运行平台: Windows
python版本: python3.5.2
IDE: pycharm
一、Scrapy简介
Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一系列的程序中。自己写的Python爬虫程序好比孤军奋战,而使用了Scrapy就好比手下有了千军万马。Scrapy可以起到事半功倍的效果
二、Scrapy安装
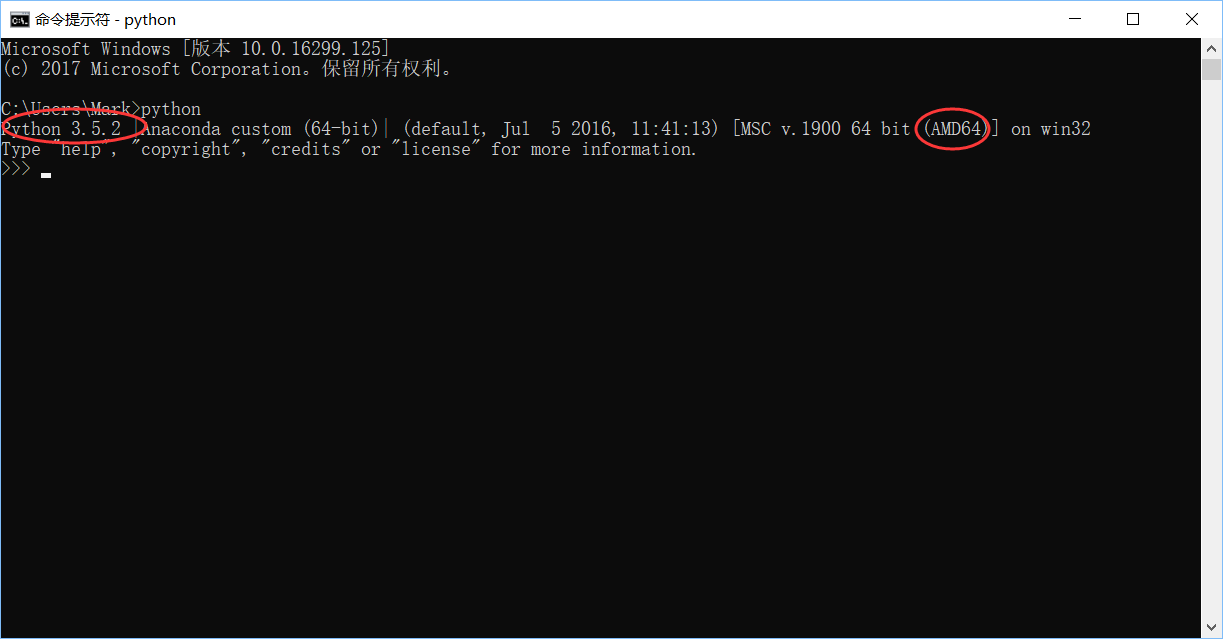
1.查看python版本
cmd中输入python,查看python版本,可以看到我的是3.5.2 64位
2.找到对应版本的第三方库搜索Lxml、Twisted、Scrapy,下载对应版本
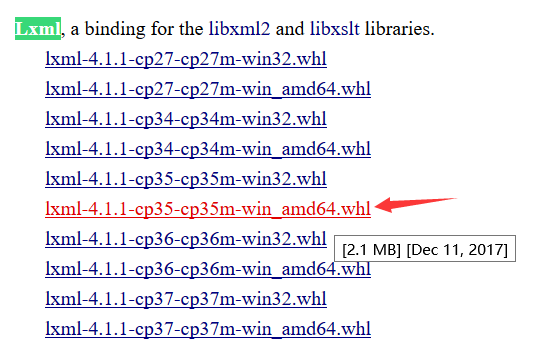
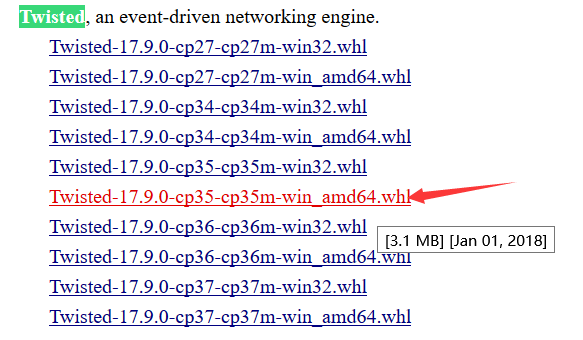
![]()
3.cmd进入文件所在的位置,依次执行如下命令(我开始用的pwershell装的,到scrapy那个失败了,才换回的cmd,所以有两个提示已经安装了)
(1)pip3 install wheel
![]()
(2)pip3 install lxml tab补齐

(3)pip3 install Twisted tab补齐
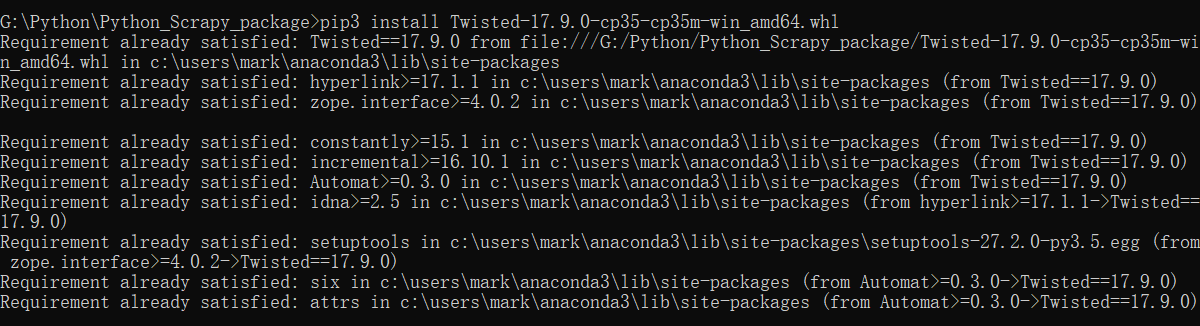
(4)pip3 install Scrapy tab补齐
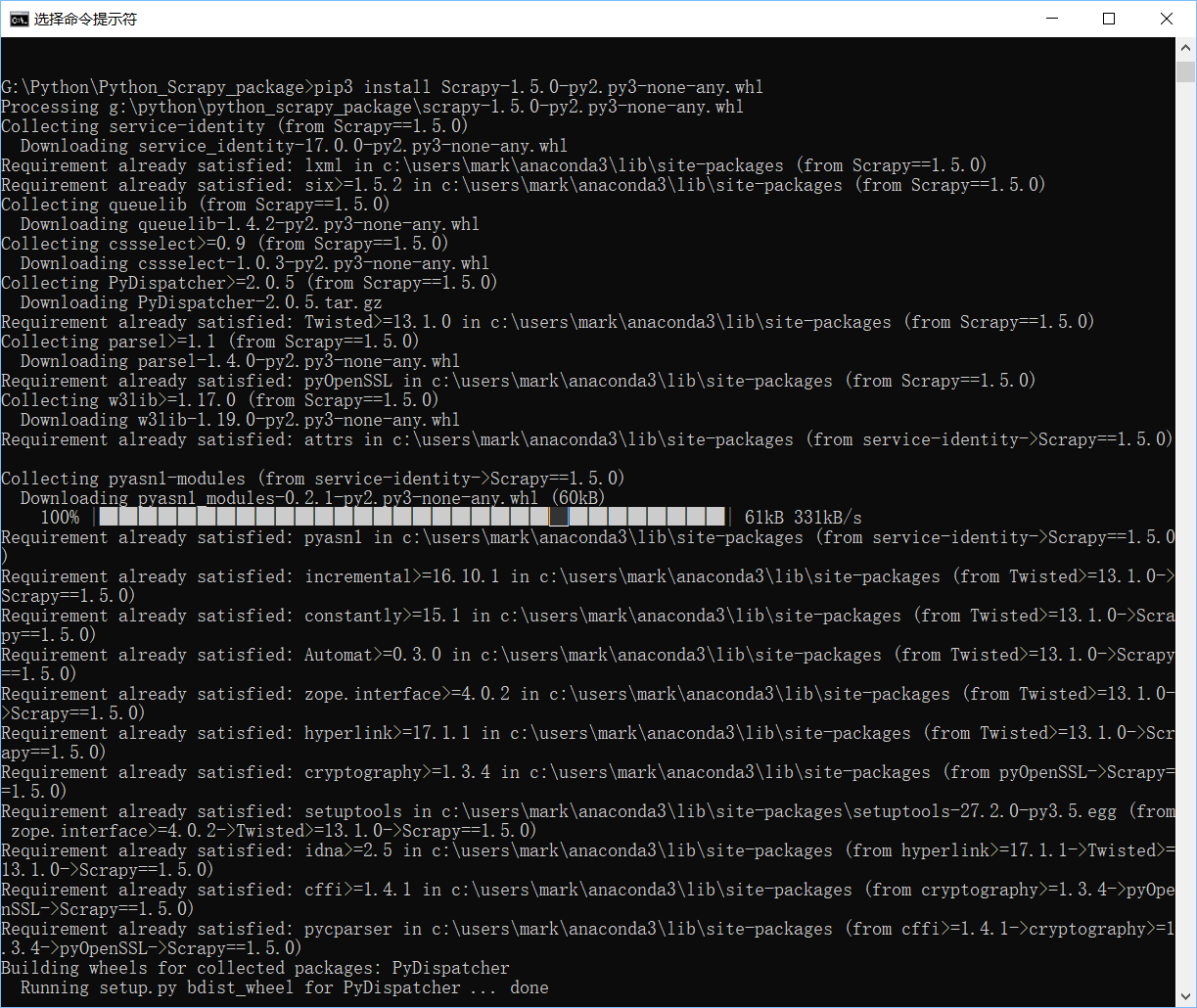

4.Scrapy安装完成后,还需要安装pywin32

一路下一步就OK