和BufferedReader一样,BufferedWriter大部分情况下也是用来包装FileWriter、OutputStreamWriter、StreamEncoder这三个流以提高实用性的。
按照惯例,先看属性域:
private Writer out; private char cb[]; private int nChars, nextChar; private static int defaultCharBufferSize = 8192; /** * Line separator string. This is the value of the line.separator * property at the moment that the stream was created. */ private String lineSeparator;
首先out还是一样,是被包装的输出流,cb[]自然是字符缓冲区,nChars和nextChar作用也和BufferedReader中的大同小异,defaultCharBufferSize是默认缓冲区大小常量,唯一和BufferedReader有区别的是这个lineSeparator,看英文说明是定义了一个换行符,这个换号符在流被创建时被定义。
接下来是构造方法:
/** * Creates a buffered character-output stream that uses a default-sized * output buffer. * * @param out A Writer */ public BufferedWriter(Writer out) { this(out, defaultCharBufferSize); } /** * Creates a new buffered character-output stream that uses an output * buffer of the given size. * * @param out A Writer * @param sz Output-buffer size, a positive integer * * @exception IllegalArgumentException If {@code sz <= 0} */ public BufferedWriter(Writer out, int sz) { super(out); if (sz <= 0) throw new IllegalArgumentException("Buffer size <= 0"); this.out = out; cb = new char[sz]; nChars = sz; nextChar = 0; lineSeparator = java.security.AccessController.doPrivileged( new sun.security.action.GetPropertyAction("line.separator")); }
第一个构造方法就是根据默认缓冲区大小创建BufferedWriter流,第二个构造方法就是根据指定的缓冲区大小创建BufferedReader流(其实上面这个构造方法就是引用了下面这个构造方法,只不过sz设置成了defaultCharBufferSize)最后这一句应该就是对换行符的定义。
最后是一些方法:
BufferWriter的方法,相对来说比较简单粗暴
public void write(int c) throws IOException { synchronized (lock) { ensureOpen(); //字符缓冲区已满 if (nextChar >= nChars) flushBuffer(); cb[nextChar++] = (char) c; } }
这个方法就是简单的写一个字符到字符缓冲区中,如果字符缓冲区已满,就调用flushBuffer()
flishBuffer():
void flushBuffer() throws IOException { synchronized (lock) { ensureOpen(); if (nextChar == 0) return; out.write(cb, 0, nextChar); nextChar = 0; } }
调用被包装流的write方法,把字符缓冲区内当前0-nextChar的内容全部输出,然后让nextChar=0,准备接受下一轮输出。
public void write(char cbuf[], int off, int len) throws IOException { synchronized (lock) { ensureOpen(); if ((off < 0) || (off > cbuf.length) || (len < 0) || ((off + len) > cbuf.length) || ((off + len) < 0)) { throw new IndexOutOfBoundsException(); } else if (len == 0) { return; } if (len >= nChars) { /* If the request length exceeds the size of the output buffer, flush the buffer and then write the data directly. In this way buffered streams will cascade harmlessly. */ flushBuffer(); out.write(cbuf, off, len); return; } int b = off, t = off + len; while (b < t) { int d = min(nChars - nextChar, t - b); System.arraycopy(cbuf, b, cb, nextChar, d); b += d; nextChar += d; if (nextChar >= nChars) flushBuffer(); } } }
这个方法是将一个数组的部分内容写入字符缓冲区,此时如果要写入的字符的长度大于其自身缓冲区的长度,那就将自己缓冲区里已有的内容和此时要写入字符缓冲区的内容全部直接调用被包装流(本质是StreamEncoder流)的write(cbuf[],off,len)方法,解码写入被包装流的字节缓冲区,若溢出则直接输出。(即不使用类自己的缓冲区了);否则就直接往类自己的缓冲区里写,这里还是用一个流程图进行详细说明:
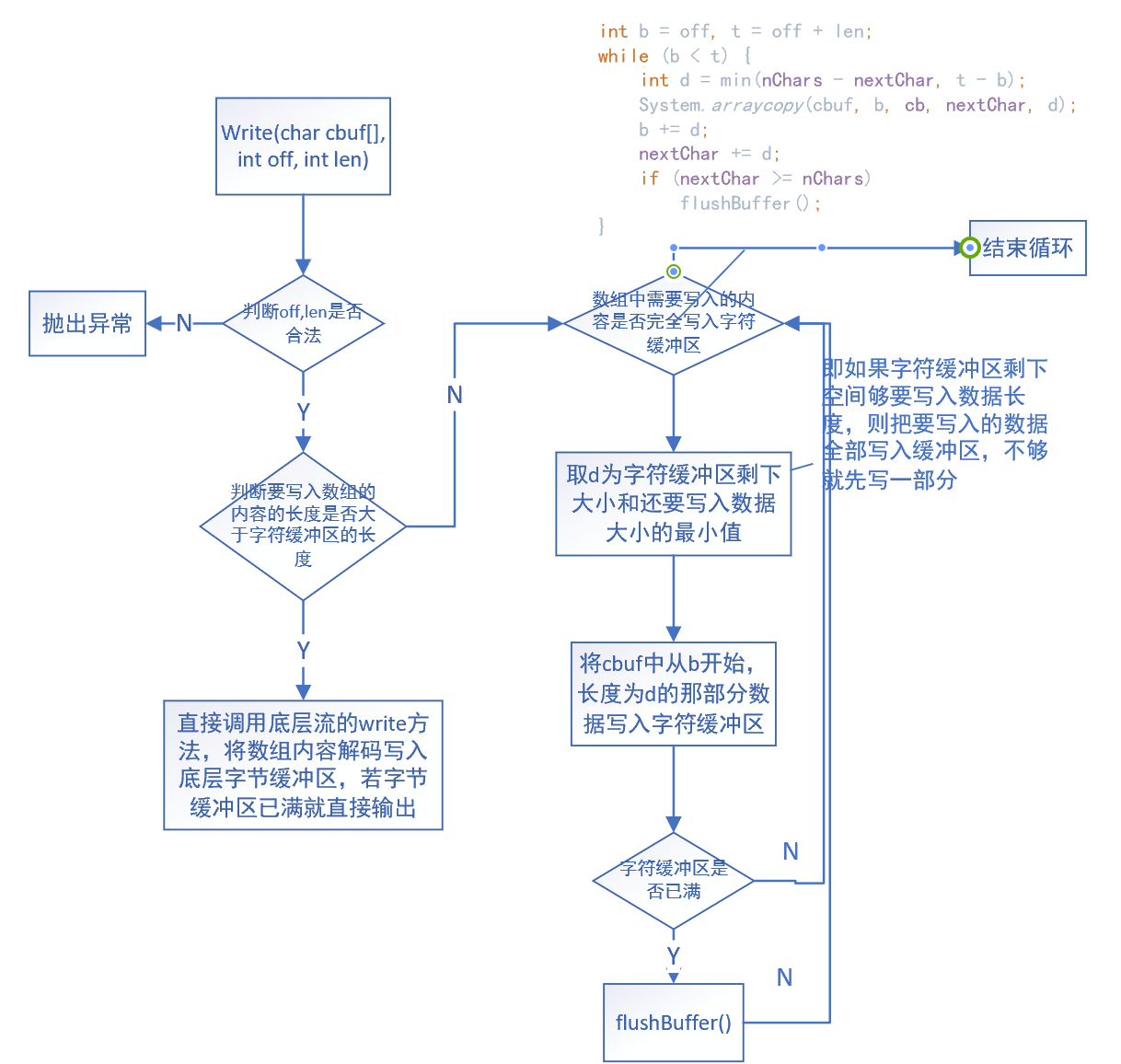
然后是一个写字符串的方法:
public void write(String s, int off, int len) throws IOException { synchronized (lock) { ensureOpen(); int b = off, t = off + len; while (b < t) { int d = min(nChars - nextChar, t - b); s.getChars(b, b + d, cb, nextChar); b += d; nextChar += d; if (nextChar >= nChars) flushBuffer(); } } }
和上面写字符数组的无大区别,这里不再赘述。
public void close() throws IOException { synchronized (lock) { if (out == null) { return; } try (Writer w = out) { flushBuffer(); } finally { out = null; cb = null; } } }
最后也是最重要的方法,和其他write流一样,如果在结束时不调用这个方法,则有一部分数据会留在缓冲区中,不会输出到计算机。try-finally是保证该语句必定被执行。