问题描述:
给定一组字符,使用原地算法将其压缩。
压缩后的长度必须始终小于或等于原数组长度。
数组的每个元素应该是长度为1 的字符(不是 int 整数类型)。
在完成原地修改输入数组后,返回数组的新长度。
进阶:
你能否仅使用O(1) 空间解决问题?
示例 1:
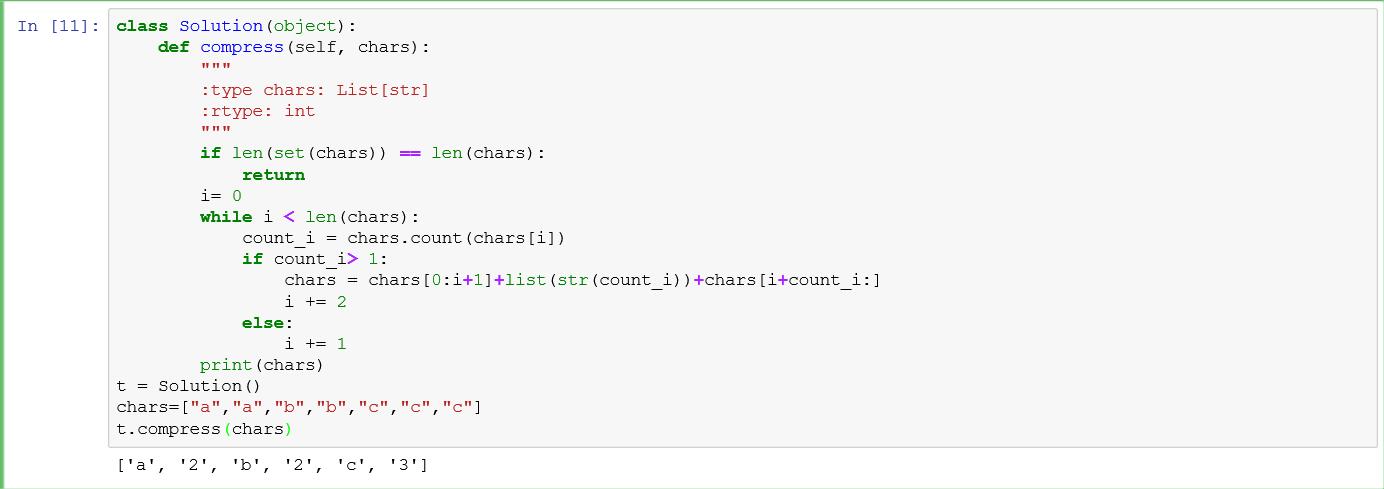
输入: ["a","a","b","b","c","c","c"] 输出: 返回6,输入数组的前6个字符应该是:["a","2","b","2","c","3"] 说明: "aa"被"a2"替代。"bb"被"b2"替代。"ccc"被"c3"替代。
示例 2:
输入: ["a"] 输出: 返回1,输入数组的前1个字符应该是:["a"] 说明: 没有任何字符串被替代。
示例 3:
输入: ["a","b","b","b","b","b","b","b","b","b","b","b","b"] 输出: 返回4,输入数组的前4个字符应该是:["a","b","1","2"]。 说明: 由于字符"a"不重复,所以不会被压缩。"bbbbbbbbbbbb"被“b12”替代。 注意每个数字在数组中都有它自己的位置。
注意:
- 所有字符都有一个ASCII值在
[35, 126]区间内。 1 <= len(chars) <= 1000。
方法:LeetCode编译器抽风了?为什么在jupyter上可以,在Lee就不行???
1 class Solution(object): 2 def compress(self, chars): 3 """ 4 :type chars: List[str] 5 :rtype: int 6 """ 7 if len(set(chars)) == len(chars): 8 return len(chars) 9 chars.sort() 10 i= 0 11 while i < len(chars): 12 count_i = chars.count(chars[i]) 13 if count_i> 1: 14 chars = chars[0:i+1]+list(str(count_i))+chars[i+count_i:] 15 i += 2 16 else: 17 i += 1 18 return len(chars)
官方:
1 class Solution: 2 def compress(self, chars): 3 """ 4 :type chars: List[str] 5 :rtype: int 6 """ 7 chars.append(chr(30)) 8 last=chars[0] 9 count,p=1,0 10 for i,c in enumerate(chars[1:]): 11 if c==last: 12 count+=1 13 else: 14 for j in last+(str(count) if count>1 else ''): 15 chars[p]=j 16 p+=1 17 count=1 18 last=c 19 return p
2018-10-04 20:20:34