摘要:
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住 了数据集的逻辑操作
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
本发所讲函数
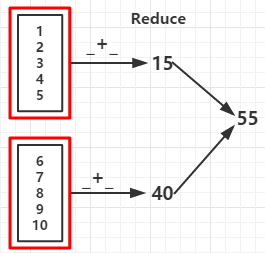
例1:
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(1 to 10,2)
val reduceRDD = rdd.reduce(_ + _)
val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53
val countRDD = rdd.count()
val firstRDD = rdd.first()
val takeRDD = rdd.take(5) //输出前个元素
val topRDD = rdd.top(3) //从高到底输出前三个元素
val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素
println("func +: "+reduceRDD)
println("func -: "+reduceRDD1)
println("count: "+countRDD)
println("first: "+firstRDD)
println("take:")
takeRDD.foreach(x => print(x +" "))
println("
top:")
topRDD.foreach(x => print(x +" "))
println("
takeOrdered:")
takeOrderedRDD.foreach(x => print(x +" "))
sc.stop
}
输出:
func +: 55 func -: 15 //如果分区数据为1结果为 -53 count: 10 first: 1 take: 1 2 3 4 5 top: 10 9 8 takeOrdered: 1 2 3
(RDD依赖图:红色块表示一个RDD区,黑色块表示该分区集合,下同)
(RDD依赖图)

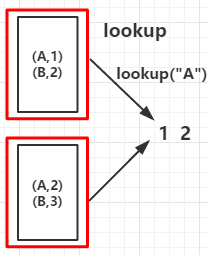
9.collectAsMap():作用于K-V类型的RDD上,作用与collect不同的是collectAsMap函数不包含重复的key,对于重复的key。后面的元素覆盖前面的元素
例2:
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("KVFunc")
val sc = new SparkContext(conf)
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val rdd = sc.parallelize(arr,2)
val countByKeyRDD = rdd.countByKey()
val collectAsMapRDD = rdd.collectAsMap()
println("countByKey:")
countByKeyRDD.foreach(print)
println("
collectAsMap:")
collectAsMapRDD.foreach(print)
sc.stop
}
输出:
countByKey: (B,2)(A,2) collectAsMap: (A,2)(B,3)

(RDD依赖图)
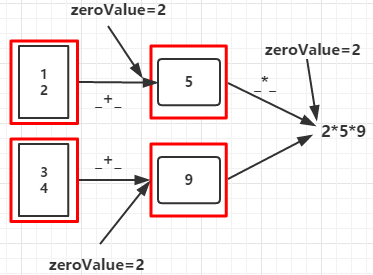
seqOp函数将每个分区的数据聚合成类型为U的值,comOp函数将各分区的U类型数据聚合起来得到类型为U的值
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List(1,2,3,4),2)
val aggregateRDD = rdd.aggregate(2)(_+_,_ * _)
println(aggregateRDD)
sc.stop
}
输出:
90
步骤1:分区1:zeroValue+1+2=5 分区2:zeroValue+3+4=9
步骤2:zeroValue*分区1的结果*分区2的结果=90

(RDD依赖图)
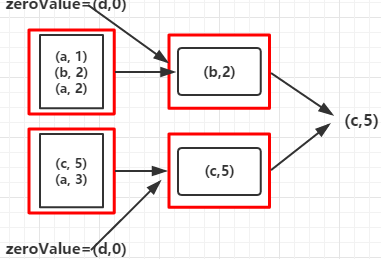
12.fold(zeroValue:T)(op:(T,T) => T):通过op函数聚合各分区中的元素及合并各分区的元素,op函数需要两个参数,在开始时第一个传入的参数为zeroValue,T为RDD数据集的数据类型,,其作用相当于SeqOp和comOp函数都相同的aggregate函数
例3
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(("a", 1), ("b", 2), ("a", 2), ("c", 5), ("a", 3)), 2)
val foldRDD = rdd.fold(("d", 0))((val1, val2) => { if (val1._2 >= val2._2) val1 else val2
})
println(foldRDD)
}
输出:
c,5
其过程如下:
1.开始时将(“d”,0)作为op函数的第一个参数传入,将Array中和第一个元素("a",1)作为op函数的第二个参数传入,并比较value的值,返回value值较大的元素
2.将上一步返回的元素又作为op函数的第一个参数传入,Array的下一个元素作为op函数的第二个参数传入,比较大小
3.重复第2步骤
每个分区的数据集都会经过以上三步后汇聚后再重复以上三步得出最大值的那个元素,对于其他op函数也类似,只不过函数里的处理数据的方式不同而已

(RDD依赖图)