一、概述
近邻搜索在计算机科学中是一个非常基础的问题,在信息检索、模式识别、机器学习、聚类等领域有着广泛的应用。如果在d维空间中,我们有n个数据点,采用暴力搜索寻找最近邻的时间复杂度为O(dn)。当前我们的数据量越来越大,因此我们需要一些新的数据结构来查找最近邻,使得任意给定一个数据就能快速找到近邻数据点。早期的研究在低维空间取得了较好的效果,但是在高维空间时间复杂度却依然接近O(dn),这就是维度灾难带来的问题。近些年,提出的近似计算的方法可以克服维度灾难问题,其中最著名的就是Locality Sensitive Hashing(局部敏感哈希),简称LSH。
LSH是近似最近邻问题的一种随机化算法,其运算速度明显快于其它现有方法,特别是在高维空间。LSH的基本思想是从LSH函数族中随机选择哈希函数,将每个数据点哈希到哈希表中;在查找最近的邻居时,LSH只扫描与查询点具有相同哈希索引的点。
二、定义与算法流程
1)定义:
For r1≤ r2 and p2≤p1,a hash family H is(r1,r2,p1,p2)-sensitive if for all x,y ∈Sd-1:
- if ||x-y||2 ≤ r1, then PrH[h(x)=h(y)] ≥ p1
- if ||x-y||2 ≥ r2, then PrH[h(x)=h(y)] ≤ p2
h是hash famlily中的一个hash函数,我们主要关注r1=R,r2=cR这种情况,称作(R,c)-NN search,通过学习参数ρ来衡量一个哈希方案的敏感度:
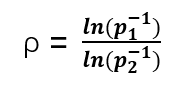
什么样的哈希函数才是符合局部敏感的呢?
如果距离近的点发生哈希碰撞的概率大于距离远的点就属于局部敏感哈希,也就是该哈希函数对数据点之间的距离是敏感的,局部相近的点能够尽可能hash到一个桶内。结合上述定义通俗来讲,两个点如果距离不大于r1就认为是相近的;如果距离最小是r2=c*r1(c>1)就认为是较远的,c就是上述远与近的间隔。hash函数的质量由两个关键参数表示:p1是近距离点发生哈希碰撞的概率,p2是远距离点发生碰撞的概率。p1和p2之间的间隙决定了哈希函数对距离变化的“敏感度”,此属性可以由上述ρ参数来表示,ρ<1且越小越好,通常可以表示为距离间隙c的函数。
2)算法查找流程:
1、根据LSH设计好的hash函数族中,随机抽取k个hash函数,构建g(x)=(h1(x),...,hk(x))哈希表
2、采用1方式,构造L个哈希表,g1(x),...,gL(x),每个g(x)可以称之为一个桶。
3、假设有n个数据已经存放于L个哈希表中,随机给查询q,从L个桶中查找,只要与q存在一个桶的数据都认为是近似近邻数据,可以抽出来,假设有m个。
4、从m个数据中,再分别精确计算与q的距离,从而找出所需要的k个近邻数据。
注:可以设置k=nρ,L=ln(1/p1*n),从而保证算法以不变的概率来解决(R,c)-NN问题。
近年来,设计良好的局部敏感哈希函数和基于LSH的高效近邻搜索算法的问题引起了人们的广泛关注,都将研究重点放在查找效率尽可能高的情况下而且能达到更小的ρ。
三、相关工作
理论方面, Andoni和Indyk之前给出了可以证明的基于LSH的单位球面上欧氏距离的最近邻搜索算法,此算法最有名。具体来讲, 该算法的关键参数ρ = 1/(2c2-1),查询时间为O(nρ),空间复杂度为O(n1+ρ),算法的核心是一种称为球面的LSH方案,简称SLSH,适用于单位向量。该算法的关键特性是能够以一定概率区分开距离在 r1=√2/c、r2=√2之间的数据点。不幸的是,该算法不具备实际操作性,理论算法太过于复杂了,简单的计算一个hash函数,都比扫描106个点的数据时间复杂度高。
在实际应用方面,Charikar工作中引入的超平面LSH虽然具有较差的理论保证,但在实践中效果良好。由于超平面LSH算法可以非常高效地执行,因此它是基于LSH的近邻算法中的标准hash函数,其实现比线性扫描实际数据提高了多个数量级。
上述LSH理论与实践之间的差异提出了一个重要的问题:是否存在一个对局部敏感的hash函数,该函数具有最优的理论保证,且在实践中比超平面LSH效果更好呢?Andoni和Indyk证明了有一个局部敏感的散列函数族可以同时达到这两个目的。具体地说,该hash函数与他们早期提出的SLSH理论相匹配,结合一些附加技术后,给出了比超平面LSH更好的实验结果,这就是cross-polytope LSH。
四、Cross-polytope(正轴体)
正轴体(Cross-polytope)是一类在任意维均存在的凸正多胞体,正轴体的表面由若干个单形(Simplex)组成,单形的个数为2n。如二维正轴体(2-orthoplex,即正方形)的表面由4条线段组成;三维正轴体(3-orthoplex,即正八面体)的表面由8个等边三角形面组成;四维正轴体(4-orthoplex,即正十六胞体)的表面由16个正五胞体组成。
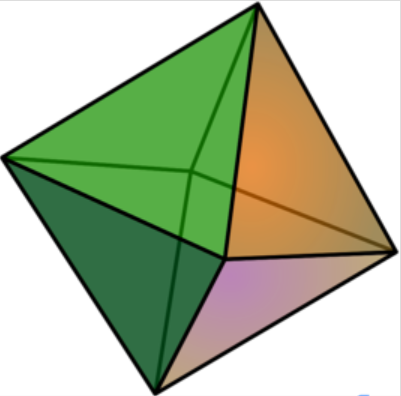
n维正轴体的顶点有2n个,均为坐标形如(±1,0,0,…)的点。如二维正轴体(即正方形)的4个顶点的坐标分别为(±1,0)、(0,±1);三维正轴体(即正八面体)的6个顶点的坐标分别为(±1,0,0)、(0,±1,0)、(0,0,±1);四维正轴体(即正十六胞体)的8个顶点的坐标分别为(±1,0,0,0)、(0,±1,0,0)、(0,0,±1,0)、(0,0,0,±1)。
五、Cross-polytope LSH
Cross-polytope LSH严格意义上来说就是SLSH的一种。之前的LSH方案考虑的都是Rd空间中任意的一点,SLSH考虑的是嵌入Rd空间的单位(d-1)球面上的任意点。SLSH使用随机旋转的规则多面体来分割单位超球的表面,在随机旋转多面体之后,散列函数h(x)被定义为分配给最接近x的顶点。换句话说,SLSH的hash函数像Voronoi图一样划分单位超球面的表面。目前已知的有三种规则多面体,分别是Simplex,Orthoplex (Cross polytope),Hypercube (Measure polytope)。
所以Cross-polytope LSH也是主要研究单位球面上欧几里德距离的LSH,这是一个重要的特殊情况,有几个原因:首先,球面情况在实际中有很多相关性可以利用,比如球面的欧几里德距离与角距离或者余弦相似度有很高的相关性;此外,在理论方面,从整个欧氏空间中的最近邻搜索变成到球面搜索,简化了问题。
1、定义hash函数
假设A∈Rdxd是服从高斯分布N(0,1)的随机矩阵(该矩阵相当于一个随机旋转),为了hash一个数据点x,采取下面公式:

ei∈Rd是第i个标准基向量,也就是cross-polytope上顶点,x转换为单位向量后在球面上随机旋转,最后找到离得最近的正轴体顶点就是其hash值,比如三维的如果离顶点(1,0,0)近,hash值就是1;离(0,1,0)近,hash值就是2。因为每个轴都有正负,所以hash值的值域就是[1,2d],d是数据点的维度。
在当前hash函数定义下,其关键参数指标如下:
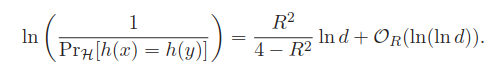

查询时间复杂度为O(d·nρ),空间复杂度为O(n1+ρ+dn)。
2、使cross-polytope LSH实用化
1)伪随机旋转
根据上面定义,cross-polytope LSH还不太实用,主要瓶颈在于随机旋转的采样、存储和应用。特别是,要将随机高斯矩阵与向量相乘,我们需要与d2成比例的时间,这对于高维的d是不可行的。为了解决这个问题,这里使用伪随机旋转,利用下面的线性转换方法代替随机高斯矩阵:
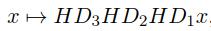
其中H是Hadamard变换,Di是随机对角±1矩阵。显然,这是一个正交变换,可以存储在O(d)空间中,并使用快速的Hadamard变换在时间O(d logd)中求值。目前还不知道如何从数学上严格证明为何这种伪随机旋转和完全随机旋转那样效果好,但经验计算表明,只有两种HDi的应用是不够的,当d趋于无穷时候,三种HDi的应用几乎等同于真正的随机旋转。
2)特征散列
对于输入向量x,如果是稀疏的,非零项远远小于特征维度,可以在进行随机旋转之前采用特征散列实现维度缩减。利用一个线性映:x->Sx,对稀疏向量进行维度缩减。S是随机稀疏矩阵d' X d,每一列只有一个均匀采样±1非零项,则计算开销变为O(S+d'logd')。
3、多探寻方案(Multiprobe scheme for the cross-polytope LSH)
多探寻方案方法主要针对基本LSH方法需要查询大量哈希表来保证搜索质量的缺点进行的优化,在保证相同时间效率的情况下,Multi-Probe比基本的LSH方法减少了一个数量级的哈希表数量。标准的LSH数据结构只考虑hash表的一个维度,也就是hash值。对于单一的cross-polytope哈希,可选散列值的顺序很简单,结合上面的定义,hash值其实选取的就是随机旋转后x绝对值最大的所在维度,正负轴的合在一起,所以取值共有d个。而多探寻方案从多维度来考虑,最大值所在维度没有发生hash碰撞,次大值所在维度应该是发生碰撞的第二概率,所以多探寻方案同时考虑了多个维度,对所有维度的绝对值从大到小排序,这就产生了多探测序列。
如果有多个hash函数,假设是k个,如何融合这些探测序列呢?原论文中考虑了呆查询点q与p的多个维度的概率,公式如下:

A代表的随机高斯旋转矩阵,x代表旋转后的q,h(p)代表p的标准hash值,rv代表x各维度绝对值从大到小排序后第v个值。我个人理解是在k个hash函数中,分别计算h(p)与x其中任意一个维度相等的概率,得到概率后论文中提到用大根堆进行排序,具体的可以看原论文,目前没有特别明白这一块。
LSH主页:http://www.cs.columbia.edu/~andoni/LSH/
参考论文:
1、Practical and Optimal LSH for Angular Distance
2、Spherical LSH for Approximate Nearest Neighbor Search on Unit Hypersphere
3、Fast Cross-Polytope Locality-Sensitive Hashing