伪分布式模式
启动HDFS并运行MapReduce程序
相关默认配置文件的页面:
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/core-default.xml
1、修改core-site.xml配置文件

<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
2、修改hadoop-env.sh配置文件的JAVA_HOME

3、修改hdfs-site.xml配置文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
注意:
此时该服务器上只有一份
如果保存三份,在把 本台服务器 上的数据自动进行备份到三台服务器上
取决于集群的节点的性能
注意:
如果此时配置为3,此时这台服务器保存几分数据
此时此台服务器存一份,挂掉了就挂掉了
此时会有集群
只要添加服务器就会进行备份
一台服务器备份三分也是比较浪费内存的
4、启动集群
a、格式化NameNode(第一次启动的时候进行格式化,之前就不要总进行格式化)
没做之前格式化从0格式化,格式化一次集群中的内容全部消失
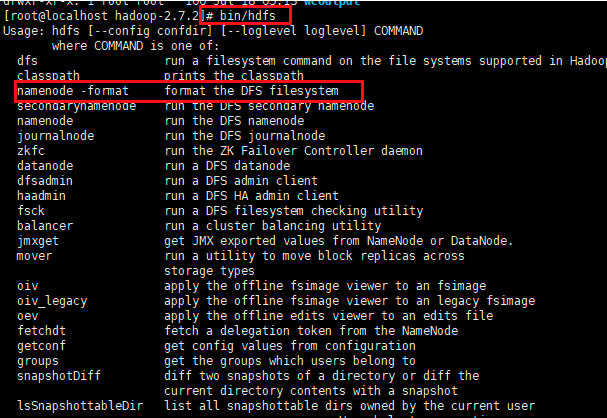
namenode -format 格式化集群系统
如果服务在运行,有新的数据到来会进行重新创建文件
首先需要进行关闭服务,在使用rm进行删除文件
否则进行格式化就会一直报错
如果在实行过程过出现错误就需要进行相关的数据日志的查询
命令:
bin/hdfs namenode -format
b、启动NameNode
hadoop-daemon.sh
启动hadoop的守护进程,可以启动hadoop的namenode和datenode
命令:
[root@localhost sbin]# hadoop-daemon.sh start namenode
[root@localhost sbin]# hadoop-daemon.sh start datanode
启动之后
[root@hadoop1 sbin]# hadoop-daemon.sh start namenode starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop1.out [root@hadoop1 sbin]# hadoop-daemon.sh start datanode starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop1.out
查看进程:使用jps
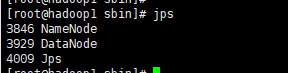
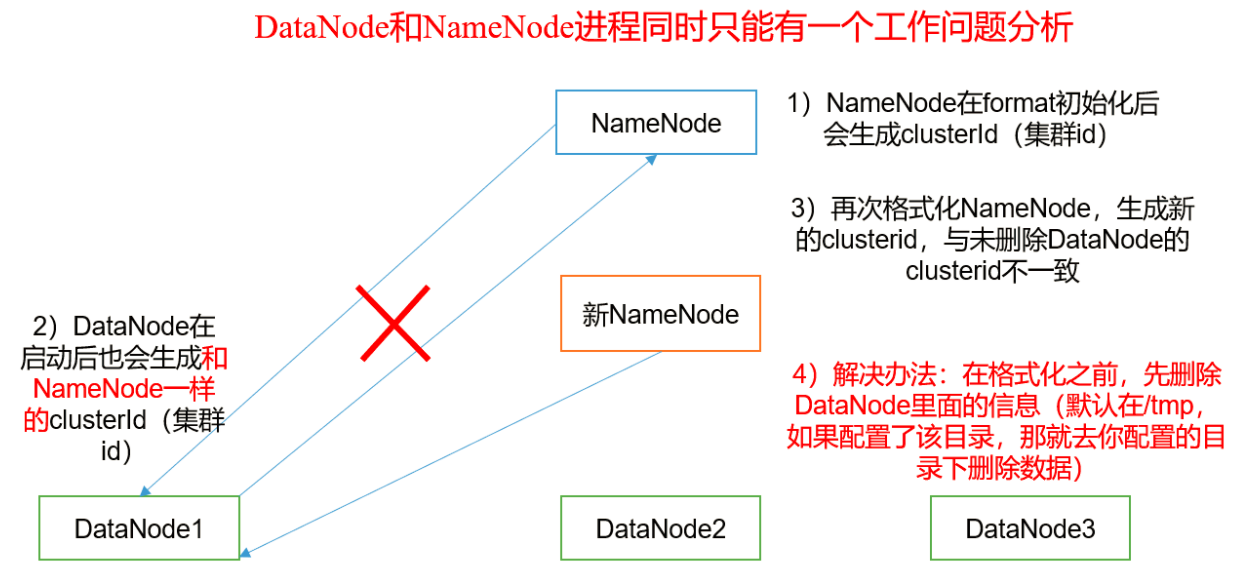
注意:为什么不能以自格式化NameNode?
NameNode
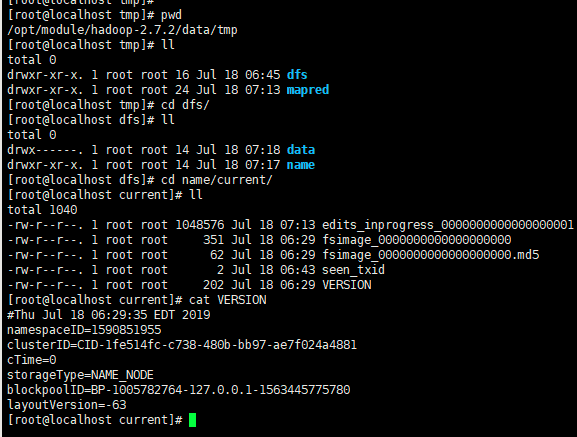
DateNode
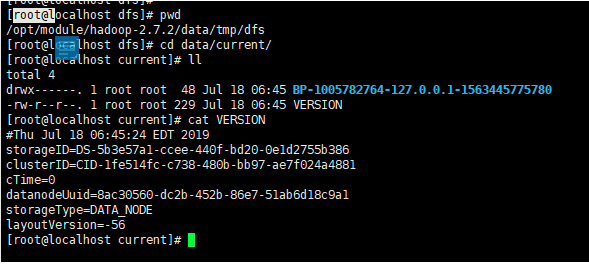
此时会发现clusterID一样
两个之间要进行相互通信
否则两者之间就会相互不能识别
启动之后就可以进行网页的查询
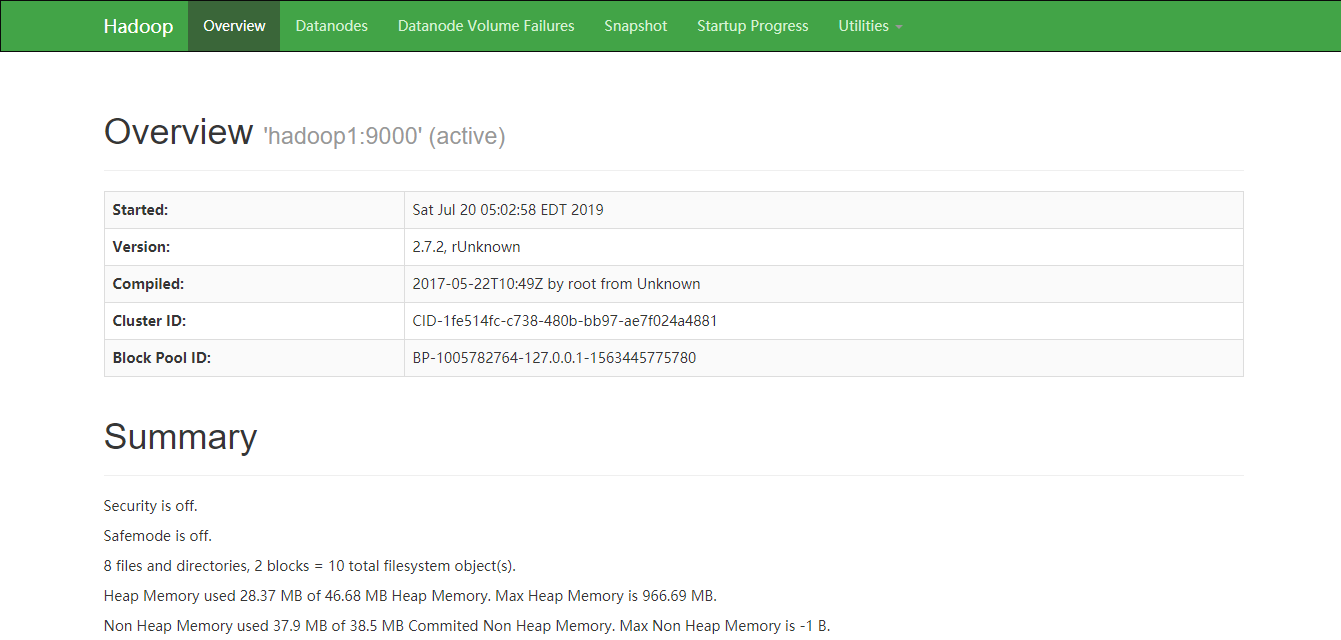
点击OVERVIEW超链接
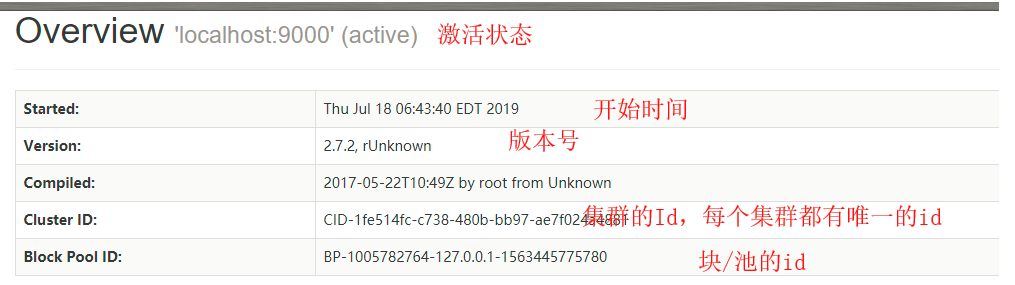
重点使用

命令进行创建目录
[root@localhost hadoop-2.7.2]# bin/hdfs dfs -mkdir -p /usr/hadoop101/input
此时可以进行目录的获取
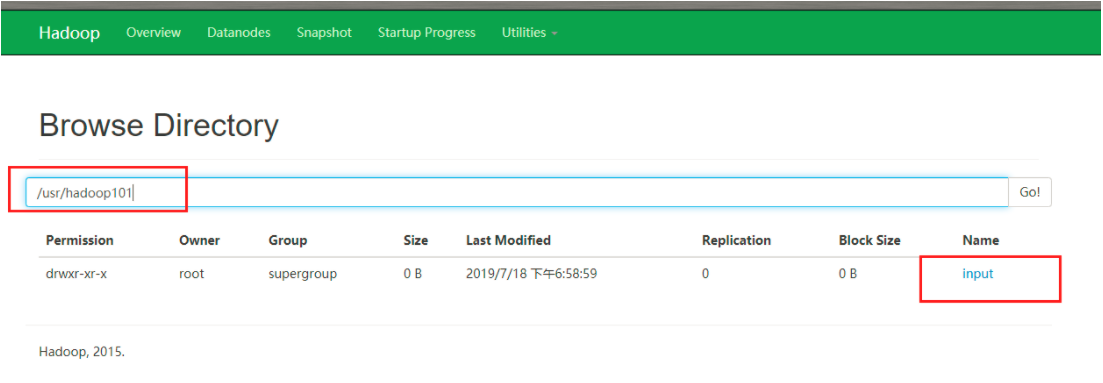
上传文件到hdfs上
bin/hdfs dfs -put wcinput/wc.input /usr/hadoop101/input
-put命令,将本地的什么文件 上传到那个路径
此时在进行刷新

Block Size :块的大小 存储上的上限值是128MB
Replication:副本数量(上述中在配置文件配置为1)
点击文件名
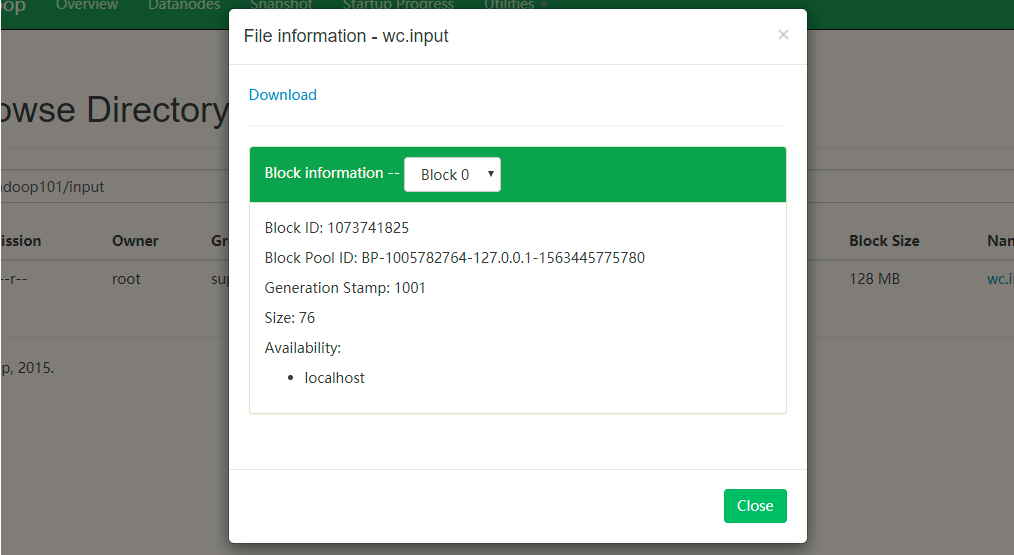
使用hadoop跑hdfs上的文件
命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /usr/hadoop101/input /usr/hadoop101/output
在网页上进行查看(进行下载)
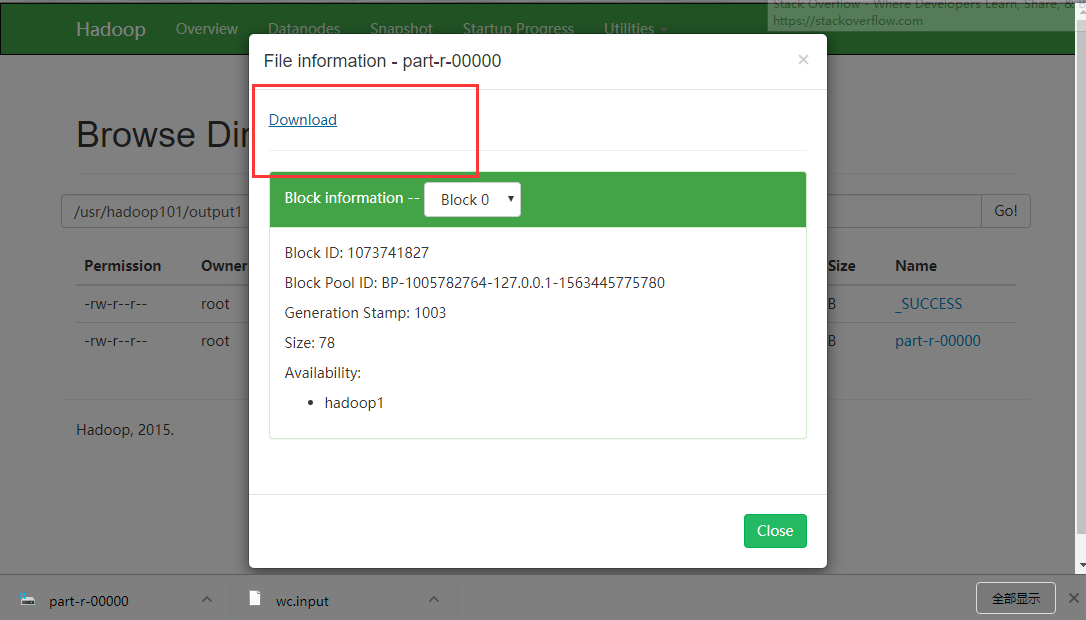
使用命令进行查看
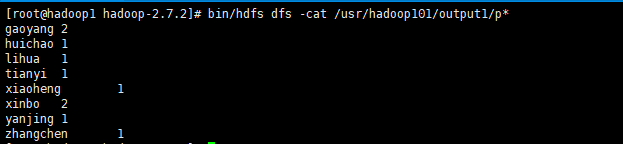
bin/hdfs dfs -cat /usr/hadoop101/output1/p*
启动YARN并且运行MapReduce程序
功能测试和性能测试
1、配置yarn-env.sh
进行配置环境变量


2、配置yarn-site.xml
<configuration> <!-- Reduce获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> </property>
<!-- 指定YARN的ResourceManager的地址 --> <!--指定resourceManager放在那个服务器上--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop1</value> </property> </configuration>
3、配置maperd-env.sh

4、配置mapred-site.xml
(对mapred-site.xml.template重新命名为) mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
修改配置文件
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
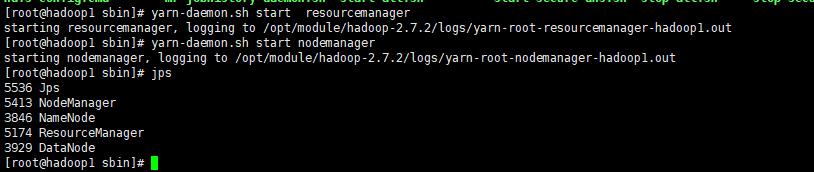
5、启动集群
启动前必须保证NameNode和DataNode已经启动
/opt/module/hadoop-2.7.2/sbin目录下

命令:
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
此时可以访问地址:
此时进行查询集群是否配置成功
http://hadoop1:8088/cluster
进行测试:删除hdfs中的目录文件夹

删除命令:
bin/hdfs dfs -rm -r /usr/hadoop101/output1
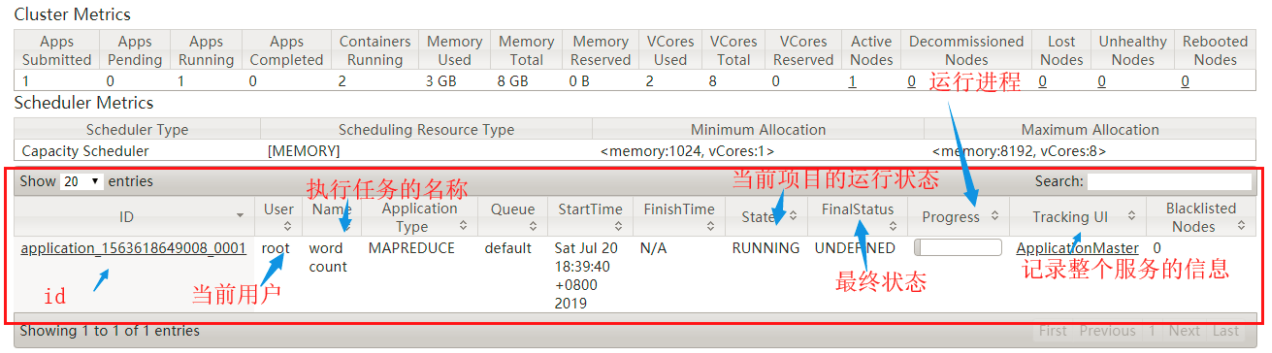
执行命令进行测试:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /usr/hadoop101/input /usrhadoop101/output
程序正在执行

同时查看后台的程序监控
配置历史服务器
1. 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
启动历史服务器:

使用mr-jobhistory-daemon.sh命令
执行命令:
[root@hadoop1 hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver
使用jps进行查看

此时进行网址:
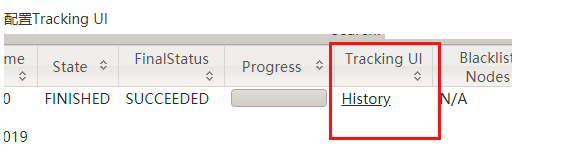
进行点击history
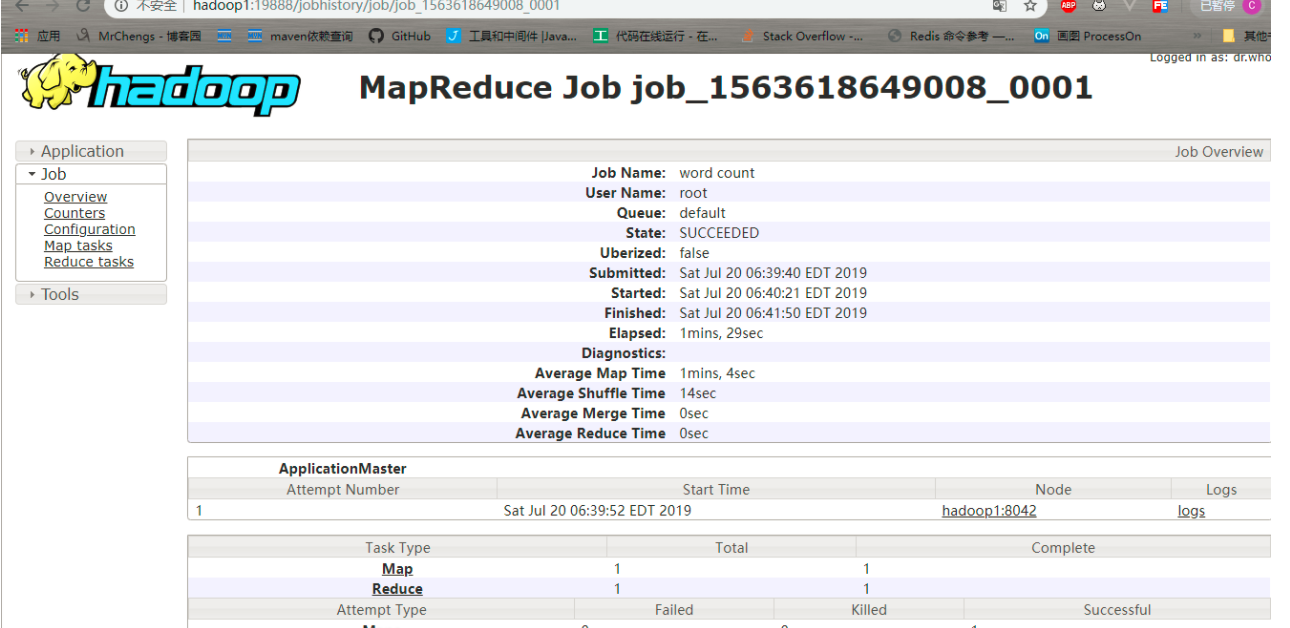
此时点击log
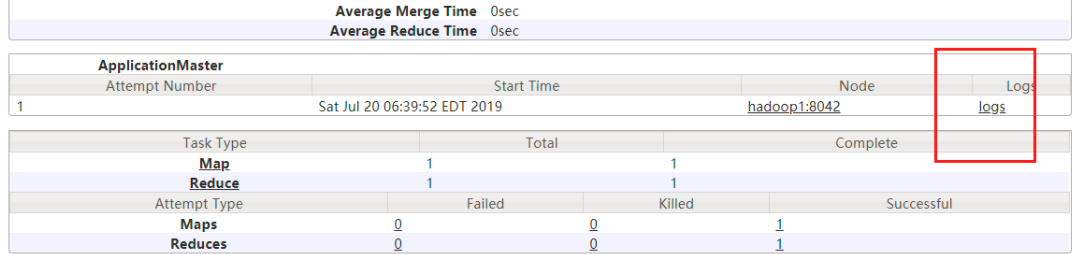
会出现:
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
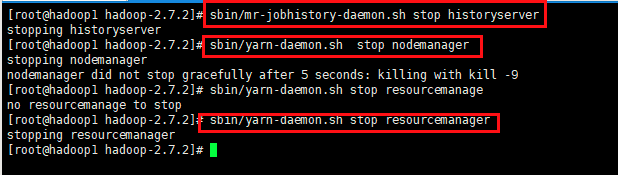
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager
1、进行关闭
2、配置yarn-site.xml
[root@hadoop1 hadoop-2.7.2]# cd etc/hadoop/
[root@hadoop1 hadoop]# vim yarn-site.xml
<configuration>
<!-- Reduce获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<!--指定resourceManager放在那个服务器上-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
3、进行启动NodeManager、ResouceManager、HistoryManager

4、删除HDFS上已经存在的输出文件
bin/hdfs dfs -rm -r /usrhadoop101/output
5、执行wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /usr/hadoop101/input /usr/hadoop101/output
此时观察就会有变化
http://hadoop1:8088/cluster
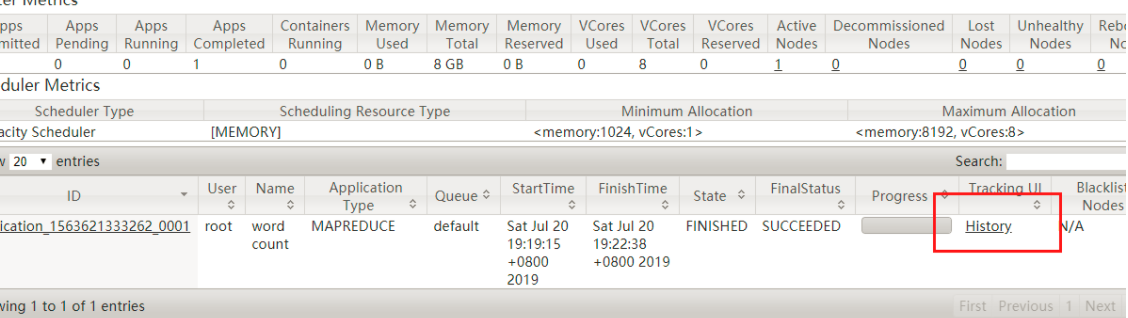
|
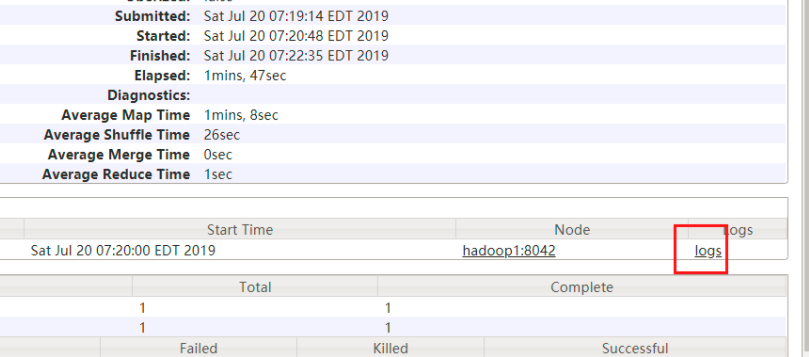
|
此时可以看到详细的日志信息

配置文件的说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件
只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件

(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。