@
**
第三章 组合数据类型
**
3.1 序列类型
3.1.1 元组
元组和字符串类似,是固定的,不能替换或者删改包含的任意项
(1, 2, 3) + (1, 2, 3) #(1, 2, 3, 1, 2, 3)
(1, 2, 3, 4) * 2 #(1, 2, 3, 4, 1, 2, 3, 4)
(1, 2, 3, 4)[:3] #(1, 2, 3)
(1, 2, 3, 1, 1, 3).count(1) #3
(1, 2, 3, 1, 1, 3).index(3) #2
hair = 'black', 'brown', 'blonde', 'red'
hair[2]
hair[-3:]
hair[:2], 'gray', hair[2:] #(('black', 'brown'), 'gray', ('blonde', 'red'))
hair[:2] + ('gray',) + hair[2:] #('black', 'brown', 'gray', 'blonde', 'red')
#请注意上面一元组的写法,别弄错了
things = (1, -7.5, ('pea', (5, 'XyZ'), 'queue'))
things[2][1][1][2] # 'Z'
3.1.2 命名的元组 (collections.nametuple())
collections 模块提供了 namedtuple() 函数,该函数用于创建自定义的元组数据类型。
import collections
Sale = collections.namedtuple('Sale', 'productid customerid data quantity price')
sales = []
sales.append(Sale(432, 932, '2008-9-14', 3, 7.99))
sales.append(Sale(419, 874, '2008-9-15', 1, 18.49))
total = 0
for sale in sales:
total += sale.quantity * sale.price
print('Total ${0:.2f}'.format(total)) #Total $42.46
第二个例子:
Aircraft = collections.namedtuple('Aircraft',
'manufacturer model seating')
Seating = collecttions.namedtuple('Seating', 'minimum maximum')
aircraft = Aircraft('Airbus', 'A320-200', Seating(100, 220))
aircraft.seating.maximum #220
print('{0} {1}'.format(aircraft.manufacturer, aircraft.model))
print('{0.manufacturer} {0.model}'.format(aircraft))
#命名的元组还有几个私有方法,有一个namedtuple._asdict()的方法特别有用
print('{manufacturer} {model}'.format(**aircraft._asdict()))
#Airbus A320-200
3.1.3 列表 (查询有关函数点这)
列表方法:
L.append(x)
L.count(x)
L.extend(m) | L += m
L.index(x, start, end)
L.insert(i, x) #在索引i的位置上插入x
a = [1, 2, 3]
a[1:1] = [4] # == a.insert(1, 4)
a # [1, 4, 2, 3]
L.pop() #返回并移除list L最右边的数据项
L.pop(i) # 索引为i的
L.remove(x) #从list中移除最左边出现的数据项x,如果找不到产生ValueError
#a[2:4] = [] | del a[2:4] euqal
L.reverse()
L.sort(...) #排序 接受可选的key和reverse参数
first, *rest = [9, 2, -4, 8, 7]
first, *mid, last = 'Charles Philip Arthur George Windsor.'.split()
*directories, executable = '/usr/local/bin/gvim'.split('/')
#(['', 'usr', 'local', 'bin'], 'gvim')
3.1.4 列表内涵
[expression for item in iterable if condition]
[y for y in range(1900, 1940) if (y % 4 == 0 and y % 100 != 0) or (y % 400 == 0)]
#[1904, 1908, 1912, 1916, 1920, 1924, 1928, 1932, 1936]
[s + z + c for s in 'MF' for z in 'SMLX' for c in 'BGW' if not (s == 'F' and z == 'X')]
第二行代码,和一般的for循环似乎不同,条件的判断似乎必须在循环的最后关头才会进行判断,所以其实for循环的顺序发生颠倒也没有什么关系。
3.2 集合类型
只有可哈希运算的对象可以添加到集合中。
为什么需要哈希?
3.2.1 集合(查询有关函数点这)
集合是0个或多个对象引用的无序组合,且排他!
{1, 1, 2, 3, 4, 5} #{1, 2, 3, 4, 5}
空集合只能用set()来创建, '{}' 用来创建空dict
| 语法 | 描述 |
|---|---|
| s.add(x) | 将数据项x添加到集合s中——如果s中尚未包含x |
| s.clear() | 移除集合s中的所有数据项 |
| s.copy() | 返回集合s的浅拷贝* |
| s.difference(t) s-t | 返回一个新集合, 其中包含在s中但不在集合t中的所有数据项* |
| s.difference_update(t) s -= t | 移除每一个在集合t但不在集合s中的项 |
| s.discard(x) | 如果数据项x存在于集合s中,就移除该数据项,参见set.remove() |
| s.intersection(t) s & t | 返回一个新集合,其中包含所有同时包含在集合t与s中的数据项* |
| s.intersection(t) s &= t | 使得集合s包含自身与集合t交集 |
| s.isdisjoint(t) | 如果集合s与t没有相同的项, 就返回True* |
| s.issubset(t) s<=t | 如果集合s与集合t相同, 或者是t的子集,就返回True。 使用s<t可以测试s是否是t的真子集* |
| s.issuperset(t) s >= t | 如果集合s与集合t相同,或者是t的超集,就返回True。使用s>t可以测试s是否是t的真子集* |
| s.pop() | 返回并移除集合s中一个随即项,如果s为空集,就产生KeyError异常 |
| s.remove(x) | 从集合s中移除数据项x,如果s中不包含x,就产生KeyError异常,参见set.discard() |
| s.symmetric_difference(t) s^t | 返回一个新集合,其中包含s与t中的每个数据项,但不包含同时在这俩个集合中的数据项* |
| s.symmetric_difference_update(t) s ^= t | 使得集合s只包含其自身与集合t的对称差 |
| s.union(t) s | t | 返回一个新集合,其中包含集合s中的所有数据项,以及在t中而不在s中的数据项* |
| s.update(t) s|= t | 将集合t中每个s中不包含的数据项添加到集合s中 |
* 这一方法及其操作符也可用于frozensets
3.2.2 集合内涵
{expression for item in iterable}
{expression for item in iterable if condition}
html = {x for x in files if x.lower().endswith(('.htm', '.html'))}
固定集合(forzeonset)
如果讲二元运算符应用于集合于固定集合,那么产生结果的数据类型与左边操作数的数据类型一致。
3.3 映射类型
只有可哈希运算的对象才能作为字典的键。
3.3.1 字典 (查询有关函数点这)
dict() | {}
d1 = dict({'id': 1948, 'name': 'Washer', 'size': 3})
d2 = dict(id = 1948, name = 'Washer', size = 3)
d3 = dict([('id', 1948), ('name', 'Washer'), ('size', 3)])
d4 = dict(zip(('id', 'name', 'size'), (1948, 'Washer', 3)))
d5 = {'id': 1948, 'name': 'Washer', 'size': 3}
#{'id': 1948, 'name': 'Washer', 'size': 3}
del d1['id'] #删除'd1'
d1.pop('id') #删除'd1'
del : del删除的不是数据,而是删除对象与数据之间的绑定,若数据没有被其他对象引用,则进入垃圾收集流程。
| 语法 | 描述 |
|---|---|
| d.clear() | 从dict d 中移除所有项 |
| d.copy() | 返回dict d的浅拷贝 |
| d.fromkeys(s, v) | 返回一个dict,该字典的键为序列s中的项,值为None或v |
| d.get(k) | 返回键k相关联的值,如果k不在dict d中就返回None |
| d.get(k, v) | 返回键k相关联的值,如果k不在dict d中就返回v |
| d.items() | 返回dict d 中所有(key, value)对的视图 |
| d.keys() | 返回dict d 中所有键的视图 |
| d.pop(k) | 返回键k相关联的值,并移除键为k的项,如果k不包含在d中,就产生KeyError异常 |
| d.popitem() | 返回并移除dict d 中任意一个(key, value)对,如果d为空就产生KeyError异常 |
| d.setdefault(k, v) | 与dict.get()方法一样,不同之处在于,如果k没有包含在dict d中就插入一个键为k的新项,其值为None或v |
| d.update(a) | 将a中每个尚未包含在dict d中的(key, value) 对添加到d,对同时包含在d与a中的每个键,使用a中对应的值替换d中对应的值——a可以是字典,也可以是(key,value)对的一个iterable,或关键字参数 |
| d.values() | 返回dict d中所有值的视图 |
视图是一个只读的iterable对象
特别的是:如果视图引用的字典发生变化,那么视图将反映该变换;键视图与项视图支持一些类似于集合的操作。
& | - ^
d1 = dict(a = 1, b = 2, c = 3)
d2 = dict(x = 1, y = 2, z = 3)
for item in d1.items():
print(item)
d1['a'] = 7
for item in d1.items():
print(item)
#('a', 1)
#('b', 2)
#('c', 3)
#('a', 7)
#('b', 2)
#('c', 3)
d1 = dict(a = 1, b = 2, c = 3)
d2 = dict(x = 1, y = 2, z = 3)
v = d1.items()
x = d2.items()
for item in v | x:
print(item)
#('b', 2)
#('y', 2)
#('z', 3)
#('c', 3)
#('x', 1)
#('a', 1)
d = {}.fromkeys('ABCD', 3) #{'A':3, 'B':3, 'C':3, 'D':4}
s = set('ACX') # {'A', 'C', 'X'}
matches = d.keys() & s # {'A', 'C'}
一个例子(没玩过)
import string
import sys
words = {}
strip = string.whitespace + string.punctuation + string.digits + ""'"
for filename in sys.argv[1:]: #这个是指在命令行输入的东东
for line in open(filename):
for word in line.lower().split():
word = word.strip(strip)
if len(word) > 2:
if words[word] = words.get(word, 0) + 1
for word in sorted(words):
print("'{0}' occurs {1} times".format(word, words[word]))
文件的读与写
open(filename, encoding = 'utf8') #for reading text
open(filename, 'w', encoding = 'utf8') #for writing text
惯用方法:
for line in open(filename, encoding = 'utf8'):
process(line)
readlines()方法将整个文件读入字符串列表
字典内涵
{keyexpression:valueexpression for key, value in iterable}
{keyexpression:valueexpression for key, value in iterable if condtion}
file_sizes = {name: os.path.getsize(name) for name in os.listdir(".")}
file_sizes = {name: os.path.getsize(name) for name in os.listdir(".")
if os.path.isfile(name)}
inverted_d = {v: k for k, v in d.items()}#用于反转字典,但是对值有要求
3.3.3 默认字典
解释不清楚
import collections
words = collections.defaultdict(int)
3.3.4 有序字典
d = collections.OrderedDict([('z',-4), ('e', 19), ('k', 7)])
注意,如果括号里面传入的无序的dict,或关键字参数,那么顺序将是任意的(我在没看出来任意来)。
3.4 组合数据类型的迭代与复制
3.4.1 迭代子、迭代操作与函数 (查询有关迭代子的函数点这)
| 语法 | 描述 |
|---|---|
| s + t | 返回一个序列,该序列是序列s与t的连接 |
| s * n | 返回一个序列,该序列是序列s的n个副本的连接 |
| x in i | 如果项x出现在iterable i 中,就返回True,not in 进行的测试则相反 |
| all(i) | 如果iterable i 中的每一项都被评估为True,就返回True |
| any(i) | 如果iterable i中的任意项都被评估为True,就返回True |
| enumerate(i, start) | 通常用于for ... in 循环中,提供一个(index, item)元组序列,其中的索引起始值为0或start |
| len(x) | 返回x的“长度”,如果x是组合数据类型,那么返回的是其中数据项数;如果x是一个字符串,那么返回的是其中包含的字符数 |
| max(i,key) | 返回iterable i 中的最大的项,如果给定的是key函数,就返回key值最大的项 |
| min(i, key) | ... |
| range(start, stop, step) | 返回一个整数迭代子。使用一个参数(stop)时,迭代子的取值范围从0到stop-1;使用参数(start,stop)时,迭代子取值范围从start到stop-1;3个参数全部使用时,迭代范围从start到stop-1,但每俩个值之间间隔step |
| reversed(i) | 返回一个迭代子,该迭代子以反序从迭代子i中返回项#dict 不行 有序字典倒是可以 |
| sorted(i, key, reverse) | 以排序后顺序从迭代子i返回项,key用于提供DSU(修饰、排序、反修饰)排序,如果reverse为True,则排序以反序进行 |
| sum(i,start) | 返回iterable i 中项的和,加上start(默认为0),i 可以包含字符串 |
| zip(i1, ... ,iN | 返回元组的迭代子,使用迭代子i1到iN |
x = [-2, 9, 7, -4, 3]
all(x), any(x), len(x), min(x), max(x), sum(x)
#(True, True, 5, -4, 9, 13)
iter() and next()
iter() 将返回一个用于传递给函数的对象的迭代子,如果该对象无法进行迭代,则产生一个TypeError (还有另外一种用法,关于参数和哨点值,另外再说吧(P114)).
next()会依次返回每个相继的数据项,直到没有数据项时产生StopIteration异常。
product = 1
for i in [1, 2, 3, 4]:
product *= i
print(product)
与下面的是一样的:
product = 1
i = iter([1, 2, 3, 4])
while True:
try:
product *= next(i)
except StopIteration:
break
print(product)
实例:程序读入一个forename文件与一个surname文件,创建俩个列表,之后创建test-names1.txt并向其中写入100个随机的名称
import random
def get_fornames_and_surnames():
forenames = []
surnames = []
for names, filename in ((fornames, 'data/forenames.txt'),
(surnames, 'data/surnames.txt')):
for name in open(filename, encoding='utf8'):
names.append(name.rstrip()) #删除字符串末尾指定字符(默认为空格)
return forenames, surnames
forenames, surnames = get_fornames_and_surnames()
fh = open('test-names.txt', 'w', encoding='utf8')
for i in range(100):
line = "{0} {1}
".format(random.choice(forenames),
random.choice(surnames))
fh.write(line)
fh.close()
zip()
zip()会返回一个迭代子,每个元素是一个元组。
for t in zip(range(4), range(0, 10, 2), range(1, 10, 2)):
print(t)
#(0, 0, 1)
#(1, 2, 3)
#(2, 4, 5)
#(3, 6, 7)
#注意,即便传入的迭代子长度不一致,依然可以使用,取小。
for i in zip([1, 2], [1, 2, 3]):
print(i)
#(1, 1)
# (2, 2)
sorted() and reversed()
list(range(6)) #[0, 1, 2, 3, 4, 5]
list(reversed(range(6))) #[5, 4, 3, 2, 1, 0]
x = []
for t in zip(range(-10, 0, 1), range(0, 10, 2), range(1, 10, 2)):
x += t
x
#[-10, 0, 1, -9, 2, 3, -8, 4, 5, -7, 6, 7, -6, 8, 9]
sorted(x)
#[-10, -9, -8, -7, -6, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
sorted(x, reverse = True)
#[9, 8, 7, 6, 5, 4, 3, 2, 1, 0, -6, -7, -8, -9, -10]
sorted(x, key = abs)
#[0, 1, 2, 3, 4, 5, 6, -6, -7, 7, -8, 8, -9, 9, -10]
key关键字传入函数或方法,相当于先将x中的元素“修饰”,再对“修饰”后的元素加以排列得到一个序,最后的结果是x以这个序进行排列。
x = list(zip((1, 3, 1, 3), ('pram', 'dorie', 'kayak', 'canoe')))
print(x)
print(sorted(x))
def swap(t):
return t[1], t[0]
print(sorted(x, key=swap))
#[(1, 'pram'), (3, 'dorie'), (1, 'kayak'), (3, 'canoe')]
#[(1, 'kayak'), (1, 'pram'), (3, 'canoe'), (3, 'dorie')]
#[(3, 'canoe'), (3, 'dorie'), (1, 'kayak'), (1, 'pram')]
注意:sorted()只适用于可以进行相互比较的组合类型
sorted([1, '1')] #TypeError
不过,对于上面这种情况,有一个处理方法: key = int/float,当然这也只是对字符串为“数字”的特殊情形。
3.4.2 组合类型的复制
浅拷贝
a = [1, '2', 3]
b = a
a[1] = 'two'
a, b #([1, 'two', 3], [1, 'two', 3])
a = [1, ['2', 5], 3]
b = a[:]
a[0] = 2
b[1][0] = 'two'
a, b #([2, ['two', 5], 3], [1, ['two', 5], 3])
普通的 a=b,只是使用了对象引用,a, b指向了同一个内存对象
.copy()
dict()
list()
set()
a[:]
这些都会返回一个浅拷贝
深拷贝
a = [1, ['2', 5], 3]
b = copy.deepcopy(a)
a[0] = 2
b[1][0] = 'two'
a, b #([2, ['2', 5], 3], [1, ['two', 5], 3])
实例
生成用户名
import collections
import string
import sys
#在python中全大写的变量一般为常量,这是个约定
ID = 0
FORENAME = 1
MIDDLENAME = 2
SURNAME = 3
#命名元组
User = collections.namedtuple('User', 'username forename middlename surname id')
def Main():
if len(sys.argv) == 1 or sys.argv[1] in ('-h', '-help'):
print('useage: {0} file1 [file2 [... fileN]]'.format(
sys.argv[0]))
sys.exit()
usernames = set()
users = {}
for filename in sys.argv[1:]:
for line in open(filename, encoding='utf8'):
line = line.rstrip()
if line:
user = process_line(line, usernames)
users[(user.username.lower(),
user.forename.lower(),
user.id)] = user
print_users(users)
def process_line(line, usernames):
fields = line.split(':')
username = generate_username(fields, usernames)
user = User(username, fields[FORENAME], fields[MIDDLENAME],
fields[SURNAME], fields[ID])
return user
def generate_username(fields, usernames):
username = (fields[FORENAME][0] + fields[MIDDLENAME][:1] +
fields[SURNAME]).replace('-', '').replace("'", "")
username = original_name = username[:8].lower()
count = 1
while username in usernames:
username = "{0}{1}".format(original_name, count)
count += 1
usernames.add(username)
return username
def print_users(users):
namewidth = 32
usernamewidth = 9
print("{0:<{nw}} {1:^6} {2:{uw}}".format(
'Name', 'ID', 'Username', nw = namewidth, uw = usernamewidth))
print("{0:-<{nw}} {0:-<6} {0:-<{uw}}".format(
'', nw=namewidth, uw=usernamewidth))
for key in sorted(users):
user = users[key]
inital = ''
if user.middlename:
inital = ' ' + user.middlename[0]
name = "{0.surname}, {0.forename}{1}".format(user, inital)
print("{0:.<{nw}} {1.id:4} {1.username:{uw}}".format(
name, user, nw = namewidth, uw = usernamewidth))
if __name__ == '__main__':
Main()
输入是这样的:

输出是这样的:

小惊喜 m[:1]来代替m[0] 防止产生IndexError
s = ''
s[0] #报错
s[:1]#不会报错s[:k]都不会报错,只是s[:1]在s非空的情况下满足取首项的要求
处理统计信息
import collections
import string
import sys
import math
Statistics = collections.namedtuple('Statistic',
'mean mode median std_dev')
def main():
if len(sys.argv) == 1 or sys.argv[1] in {'-h', '-help'}:
print('usage: {0} file1 [file2 [... fileN]'.format(
sys.argv[0]))
sys.exit()
numbers = []
frequencies = collections.defaultdict(int)
for filename in sys.argv[1:]:
read_data(filename, numbers, frequencies)
if numbers:
statistics = calculate_statistics(numbers, frequencies)
print_results(len(numbers), statistics)
else:
print('no numbers found')
def read_data(filename, numbers, frequencies):
for lino, line in enumerate(open(filename, encoding='utf8'),
start = 1):
for x in line.split():
try:
number = float(x)
numbers.append(number)
frequencies[number] += 1
except ValueError as err:
print('{filename}:{lino}:skipping {x}:{err}'.format(
**locals()))
def calculate_statistics(numbers, frequencies):
mean = sum(numbers) / len(numbers)
mode = calculate_mode(frequencies, 3)
median = calculate_median(numbers)
std_dev = calculate_std_dev(numbers, mean)
return Statistics(mean, mode, median, std_dev)
def calculate_mode(frequencies, maximum_modes):
highest_frequency = max(frequencies.values())
mode = [number for number, frequency in frequencies.items()
if frequency == highest_frequency]
if not (1 <= len(mode) <= maximum_modes):
mode = None
else:
mode.sort()
return mode
def calculate_median(numbers):
numbers = sorted(numbers)
middle = len(numbers) // 2
median = numbers[middle]
if len(numbers) %2 == 0:
median = (median + numbers[middle - 1]) / 2
return median
def calculate_std_dev(numbers, mean):
total = 0
for number in numbers:
total += (number - mean) **2
variance = total / (len(numbers) - 1)
return math.sqrt(variance)
def print_results(count, statistics):
real = '9.2f'
if statistics.mode is None:
modeline = ''
elif len(statistics.mode) == 1:
modeline = 'mode = {0:{fmt}}
'.format(
statistics.mode[0], fmt=real)
else:
modeline = ("mode = ["+
",".join(["{0:.2f}".format(m)
for m in statistics.mode]) + "]
")
print("""
count = {0:6}
mean = {mean:{fmt}}
median = {median:{fmt}}
{1}
std.dev. = {std_dev:{fmt}}""".format(
count, modeline, fmt=real, **statistics._asdict()))
if __name__ == '__main__':
main()
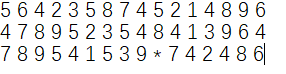
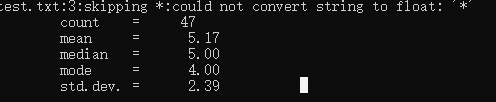
小惊喜 print 三引号
上面的例子中出现了三引号,三引号使得程序以我们所可理解的方式展示文本(大概就是不用加 之类的)。
print("""
aaaaa
ddddd
""")
aaaaa
ddddd
print("""
aaaaa
ddddd
""")
aaaaa ddddd
注意这个时候 可以起到把空行转义掉,回到原来的形状。
print("""
aaaaa
ddddd
""")
aaaaa
ddddd