结构
2)创建生产者,MyProducer.java
package com.yuange.canal; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; /** * @作者:袁哥 * @时间:2021/7/7 18:54 */ public class MyProducer { private static Producer<String,String> producer; static { producer=getProducer(); } // 提供方法返回生产者 public static Producer<String,String> getProducer(){ Properties properties = new Properties(); //参考 ProducerConfig properties.put("bootstrap.servers","hadoop102:9092,hadoop103:9092,hadoop104:9092"); properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); return new KafkaProducer<String, String>(properties); } //发送数据至kafka public static void sendDataToKafka(String topic,String msg){ producer.send(new ProducerRecord<String, String>(topic,msg)); } }
3)监控Mysql,MyClient.java
package com.yuange.canal; import com.alibaba.fastjson.JSONObject; import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.protocol.CanalEntry; import com.alibaba.otter.canal.protocol.Message; import com.google.protobuf.ByteString; import com.google.protobuf.InvalidProtocolBufferException; import com.yuange.constants.Constants; import java.net.InetSocketAddress; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/7 18:10 * 步骤: * ①创建一个客户端:CanalConnector(SimpleCanalConnector: 单节点canal集群、ClusterCanalConnector: HA canal集群) * ②使用客户端连接 canal server * ③指定客户端订阅 canal server中的binlog信息 * ④解析binlog信息 * ⑤写入kafka * * 消费到的数据的结构: * Message: 代表拉取的一批数据,这一批数据可能是多个SQL执行,造成的写操作变化 * List<Entry> entries : 每个Entry代表一个SQL造成的写操作变化 * id : -1 说明没有拉取到数据 * Entry: * CanalEntry.Header header_ : 头信息,其中包含了对这条sql的一些说明 * private Object tableName_: sql操作的表名 * EntryType; Entry操作的类型 * 开启事务: 写操作 begin * 提交事务: 写操作 commit * 对原始数据进行影响的写操作: rowdata * update、delete、insert * ByteString storeValue_: 数据 * 序列化数据,需要使用工具类RowChange,进行转换,转换之后获取到一个RowChange对象 */ public class MyClient { public static void main(String[] args) throws InterruptedException, InvalidProtocolBufferException { /** * 创建一个canal客户端 * public static CanalConnector newSingleConnector( * SocketAddress address, //指定canal server的主机名和端口号 * tring destination, //参考/opt/module/canal/conf/canal.properties中的canal.destinations 属性值 * String username, //不是instance.properties中的canal.instance.dbUsername * String password //参考AdminGuide(从canal 1.1.4 之后才提供的),链接地址:https://github.com/alibaba/canal/wiki/AdminGuide * ) {...} * */ CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("haddoop104", 11111), "example", "", ""); //使用客户端连接 canal server canalConnector.connect(); //指定客户端订阅 canal server中的binlog信息 只统计在Order_info表 canalConnector.subscribe("gmall_realtime.order_info"); //不停地拉取数据 Message[id=-1,entries=[],raw=false,rawEntries=[]] 代表当前这批没有拉取到数据 while (true){ Message message = canalConnector.get(100); //判断是否拉取到了数据,如果没有拉取到,歇一会再去拉取 if (message.getId() == -1){ System.out.println("暂时没有数据,先等会"); Thread.sleep(5000); continue; } // 数据的处理逻辑 List<CanalEntry.Entry> entries = message.getEntries(); for (CanalEntry.Entry entry : entries) { //判断这个entry的类型是不是rowdata类型,只处理rowdata类型 if (entry.getEntryType().equals(CanalEntry.EntryType.ROWDATA)){ ByteString storeValue = entry.getStoreValue(); //数据 String tableName = entry.getHeader().getTableName(); //表名 handleStoreValue(storeValue,tableName); } } } } private static void handleStoreValue(ByteString storeValue, String tableName) throws InvalidProtocolBufferException { //将storeValue 转化为 RowChange CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue); /** * 一个RowChange代表多行数据 * order_info: 可能会执行的写操作类型,统计GMV total_amount * insert : 会-->更新后的值 * update : 不会-->只允许修改 order_status * delete : 不会,数据是不允许删除 * 判断当前这批写操作产生的数据是不是insert语句产生的 * */ if (rowChange.getEventType().equals(CanalEntry.EventType.INSERT)){ //获取行的集合 List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList(); for (CanalEntry.RowData rowData : rowDatasList){ JSONObject jsonObject = new JSONObject(); //获取insert后每一行的每一列 List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList(); for (CanalEntry.Column column : afterColumnsList) { jsonObject.put(column.getName(),column.getValue()); } //发送数据至Kafka,获取列名和列值 MyProducer.sendDataToKafka(Constants.GMALL_ORDER_INFO, jsonObject.toJSONString()); } } } }
4)添加log4j.properties
# Set everything to be logged to the console log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
1.5.4 测试
1)启动MyClient中的main方法
2)使用存储过程模拟业务数据
call `init_data`('2021-07-07',15,3,false)
3)查看Idea控制台,发现已经成功同步了数据
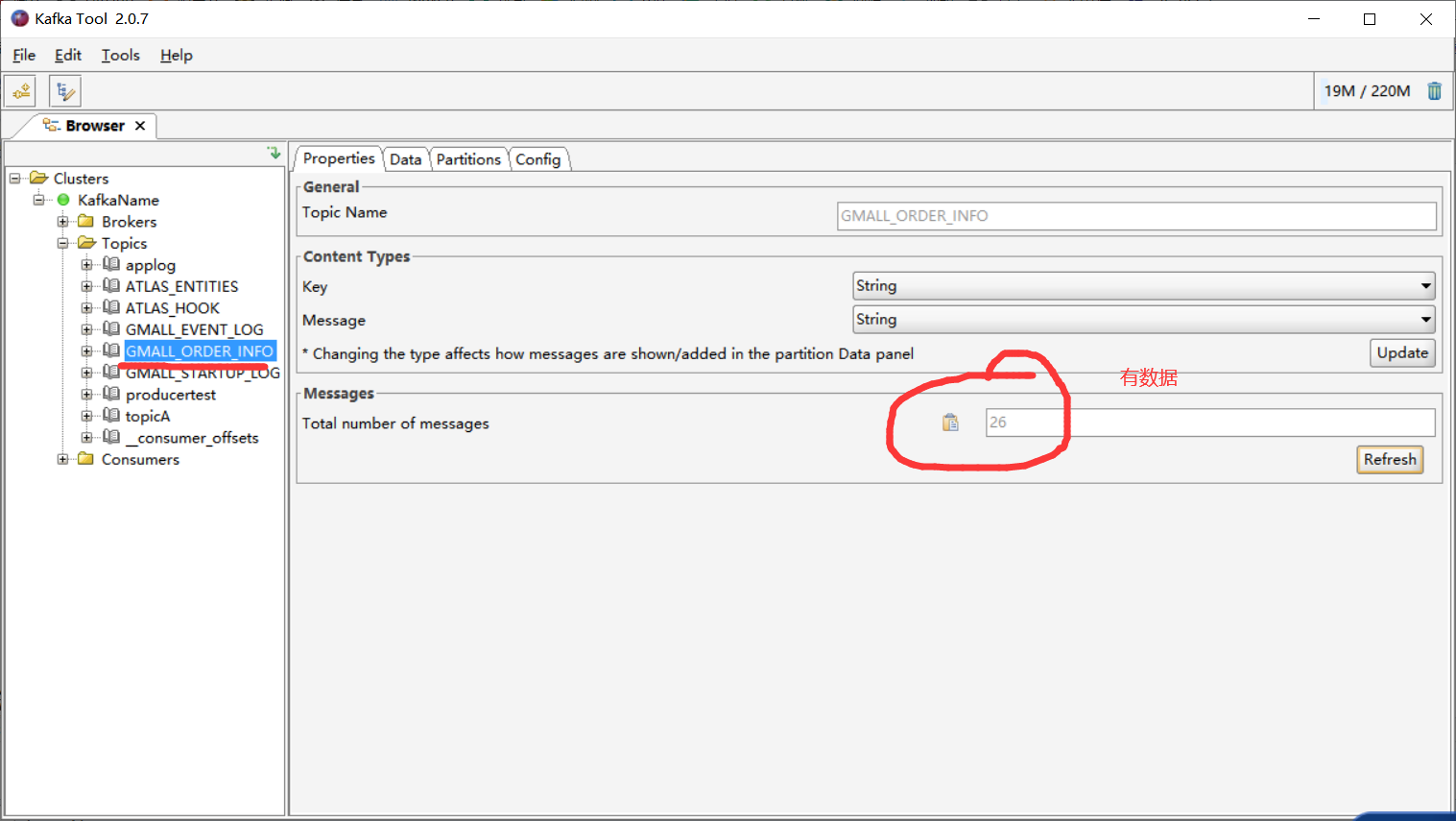
4)查看kafka中的GMALL_ORDER_INFO 主题
第2章 实时处理
2.1 Phoenix建表
sqlline.py hadoop103:2181
create table gmall_order_info ( id varchar primary key, province_id varchar, consignee varchar, order_comment varchar, consignee_tel varchar, order_status varchar, payment_way varchar, user_id varchar, img_url varchar, total_amount double, expire_time varchar, delivery_address varchar, create_time varchar, operate_time varchar, tracking_no varchar, parent_order_id varchar, out_trade_no varchar, trade_body varchar, create_date varchar, create_hour varchar);

2.2 在gmall_realtime中新建样例类,OrderInfo
package com.yuange.realtime.beans /** * @作者:袁哥 * @时间:2021/7/7 20:41 */ case class OrderInfo( id: String, province_id: String, consignee: String, order_comment: String, var consignee_tel: String, order_status: String, payment_way: String, user_id: String, img_url: String, total_amount: Double, expire_time: String, delivery_address: String, create_time: String, operate_time: String, tracking_no: String, parent_order_id: String, out_trade_no: String, trade_body: String, // 方便分时和每日统计,额外添加的字段 var create_date: String, var create_hour: String)
2.3 SparkStreaming消费kafka并保存到HBase中
package com.yuange.realtime.app import java.time.LocalDateTime import java.time.format.DateTimeFormatter import com.alibaba.fastjson.JSON import com.yuange.constants.Constants import com.yuange.realtime.beans.OrderInfo import com.yuange.realtime.utils.MyKafkaUtil import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.kafka.clients.consumer.{ConsumerRecord, ConsumerRecords} import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.phoenix.spark._ /** * @作者:袁哥 * @时间:2021/7/7 20:45 */ object GMVApp extends BaseApp { override var appName: String = "GMVApp" override var duration: Int = 10 def main(args: Array[String]): Unit = { val ds: InputDStream[ConsumerRecord[String,String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_ORDER_INFO,streamingContext) //将kafka中的数据封装为样例类 val ds1: DStream[OrderInfo] = ds.map(record => { val orderInfo: OrderInfo = JSON.parseObject(record.value(),classOf[OrderInfo]) // 封装create_date 和 create_hour "create_time":"2021-07-07 01:39:33" val formatter1: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss") val formatter2: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd") val time: LocalDateTime = LocalDateTime.parse(orderInfo.create_date,formatter1) orderInfo.create_date = time.format(formatter2) orderInfo.create_hour = time.getHour.toString // 订单的明细数据,脱敏 演示手机号脱敏 orderInfo.consignee_tel = orderInfo.consignee_tel.replaceAll("(\w{3})\w*(\w{4})", "$1****$2") orderInfo }) //写入hbase ds1.foreachRDD(rdd => { rdd.saveToPhoenix( "GMALL_ORDER_INFO", Seq("ID","PROVINCE_ID", "CONSIGNEE", "ORDER_COMMENT", "CONSIGNEE_TEL", "ORDER_STATUS", "PAYMENT_WAY", "USER_ID","IMG_URL", "TOTAL_AMOUNT", "EXPIRE_TIME", "DELIVERY_ADDRESS", "CREATE_TIME","OPERATE_TIME","TRACKING_NO","PARENT_ORDER_ID","OUT_TRADE_NO", "TRADE_BODY", "CREATE_DATE", "CREATE_HOUR"), HBaseConfiguration.create(), Some("hadoop103:2181") ) }) } }
2.4 测试
1)启动gmall_canalclient模块中的MyClient中的main方法
2)启动gmall_realtime模块中的GMVApp中的main方法
3)使用存储过程模拟业务数据
call `init_data`('2021-07-07',13,2,false)

4)查看Idea控制台
5)使用phoenix查看GMALL_ORDER_INFO表中是否有数据
select * from GMALL_ORDER_INFO limit 10;

第3章 数据接口发布
3.1 代码清单
|
控制层 |
PublisherController |
实现接口的web发布 |
|
服务层 |
PublisherService |
数据业务查询interface |
|
PublisherServiceImpl |
业务查询的实现类 |
|
|
数据层 |
OrderMapper |
数据层查询的interface |
|
OrderMapper.xml |
数据层查询的实现配置 |
3.2 接口
3.2.1 访问路径
|
总数 |
http://localhost:8070/realtime-total?date=2020-08-18 |
|
分时统计 |
http://localhost:8070/realtime-hours?id=order_amount&date=2020-08-18 |
3.2.2 要求数据格式
|
总数 |
[{"id":"dau","name":"新增日活","value":1200}, {"id":"new_mid","name":"新增设备","value":233 }, {"id":"order_amount","name":"新增交易额","value":1000.2 }] |
|
分时统计 |
{"yesterday":{"11":383,"12":123,"17":88,"19":200 }, "today":{"12":38,"13":1233,"17":123,"19":688 }} |
3.3 代码开发(gmall_publisher模块中操作)
3.3.1 beans层,新建GMVData.java
package com.yuange.gmall.gmall_publisher.beans; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/7 22:22 */ @AllArgsConstructor @NoArgsConstructor @Data public class GMVData { private String hour; private Double amount; }
3.3.2 mapper层,修改PublisherMapper接口,添加如下抽象方法
//查询每天的总交易额 Double getGMVByDate(String date); //查询分时交易额 List<GMVData> getGMVDatasByDate(String date);
3.3.3 service层
1)修改PublisherService接口,添加如下抽象方法
//查询每天的总交易额 Double getGMVByDate(String date); //查询分时交易额 List<GMVData> getGMVDatasByDate(String date);
2)修改PublisherServiceImpl实现类,添加如下实现
@Override public Double getGMVByDate(String date) { return publisherMapper.getGMVByDate(date); } @Override public List<GMVData> getGMVDatasByDate(String date) { return publisherMapper.getGMVDatasByDate(date); }
3.3.4 controller层
package com.yuange.gmall.gmall_publisher.controller; import com.alibaba.fastjson.JSONObject; import com.yuange.gmall.gmall_publisher.beans.DAUData; import com.yuange.gmall.gmall_publisher.beans.GMVData; import com.yuange.gmall.gmall_publisher.service.PublisherService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.time.LocalDate; import java.util.ArrayList; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/6 23:10 */ @RestController public class GmallPublisherController { @Autowired private PublisherService publisherService; //http://localhost:8070/realtime-total?date=2021-07-06 @RequestMapping(value = "/realtime-total") public Object handle1(String date){ ArrayList<JSONObject> result = new ArrayList<>(); Integer dau = publisherService.getDAUByDate(date); Integer newMidCounts = publisherService.getNewMidCountByDate(date); Double gmv = publisherService.getGMVByDate(date); JSONObject jsonObject1 = new JSONObject(); jsonObject1.put("id","dau"); jsonObject1.put("name","新增日活"); jsonObject1.put("value",dau); JSONObject jsonObject2 = new JSONObject(); jsonObject2.put("id","new_mid"); jsonObject2.put("name","新增设备"); jsonObject2.put("value",newMidCounts); JSONObject jsonObject3 = new JSONObject(); jsonObject3.put("id","order_amount"); jsonObject3.put("name","新增交易额"); jsonObject3.put("value",gmv); result.add(jsonObject1); result.add(jsonObject2); result.add(jsonObject3); return result; } @RequestMapping(value = "/realtime-hours") public Object handle2(String id,String date){ //根据今天求昨天的日期 LocalDate toDay = LocalDate.parse(date); String yestodayDate = toDay.minusDays(1).toString(); JSONObject result = new JSONObject(); if ("dau".equals(id)){ List<DAUData> todayDatas = publisherService.getDAUDatasByDate(date); List<DAUData> yestodayDatas = publisherService.getDAUDatasByDate(yestodayDate); JSONObject jsonObject1 = parseData(todayDatas); JSONObject jsonObject2 = parseData(yestodayDatas); result.put("yesterday",jsonObject2); result.put("today",jsonObject1); }else{ List<GMVData> todayDatas = publisherService.getGMVDatasByDate(date); List<GMVData> yestodayDatas = publisherService.getGMVDatasByDate(yestodayDate); JSONObject jsonObject1 = parseGMVData(todayDatas); JSONObject jsonObject2 = parseGMVData(yestodayDatas); result.put("yesterday",jsonObject2); result.put("today",jsonObject1); } return result; } public JSONObject parseGMVData(List<GMVData> datas){ JSONObject jsonObject = new JSONObject(); for (GMVData data : datas) { jsonObject.put(data.getHour(),data.getAmount()); } return jsonObject; } //负责把 List<DAUData> 封装为一个JSONObject public JSONObject parseData(List<DAUData> datas){ JSONObject jsonObject = new JSONObject(); for (DAUData data : datas) { jsonObject.put(data.getHour(),data.getNum()); } return jsonObject; } }
3.3.5 PublisherMapper.xml添加如下内容
<select id="getGMVByDate" resultType="double"> select sum(total_amount) from GMALL_ORDER_INFO where create_date = #{date} </select> <select id="getGMVDatasByDate" resultType="com.yuange.gmall.gmall_publisher.beans.GMVData" > select create_hour hour,sum(total_amount) amount from GMALL_ORDER_INFO where create_date = #{date} group by create_hour </select>
3.3.6 index.html添加如下内容
<br/> <a href="/realtime-hours?id=order_amount&date=2021-07-07">统计昨天和今天的分时GMV数据</a>
3.3.7 测试
1)运行GmallPublisherApplication

2)访问index.html:http://localhost:8070/


3.4 索引优化
#启动sqlline.py客户端
sqlline.py
create local index idx_gmall_order_create_date_hour on gmall_order_info(create_date,create_hour);
![]()