Blog deployment design and construction | 博客部署设计和构建
Convert markdown note files to blogs, and automatically update blog information
将markdown笔记文件转为博客,且能够自动更新博客信息
博客可以用来记笔记或者发布文章,是一种信息载体,我们可以把一些信息放到博客,方便在网络环境查阅。
最近打算搭建个人博客,已知网络上的公共博客网站有博客园(国内),github(全球)都挺好用的,本人有在用,博客园和github也有挂的时候(访问不了),情况很少;
搭建博客能学习不少新知识,自定义功能,下面说说如何设计构建
GitHub源码地址: Selfpublog
功能已经写好可以访问 narule.net/blog 查看效果
created html:
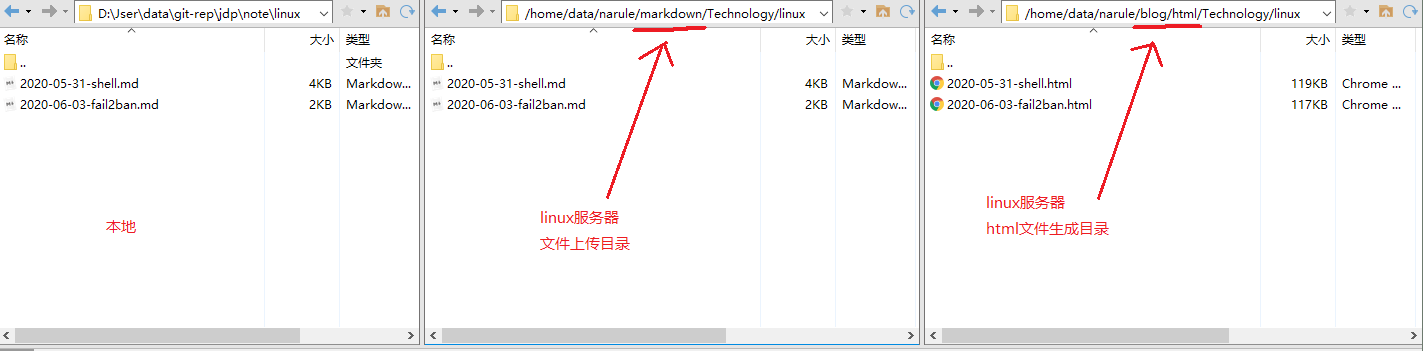
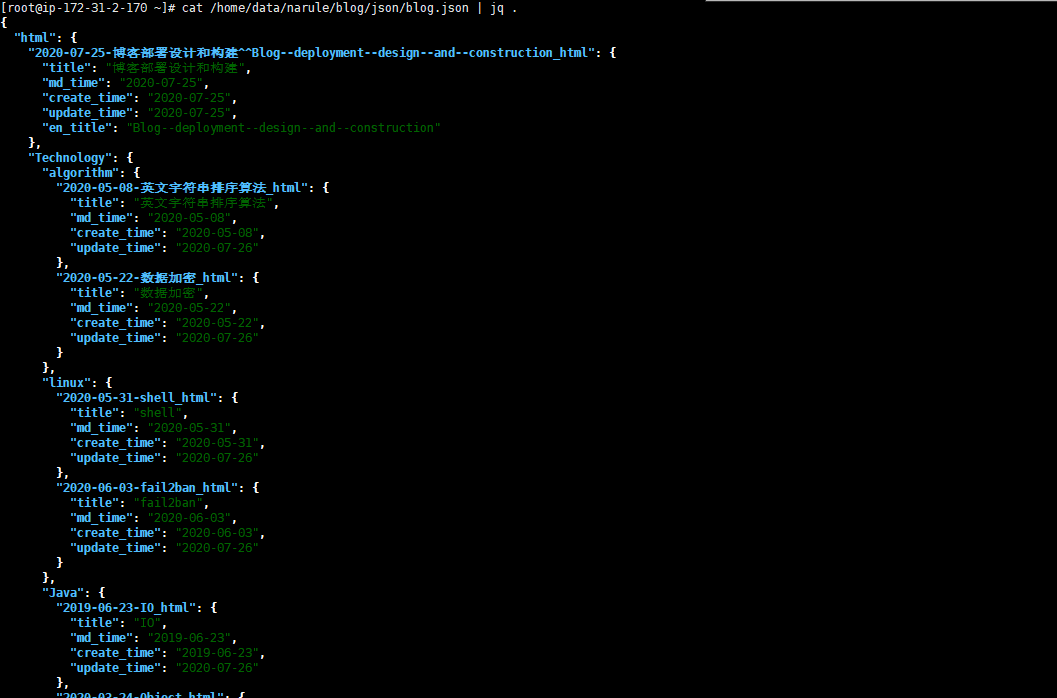
created blog json info:
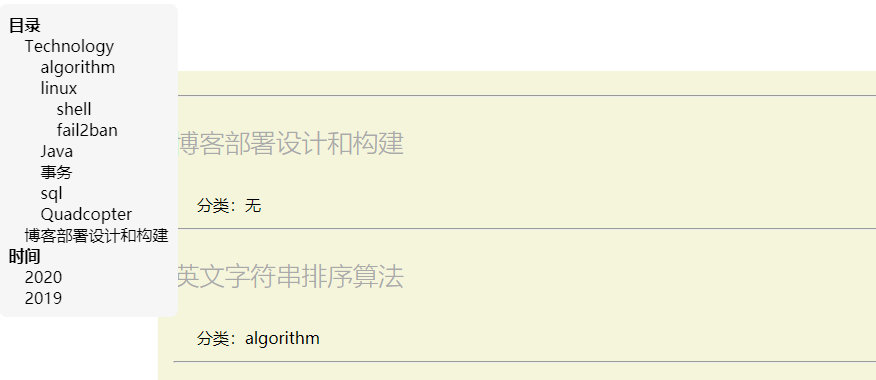
blog pageIndex:
Object | 功能
-
Blog site, the content is static files,all access static,reducing server pressure
博客网站,内容是静态文件,所有访问都是静态,减小服务器压力
-
Operating environment: Linux system, Easier to expand
运行环境:Linux 系统,更容易扩展
-
Monitor folder changes through shell scripts, monitor the modification of markdown files under the folder, and automatically generate corresponding HTML directories and files
通过shell脚本监控文件夹变化,监控文件夹下markdown文件的修改,自动生成对应的HTML目录和文件
Request | 要求
- 不能有较多依赖,尽量简单,并且能够较好地扩展(包括前端js html,后端linux)
- 自动化,除了markdown文件需要人自己上传,其他任何事情包括文章信息更新都自动去完成
markdown 个人认为是一种非常好的写作工具,markdown支持包括图片,表格,简单清晰。
Overall design ideas | 整体设计思路
将写好的markdown文件放入特定文件夹,服务器获得文件信息,将文件转为html文件,并将信息存入文件,使首页能否访问到html文件
- access:用静态访问,先有一个index.html文件作为博客访问首页,有一个bloginfo文件用于存放文章(markdown)信息,然后有一个js文件 用于读取bloginfo中的博客信息,并显示在首页
- monitor: linux 运行一个监控程序,监控markdown文件夹下面的变化,有文件变化,就获得文件信息并将信息更新到bloginfo
- markdown2html: 当有文件新增时,将文件转为HTML格式存入博客访问目录(如有markdown文件新增,通过工具将markdown转为html)
- bloginfo: 生成html文件后,将新增的markdown文章信息更新到bloginfo文件中
Specific plan | 具体实现
- accesspage:静态文件访问形式,nginx实现,文件以 html css js为主,index做导航页,js中执行博客信息处理逻辑
- filemonitor:文档文件以及文件夹的创建删除等动作监控,使用inotify-tools在linux服务器后台监控
- markdown2html:markdown文件转html文件,这里采用markdown2html-converter工具
- bloginfo extraction:文章及文件夹信息整理分类,信息采用json文件存储,用jq对文件读写更新信息
功能具体已经实现,本文主要讲linux服务器文件监控动作以及 markdown 文件转 html文件 实现
Accesspage| 网页
博客的静态访问文件,包括文章信息;作为一个可以访问的网站,静态文件访问相对于动态,压力最小,访问也是较快速的
Index Page | 首页
首页是访问博客首先显示的页面,应该简单明了,不能给人复杂的感觉,主要做导航效果。
首页元素:
以简洁清晰问主,设立设计展示导航栏,文章目录列表,文章标题列表, 翻页器
<div id="indexcontent" style="text-align: center;">
<div id="headerHTML">
<h1>页面头</h1>
</div>
<div id="articleTable">
文章目录列表
</div>
<div id="articlelist">
<h3>文章标题1</h3>
<p>摘要</p>
<p>时间</p>
<h3>文章标题2</h3>
<p>摘要</p>
<p>时间</p>
</div>
<div id="pageTurner">
<h2>
< 1 2 3 4 5 >
</h2> 翻页器
</div>
</div>
Index.js Logic | 首页逻辑处理
主要逻辑应该是在页面加载完毕之后,获取bloginfo 数据,遍历提取文章简要信息,并写入首页目录
window.onload = function () {
//get bloginfo
//foreache 遍历
//write in articleTable
}
按目录归纳文章
//整体逻辑就是 如果 dir=/java/io/ 那么一次创建 java folder 和 io folder
//json遍历的时候,根据key 创建dir 具体实现后续更新
//具体效果可以访问 narule.net/blog
按时间归纳文章:
按时间处理文章首页要把文章的时间排序排好,这里是通过天数排序
var BlogInTime = new Map(); //文章存放处
var timeKey = []; //排序工具
/**
* 时间字符串转 数字
* time yyyy-mm-dd
* 最小单位 日
*/
function string2date(timestr){
var arr = timestr.split('-');
if(arr){
if(arr.length == 1){
return parseInt(arr[0]) * 365;
}
if(arr.length == 2){
return parseInt(arr[0]) * 365 + parseInt(arr[1]) * 30;
}
if(arr.length == 3){
return parseInt(arr[0]) * 365 + parseInt(arr[1]) * 30 + parseInt(arr[2]);
}
}
return 0;
}
/**
* 文章时间处理
*/
function dealTimeInfo(article){
var time = article.md_time;
if(time == '0'){
time = article.create_time;
}
var articles = BlogInTime.get(time);
if(!articles){
articles = [];
if(time.indexOf('-') != -1){
var timenode =
{
id: string2date(time),
date: time
};
timeKey.push(timenode);
}
}
articles.push(article);
BlogInTime.set(time,articles);
}
Filemonitor | 监控
markdown文件如果有变化,需要监听到变化,并且拿到这些markdown文件的信息并存储
有什么工具能够做到监控,也是需要去了解的,查阅资料了解到linux有监听工具inotify-tools可以做到,这里用shell脚本去运行这个程序(后台运行)
inotify-tools | 监控工具
系统环境:Linux Centos7
install | 安装
yum install -y epel-release && yum update 更新资源
yum --enablerepo=epel install inotify-tools 下载安装
use | 使用
inotifywait folder 这是简单表示,实际参数更具具体要求而定,inotifywait表示监听文件夹下的变化 folder就是监听对象
example
如果监听 /home/data/narule/markdown/ 文件夹,之后在/home/data/narule/markdown/创建了java 文件夹
对应的脚本思路:
#!/bin/bash
#设置监听的文件夹位置
SRCDIR=/home/data/narule/markdown/
# 启动监听任务:监听create,delete,modify 事件 -e 表示监听事件输出
inotifywait -mqr --timefmt '%d/%m/%y %H:%M' --format '%T %w %f %e' -e 'create,delete,modify' $SRCDIR | while read DATE TIME DIR FILE EVENT;
# 循环监听逻辑
do
echo ${EVENT}
#获取信息
#文件夹位置 全路径 DIR=/home/data/narule/markdown/
folder=$DIR
#文件名(文件夹也是文件) file=java
file=${$FILE}
#判断事件类型
if [[ $EVENT == "CREATE,ISDIR" ]]; #创建文件夹
then #执行对应动作 这里创建java文件夹,所以在此处执行相关脚本
elif [[ $EVENT == "MODIFY,ISDIR" ]]; #修改文件夹
then
elif [[ $EVENT == "DELETE,ISDIR" ]]; #删除文件夹
then
elif [[ $EVENT == "CREATE" ]]; #创建文件
then
elif [[ $EVENT == "MODIFY" ]]; #修改文件
then
elif [[ $EVENT == "DELETE" ]]; #删除文件
then
fi
done
Markdown2html | 文章转网页格式
markdown文件转为html文件是普遍需求,markdown发布后,将其转为html文件,能够很好的支持网站的访问
很多网站,是直接将markdown文件翻译为html内容,显示在页面,github中也有很多开源的资源,这里采用来自麻省理工?某团队的工具 markdown2html-converter。感谢
markdown2html-converter
系统环境:Linux Centos7
install | 安装
安装前提是你的系统安装了rust动态编程语言
# rust 安装 安装看看是否能够全局运行
curl -sSf https://build.travis-ci.org/files/rustup-init.sh | sh -s -- --default-toolchain=$TRAVIS_RUST_VERSION --profile=minimal -y
# 从github获取项目代码
git clone --depth=50 --branch=v1.1.1 https://github.com/magiclen/markdown2html-converter.git
# 构建
## 配置TARGET
export TARGET=x86_64-unknown-linux-musl
# markdown2html-converter 资源获取
rustup target add $TARGET
cargo test --target $TARGET
# 编译生成可执行文件
make
官网安装教程 https://travis-ci.org/github/magiclen/markdown2html-converter/jobs/709086971
use | 使用
markdown2html-conventer /path/filename.md -o /path/filename.html
Bloginfo extraction| 博客信息提取
文章的信息如何存放,用什么形式存储,会较好理解并且能够解析,这里打算用json数据形式去存储博客的文章信息
**json解析确定后,遇到一些json文件创建和读写的问题,json文件知识包含网站文章的信息,本人觉得不应该运行一个java或者其他什么程序去做这件事,这没必要,浪费资源;最后我在网上找到了jq工具,他可以很好的解析json文件并配合shell修改json文件 jq文档 **
jq | json解析工具
系统环境:Linux Centos7
install | 安装
yum install -y jq
文档:https://github.com/stedolan/jq/wiki/Cookbook
jq 的使用命令比较多,本人也是刚了解
use | 使用
解析文件
cat file.json | jq . 或者 jq . file.json
前提file.json 内容是正确的json格式,才好正常解析
example
author.json:
{
"name": "rule",
"age": "2",
"from": "china"
}
执行 cat author.json | jq ' ."age" = "5" ' 后控制台输出:
{
"name": "rule",
"age": "5",
"from": "china"
}
执行 cat author.json | jq ' del(."name") ' 后控制台输出:
{
"age": "5",
"from": "china"
}
通过这些命令,就可以处理博客文章信息存储到json文件中,完全自动更新
编写好脚本文件后,给文件加权限使可执行
chmod + x markdown_monitor.sh
后台启动
nohup ./markdown_monitor.sh > /var/log/monitor.log 2>&1 &
就可以监控运作了,上传markdown文件,就自动更新HTML页面到博客
END | 结尾
文件已经放在 github中,拿下来直接可用,唯一需要修改的地方就是文件夹目录
这里整体讲下思路和实现,有些实现并没在本文中写出来,文中目前主要介绍有 后端文件监控及自动将markdown文件转为html文件
转载请注明出处!
2020-07-25 吴楠予