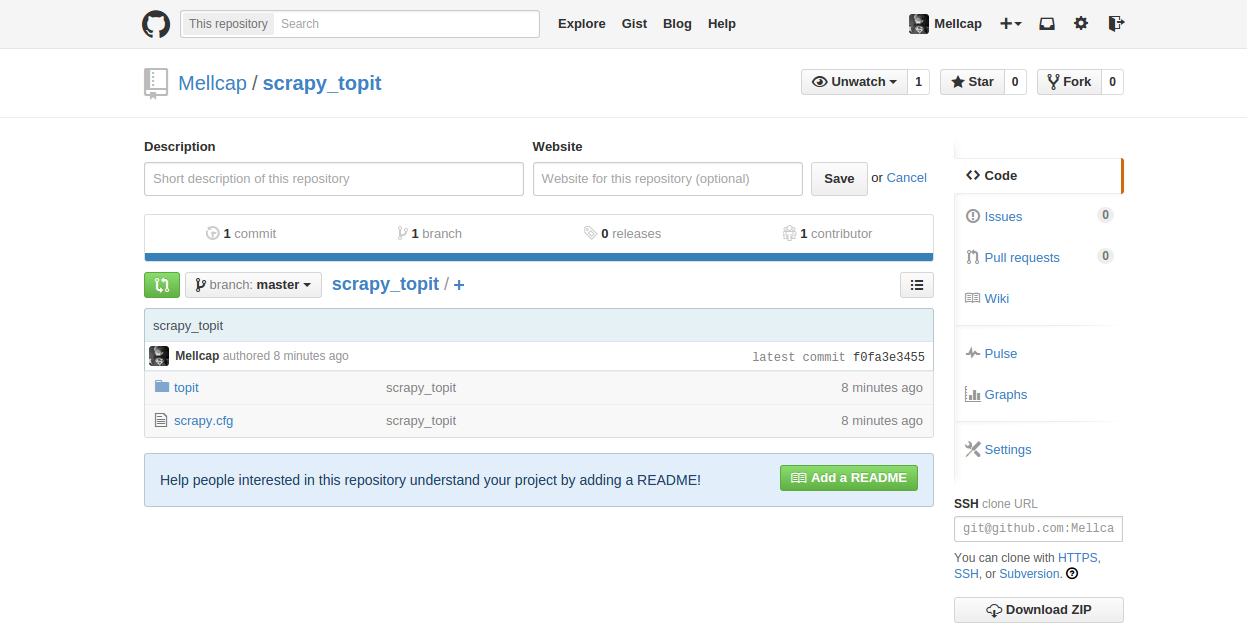
接触了scrapy ,发现爬虫效率高了许多,借鉴大神们的文章,做了一个爬虫练练手:
我的环境是:Ubuntu14.04 + python 2.7 + scrapy 0.24
目标 topit.me
一、创建project
1 scrapy startproject topit
二、定义Item
import scrapy class TopitItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() url = scrapy.Field()
三、在spider 文件夹中创建 topit_spider.py
# -*- coding: utf-8 -*- #!/usr/bin/env python #File name :topit_spider.py #Author:Mellcap from scrapy.contrib.spiders import CrawlSpider,Rule from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from topit.items import TopitItem import re from scrapy.http import Request from scrapy.selector import Selector class TopitSpider(CrawlSpider): name = "topit" allowed_domains = ["topit.me"] start_urls=["http://www.topit.me/"] rules = (Rule(SgmlLinkExtractor(allow=('/item/d*')), callback = 'parse_img', follow=True),) def parse_img(self, response): urlItem = TopitItem() sel = Selector(response) for divs in sel.xpath('//a[@rel="lightbox"]'): img_url=divs.xpath('.//img/@src').extract()[0] urlItem['url'] = img_url yield urlItem
四、定义pipelines
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html from topit.items import TopitItem class TopitPipeline(object): def __init__(self): self.mfile = open('test_topit.html', 'w') def process_item(self, item, spider): text = '<img src="' + item['url'] + '" alt = "" />' self.mfile.writelines(text) def close_spider(self, spider): self.mfile.close()
五、设置一下 setting.py
在后面加入一行:
ITEM_PIPELINES={'topit.pipelines.TopitPipeline': 1,}
保存后就大功告成了/
接着打开终端
运行:
cd topit
scrapy crawl topit
然后会在topit文件夹中发现test_topit 文件
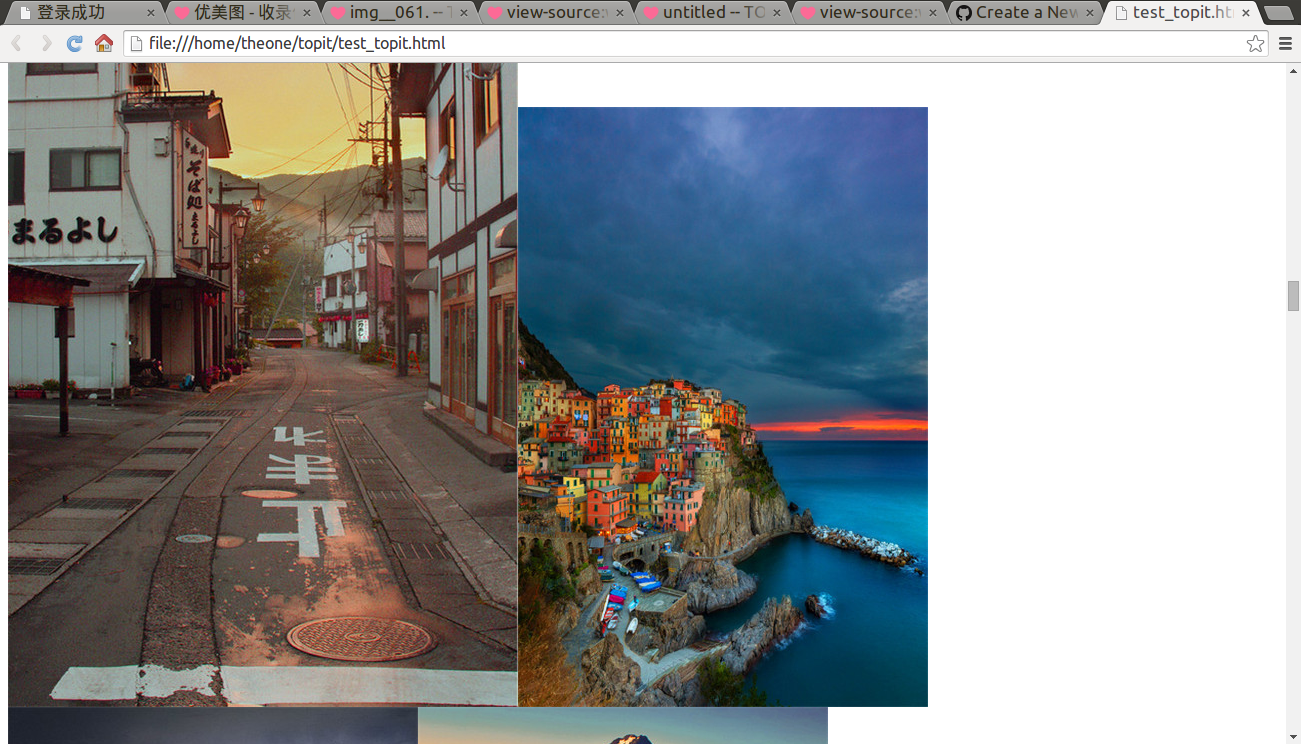
打开之后在浏览器就可以看到图片了
接下来传到Github上:
爬虫已经做好了,在远程建立一个空库
一、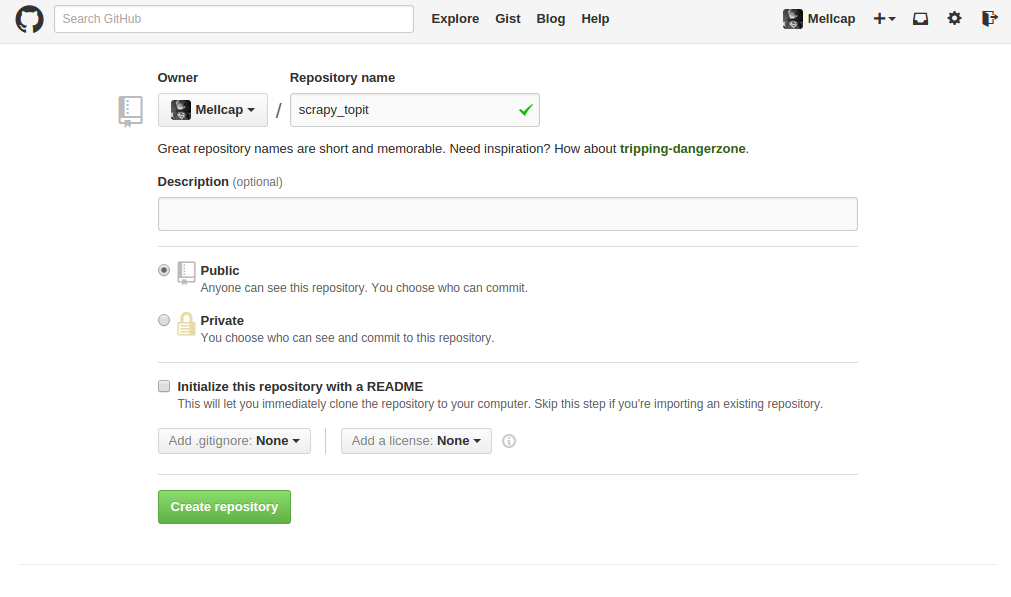
二、在本地建立版本库
theone@Mellcap:~$ cd topit theone@Mellcap:~/topit$ git init 初始化空的 Git 版本库于 /home/theone/topit/.git/ theone@Mellcap:~/topit$ git status 位于分支 master 初始提交 未跟踪的文件: (使用 "git add <file>..." 以包含要提交的内容) scrapy.cfg test_topit.html topit/ 提交为空,但是存在尚未跟踪的文件(使用 "git add" 建立跟踪) theone@Mellcap:~/topit$ git add scrapy.cfg theone@Mellcap:~/topit$ git add topit/ theone@Mellcap:~/topit$ git commit -m'scrapy_topit'
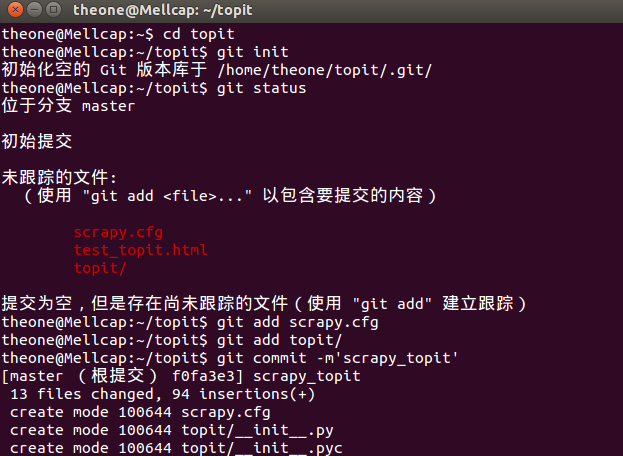
三、跟远程库建立连接
theone@Mellcap:~/topit$ git remote add origin git@github.com:Mellcap/scrapy_topit.git
theone@Mellcap:~/topit$ git push -u origin master
四、完成
在github上看到了自己的爬虫了。