
复习
异常处理
try except 一定要在except之后写一些提示或者处理的内容
try:
'''可能会出现异常的代码'''
except ValueError:
'''打印一些提示或者处理的内容'''
except NameError:
'''...'''
# except Exception as e:
# '''打印e'''
else:
'''try中的代码正常执行了'''
finally:
'''无论错误是否发生,都会执行这段代码,用来做一些收尾工作'''
二、正则表达式
1,正则表达式用来对字符串进行操作
2,使用一些规则来检测来检测字符串是否符合我的要求————表单验证
3,从一段字符串中找出符合我要求分内容————爬虫
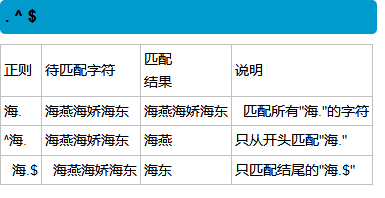
完全相等的字符串都可以匹配上
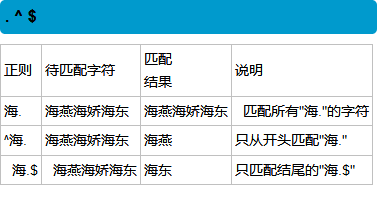
字符组:字符组代表一个字符位置上可以出现的所有内容
范围:
根据asc码来的,范围必须是从大到小的指向
一个字符组中可以有多个范围



转义符

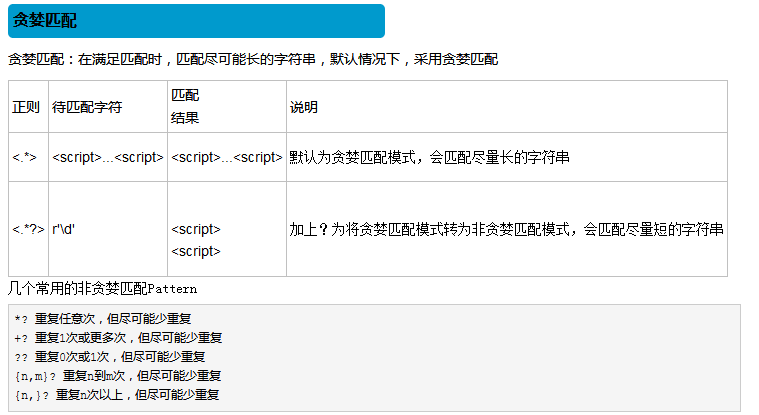
身份证号码第一个长度为15或18个字符的字符串,首位不能为0
如果是15位则全部为数字组成
如果是18位则前十七位全部是数字,末位可能是数字或X
[1-9]d{16}[dx]|[1-9]d{14} 或
如果两个正则表达式之间用‘或’连接,且有一部分正则规则相同,那么一定把规则长的放在前面
[1-9]d{14}(d{2}[dx])?
如果对一组正则表达式整体有一个量词约束,就将这组表达式分成一个组在组外进行量词约束
三、re模块
import re
ret = re.findall('a','eav,and,apple')
print(ret) #['a', 'a', 'a']
findall接收两个参数 : 正则表达式 要匹配的字符串
一个列表数据类型的返回值:所有和这条正则匹配的结果
如果没有,返回[]
import re
ret = re.search('a', 'eva egon yuan')
print(ret.group()) #a
search和findall的区别:
1.search找到一个就返回,findall是找所有
2.findall是直接返回一个结果的列表,search返回一个对象
import re
ret = re.match('a', 'eva egon yuan')
if ret:
print(ret.group()) #None
match
·1 意味着在正则表达式中添加了一个^
·2 和search一样 匹配返回结果对象 没匹配到返回None
·3 和search一样 从结果中获取值 仍然用group
import re
ret = re.sub('d', 'H', 'eva3egon4yuan4',2)
print(ret) #evaHegonHyuan4 将数字替换成'H',参数2表示只替换2个
import re
ret = re.subn('d', 'H', 'eva3egon4yuan4')
print(ret) #('evaHegonHyuanH',3)#将数字替换成'H',返回元组(替换的结果,替换了多少次)
import re
obj = re.compile('d{3}') # 编译 在多次执行同一条正则规则的时候才适用
ret1 = obj.search('abc123eeee')
ret2 = obj.findall('abc123eeee')
print(ret1.group())
print(ret2)
正则表达式 -->根据规则匹配字符串
从一个字符串中找到符合规则的字符串 --> python
正则规则 -编译-> python能理解的语言
多次执行,就需要多次编译 浪费时间 re.findall('1[3-9]d{9}',line)
编译 re.compile('d{3}')
import re
ret = re.finditer('d', 'ds3sy4784a') #finditer适用于结果比较多的情况下,能够有效的节省内存
print(ret) # <callable_iterator object at 0x10195f940> finditer返回一个存放匹配结果的迭代器
print(ret.__next__().group()) 查看第一个结果
print(next(ret).group()) 查看第二个结果
for i in ret:
print(i.group())
当分组遇到re模块
import re
ret1 = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.baidu.com')
print(ret1) ['oldboy']
print(ret2) ['www.baidu.com']
findall会优先显示组内匹配到的内容,如果想取消分组优先效果,在组内开始的时候加上?:
ret=re.split("d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中,
如果将匹配的正则放到组内,就会将分隔符放到结果列表里
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
分组命名 和 search遇到分组
标签 .html 网页文件 标签文件
import re
分组的意义
1.对一组正则规则进行量词约束
2.从一整条正则规则匹配的结果中优先显示组内的内容
"<h1>hello</h1>"
ret = re.findall('<w+>(w+)</w+>',"<h1>hello</h1>")
print(ret)
分组命名
ret = re.search("<(?P<tag>w+)>(?P<content>w+)</(?P=tag)>","<h1>hello</h1>")
print(ret)
print(ret.group()) # search中没有分组优先的概念
print(ret.group('tag'))
print(ret.group('content'))
ret = re.search(r"<(w+)>(w+)</1>","<h1>hello</h1>")
#如果不给组起名字,也可以用序号来找到对应的组,表示要找的内容和前面的组内容一致
#获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group())
print(ret.group(0)) #结果 :<h1>hello</h1>
print(ret.group(1)) #结果 :h1
print(ret.group(2)) #结果 :hello