本章来记录一下Eclipse安装hadoop插件、配置MapReduce环境并新建一个MapReduce工程的过程
0.现有环境:
Eclipse(Windows 本地系统的)
云服务器(已经配置好了Hadoop开发环境和集群)
1.安装插件:
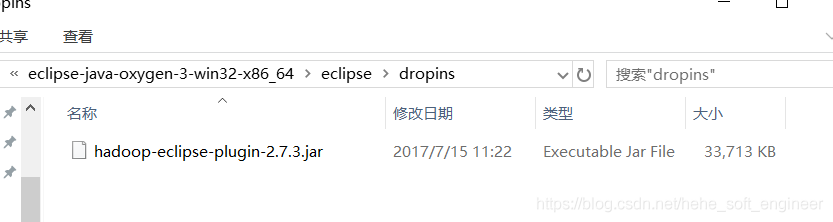
hadoop-eclipse-plugin-2.7.3.jar
地址:https://pan.baidu.com/s/1BaAOQkZaY4RvUPuBPVlgJg 提取码:067u
将插件复制到eclipse目录下的dropins目录
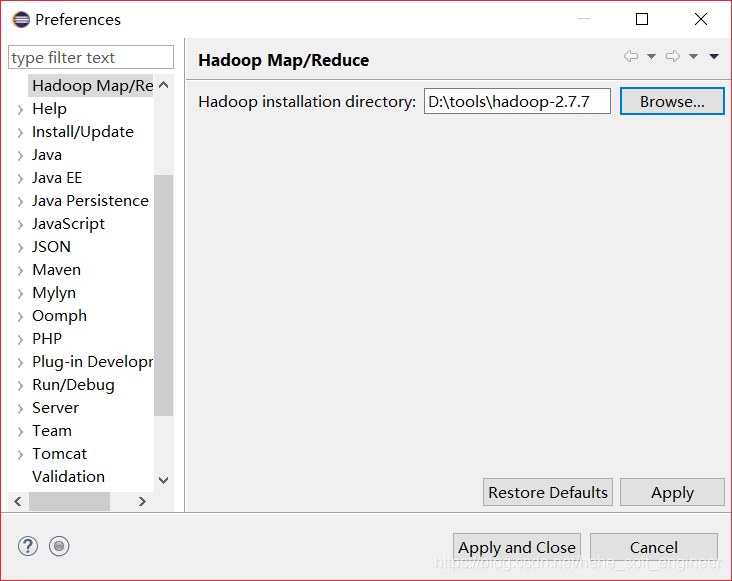
2.配置MapReduce环境:
配置好Hadoop插件后,接下来配置开发环境,连接到Hadoop集群,相关步骤如下:
(1)增加Map/Reduce功能区
①增加Map/Reduce功能区(1)
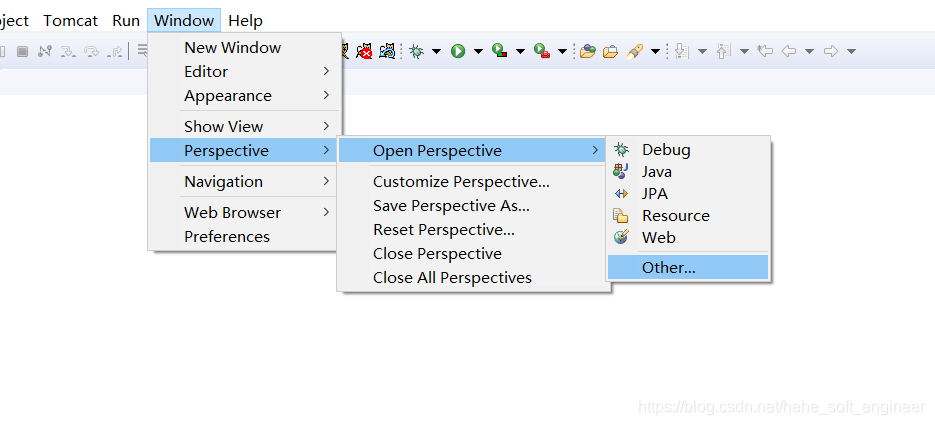
②增加Map/Reduce功能区(2)
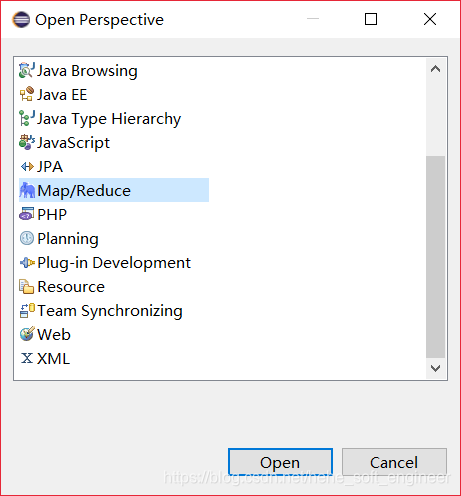
(2)增加Hadoop集群的连接
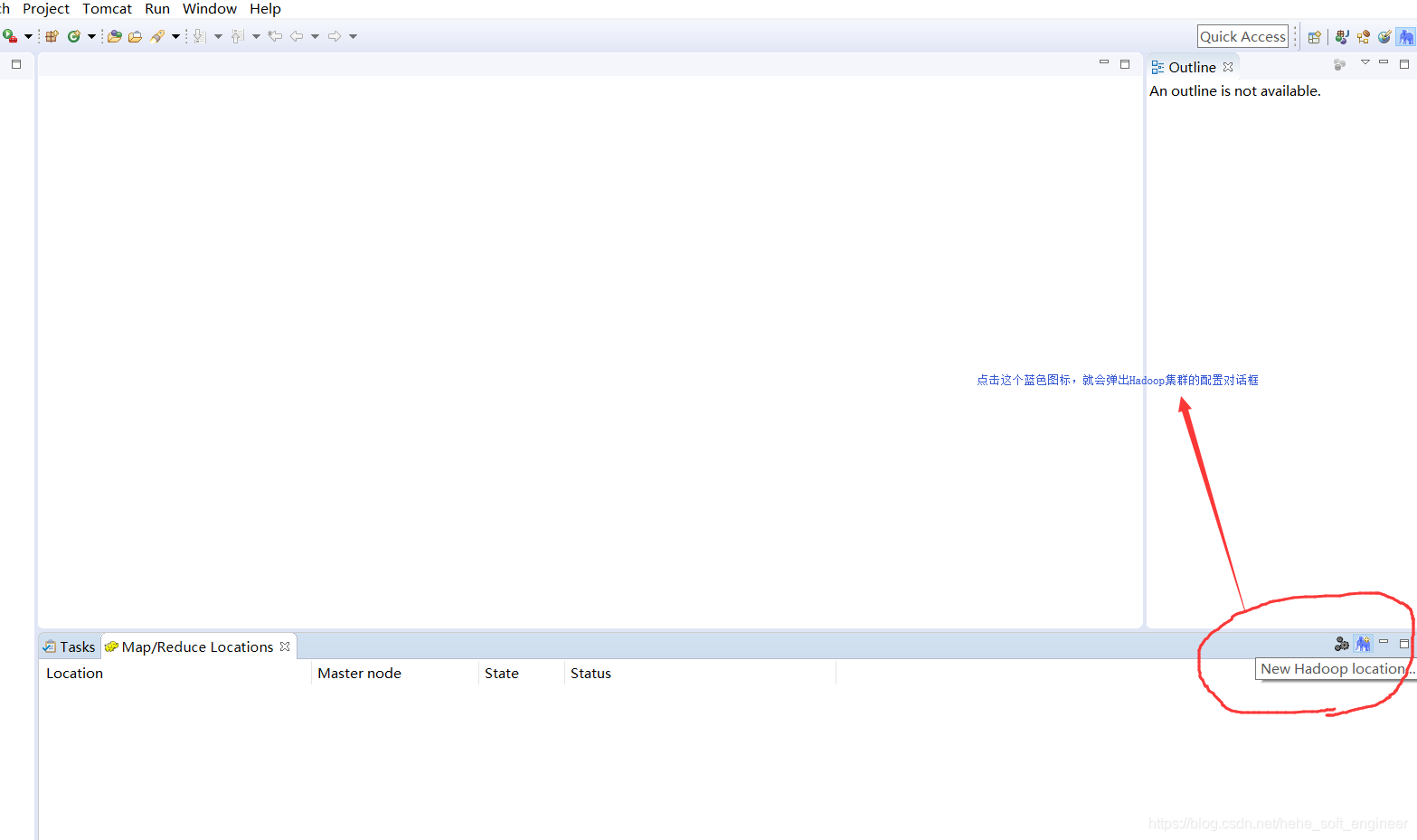
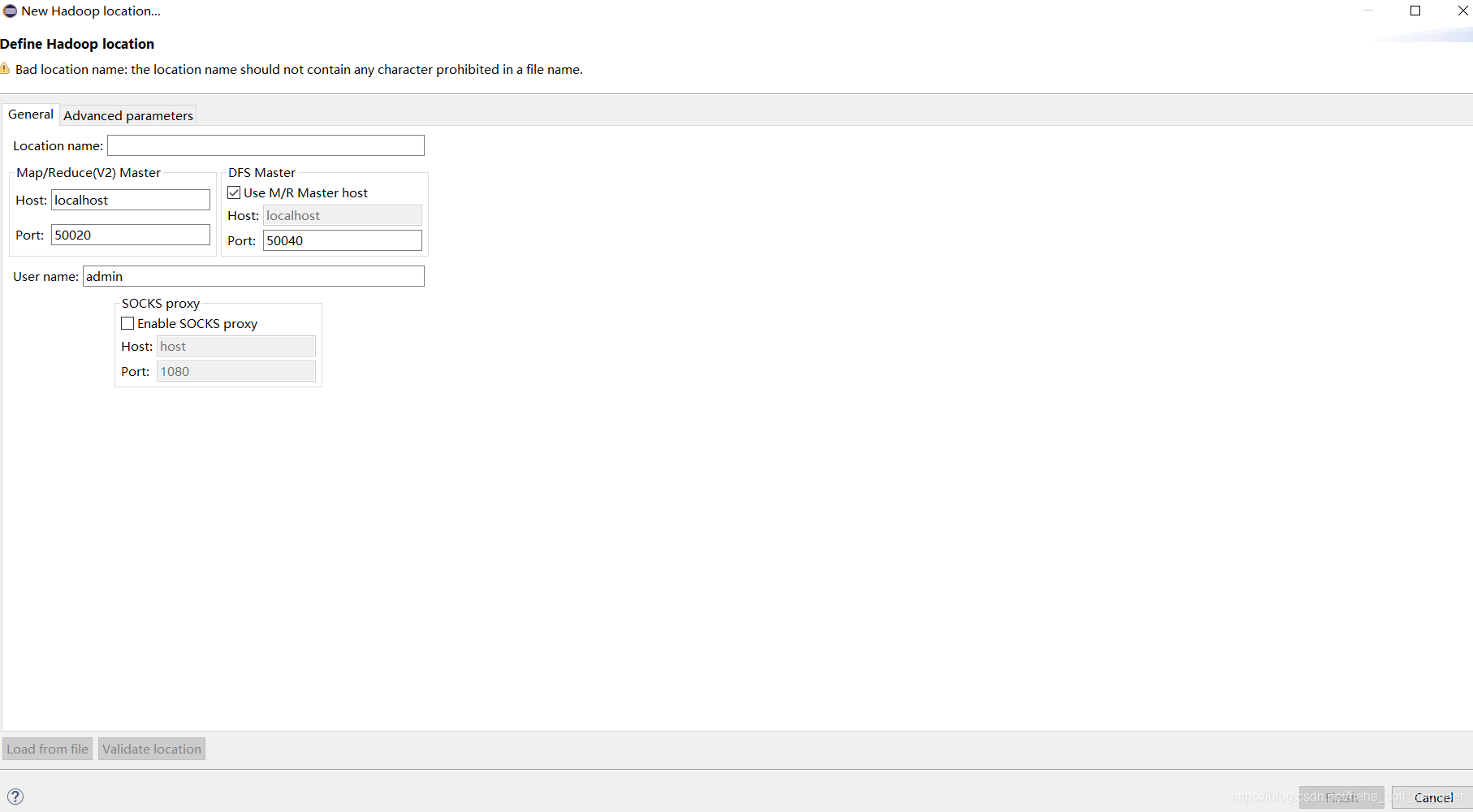
相关的连接配置信息有:
①Location name:命名新建的Hadoop连接,此处我设置的是HadoopCluster
②Map/Reduce(V2)Master:填写Hadoop集群的ResourceManager的IP和端口,从以前配置Hadoop集群的yarn-site.xml找
③DFS Master:填写Hadoop集群的NameNode的IP和端口,从以前配置的core-site.xml找
配置如下:
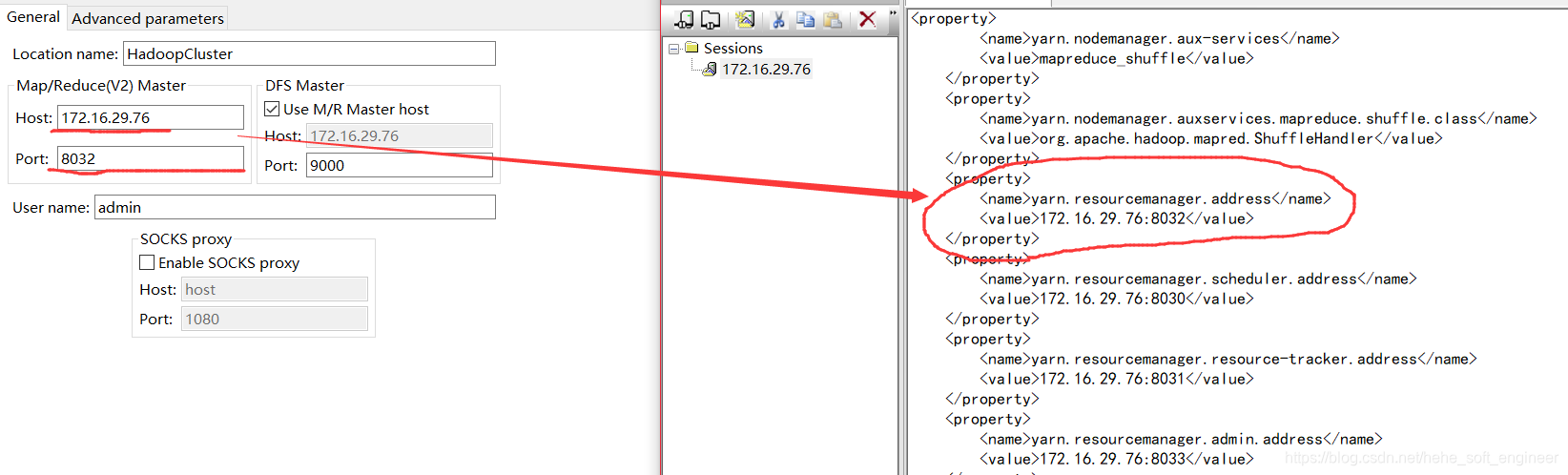
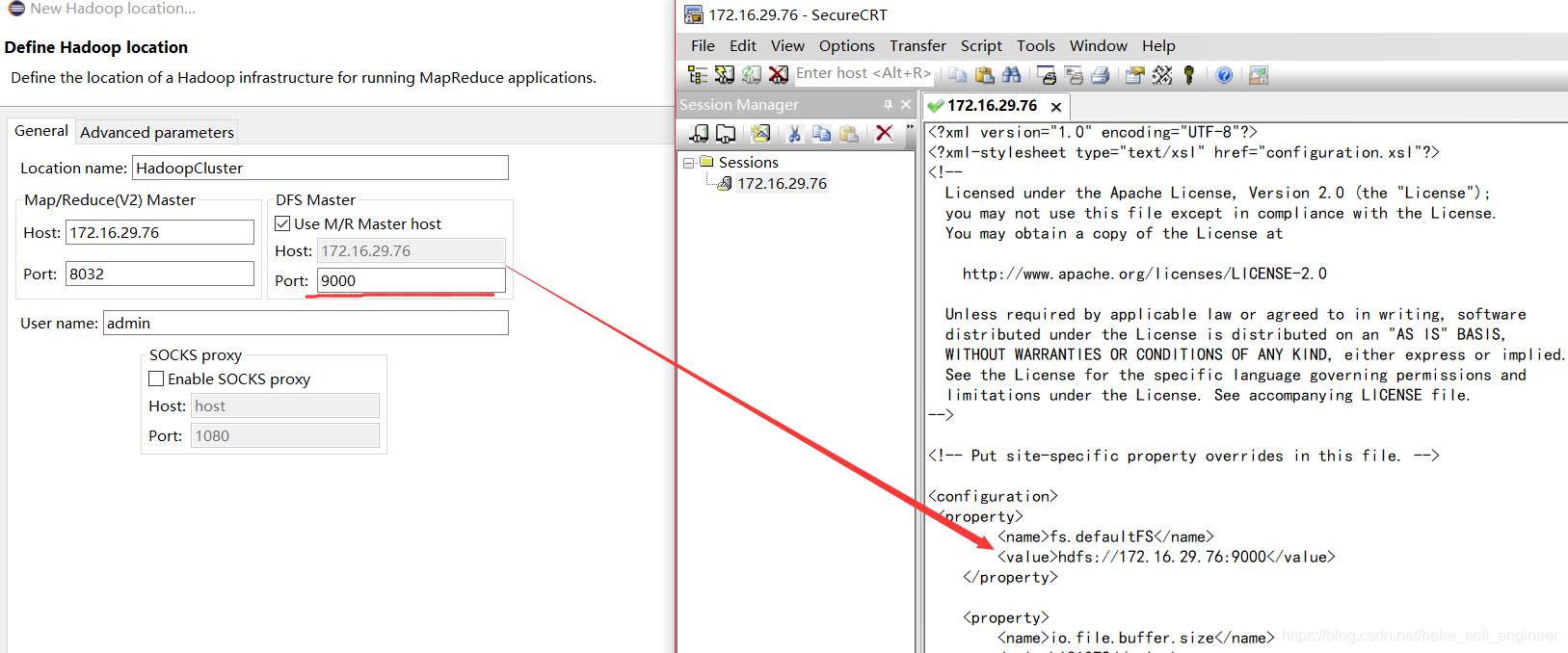
finish配置完成

(3)浏览HDFS上的目录及文件
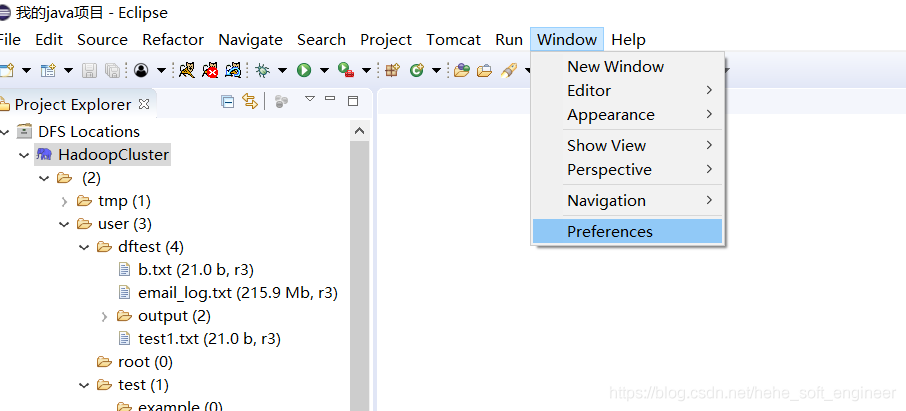
配置完成Hadoop集群的连接信息后,就可以在Eclipse界面浏览HDFS上的目录和文件了,还可以通过鼠标来进行文件操作
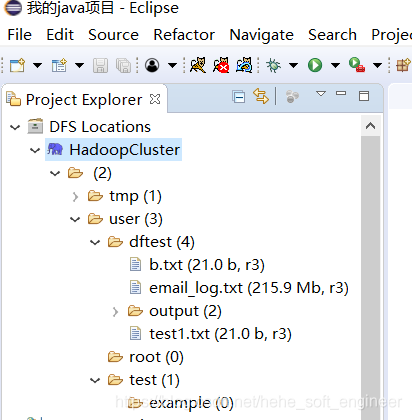
需要注意的是,执行操作后,需要刷新HDFS列表,从而获得文件目录的最新状态。
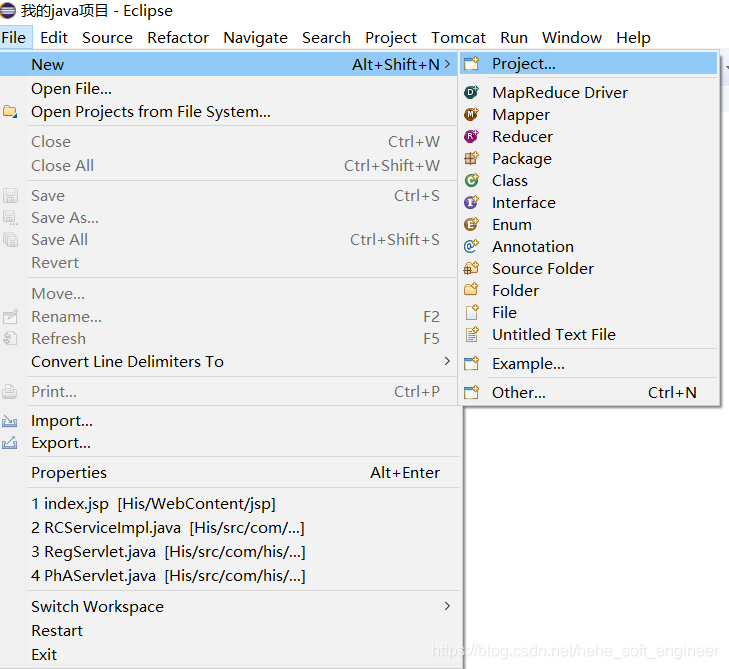
3.新建MapReduce工程
本部分将在Eclipse建立MapReduce工程MemberCount,大体按照下面四个步骤进行:
(1)导入MapReduce运行依赖的jar包
首先将虚拟环境中的hadoop包导入到本地环境下,导入过程如下:
(2)创建MapReduce工程
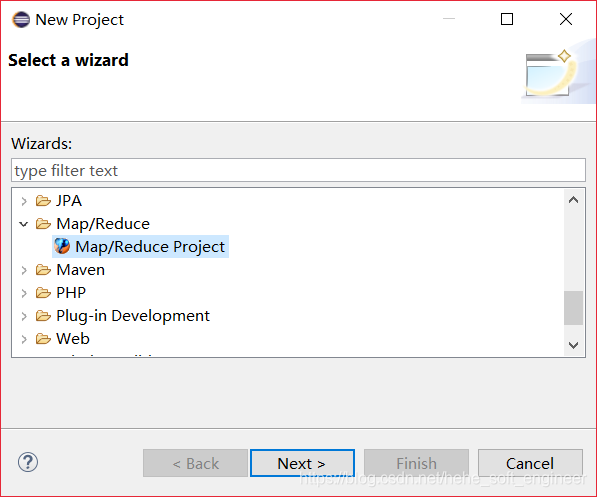
(3)在MapReduce Project的界面创建工程
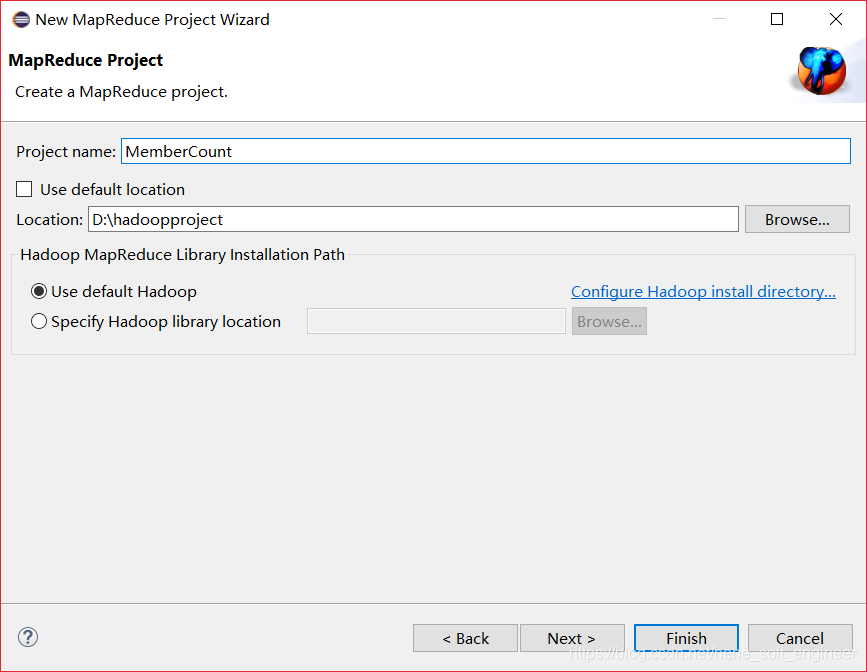
(4)查验是否创建好工程
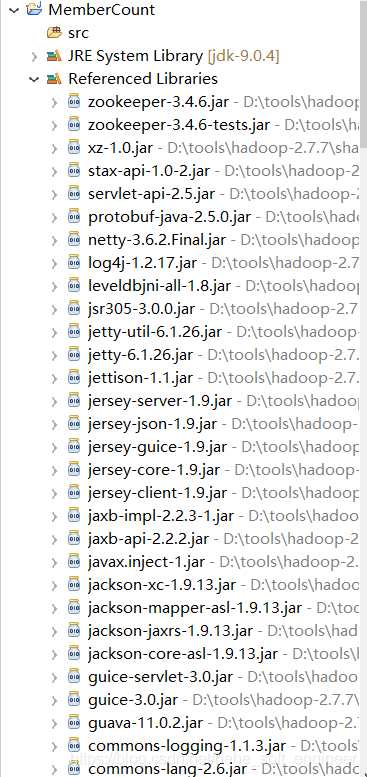
jar包导入成功,配置安装完成 ^_^ 。