一.概述
前面章节介绍了很多数据库的优化措施,但在实际生产环境中,由于数据库服务器本身的性能局限,就必须要对前台的应用来进行优化,使得前台访问数据库的压力能够减到最小。
1. 使用连接池
对于访问数据库来说,建立连接的代价比较昂贵,因为连接到数据库服务器需要经历多个步骤如:建立物理通道,服务器进行初次握手,分析连接字符串信息,由服务器对连接进行身份验证等。因此,有必要建立"连接池"以提高访问的性能。连接池中的连接已经预先创建好了,可以直接分配给应用层使用,减少了创建新连接所消耗的资源,连接返回后,本次访问将连接交还给"连接池",以供新的访问使用。
(1)如果池中有空闲连接可用,返回该连接。
(2)如果池中连接都已用完,创建一个新连接添加到池中。
(3)如果池中连接已达到最大连接数,请求进入等待队列直到有空闲连接可用。
//下面以ado.net 连接数据库为例: //引用 System.Data.SqlClient //可以使用字符串connectionString来实例化SqlConnection对象 string connectionString ="Integrated Security=False;server={0};database={1};User ID={2};Password={3};Max Pool Size=512;Connect Timeout=30"; //也可以使用SqlConnectionStringBuilder类来实例化SqlConnection对象 SqlConnectionStringBuilder sqlconnStringBuilder = new SqlConnectionStringBuilder(); //连接池是否默认打开 默认为true sqlconnStringBuilder.Pooling = true; //连接池中最大连接数 sqlconnStringBuilder.MaxPoolSize = 512; //连接请求等待超时时间。默认为15秒,单位为秒。 sqlconnStringBuilder.ConnectTimeout = 30; sqlconnStringBuilder.DataSource = ""; sqlconnStringBuilder.UserID = ""; sqlconnStringBuilder.Password = ""; //使用用户名和密码连接 sqlconnStringBuilder.IntegratedSecurity = false; SqlConnection sql = new SqlConnection(connectionString); //or sql = new SqlConnection(sqlconnStringBuilder.ConnectionString); //用完后记得关闭当前连接 sql.Close(); //使用mysql一样 引用MySql.Data.dll MySql.Data.MySqlClient.MySqlConnection mysqlconn = new MySql.Data.MySqlClient.MySqlConnection(); MySql.Data.MySqlClient.MySqlConnectionStringBuilder mysqlconnStringBuilder = new MySql.Data.MySqlClient.MySqlConnectionStringBuilder();
2.使用查询缓存
mysql的查询缓存在4.1版本以后新增的功能,它的作用是存储select 查询的文本以及相应结果。如果随后收到一个相同的查询,服务器会从查询缓存中重新得到查询结果,而不再需要解析和执行查询。查询缓存的适用对象是更新不频繁的表,当表更改(表结构和表数据)后,查询缓存值的相关条目被清空。
-- 查询缓存相关的参数 SHOW VARIABLES LIKE '%query_cache%';
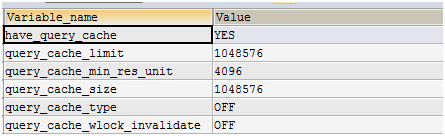
参数解释:
|
have_query_cache |
表示这个mysql版本是否支持查询缓存。 |
|
query_cache_limit |
表示单个结果集所被允许缓存的最大值。 1048576.0/1024.0/1024.0=1.0M 默认1M,超过空间大小不被缓存。 |
|
query_cache_min_res_unit |
每个被缓存的结果集要占用的最小内存。 |
|
query_cache_size |
用于查询缓存的内存总大小。 1048576.0/1024.0/1024.0=1.0M 默认1M,超过空间大小不被缓存。 |
|
query_cache_type |
默认关闭缓存 |
|
query_cache_wlock_invalidate |
控制当有写锁加在表上的时候,是否先让该表相关的 Query Cache失效。 OFF: 是指在锁定时刻仍然允许读取该表相关的 Query Cache。 ON: 写锁定的同时将使该表相关的所有 Query Cache 失效。 |
-- 监视查询缓存的使用状况 SHOW STATUS LIKE 'Qcache%'
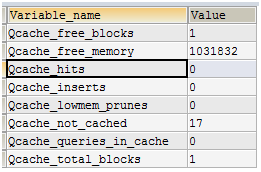
参数解释:
|
Qcache_free_memory |
查询缓存目前剩余空间大小。 |
|
Qcache_hits |
查询缓存的命中次数。 |
|
Qcache_inserts |
查询缓存插入的次数 |
|
Qcache_free_blocks |
目前还有多少剩余的blocks。FLUSH QUERY CACHE 会对缓存中的碎片进行整理,从而得到一个空闲块。这个值比较大,意味着内存碎片比较多 |
| Qcache_lowmem_prunes | 多少条Query 因为内存不足而被清除出Query Cache。缓存出现内存不足并且必须要进行清理,以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。 |
|
Qcache_not_cached |
不能被cache 的Query 的数量。不适合进行缓存查询的数量,通常是由于这些查询不是 SELECT 语句 |
|
Qcache_queries_in_cache |
当前Query Cache 中cache 的Query 数量. |
|
Qcache_total_blocks |
当前Query Cache 中的block 数量。 |
(查询缓存章节未完...)